










想要构建自己的Agent,你一定无法避免和LangChain打交道。
所以这篇文章将给大家介绍一下LangChain,知道它是什么,怎么用,基于LangChain能做了,并且它有什么问题。
LangChain的文字资料和视频资料挺多的,我就不重复了,我会在文末添加相关的资料,有兴趣的朋友自行学习。
我相信很多人是因为不了解LangChain,不了解Agent,才来看我的文章,而且大部分人时间也很宝贵,没有这么时间花几天时间来系统化学习,而且主要也不确定学习LangChain对自己的工作有没有帮助。
所以我尽量用最简单的语言把事情说情况。
我们要构建一个自己的AI系统(Agent)
假设我们要构建一个自己的问答系统,问答系统需要使用我们私有的数据库。
我们应该怎么做,我们可以先考虑一个成本最低的POC方案。
-
使用最强的大语言模型ChatGPT的openapi
-
自己用Python写一个代码,基于openai为基础,然后自己做知识库问答,自己多文件切片和向量化,自己做RAG
思路是这个思路,但是全都自己写,除非你是大牛,还是有些吃力的,而且随着项目的复杂度增加,整个项目的架构将会非常关键。
这时候可能有杠精要说,老师你就用GPTs或其他的一些Agent平台就可以无代码完成一个自己知识库的问答系统了。
没错,但是这里只是想大家都懂的问答系统作为案例进行举例,因为你用友LangChain可以构建比这个复杂的多的系统,比如你可以基于LangChain构建自己的Agent平台。
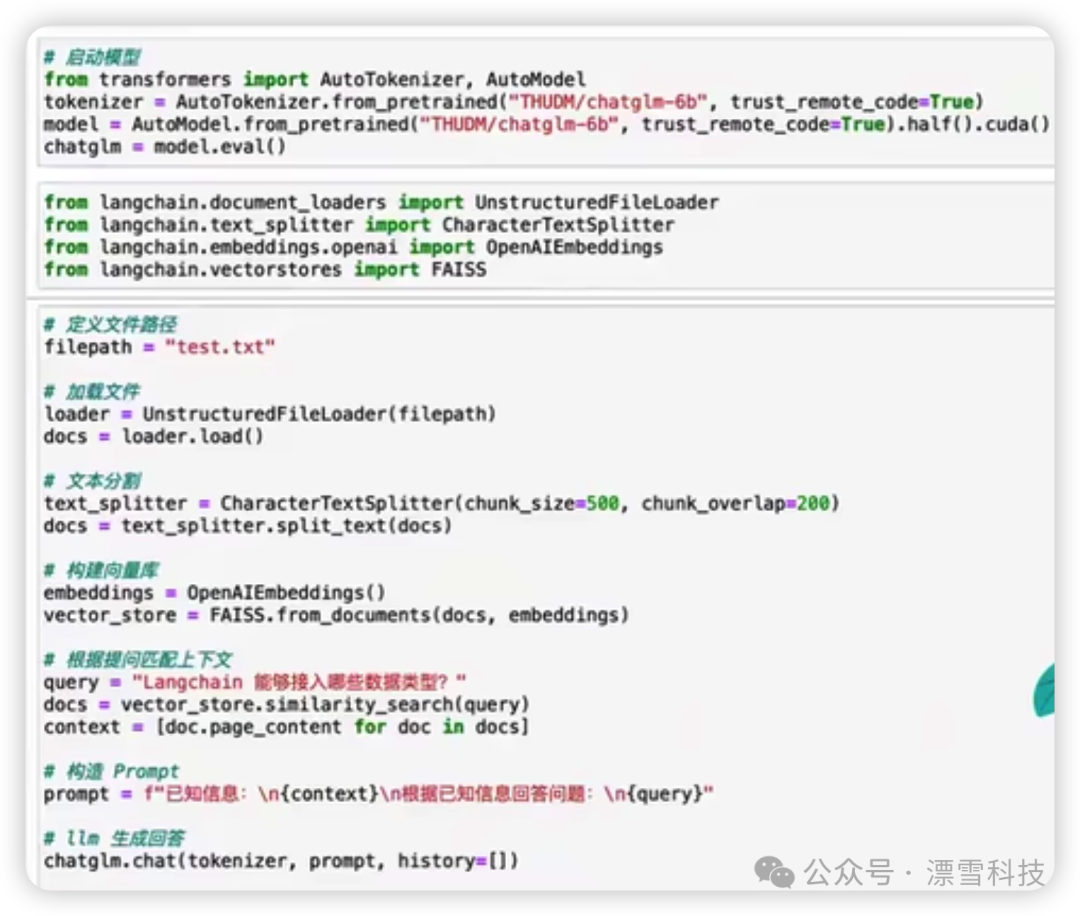
这里给出一个例子,使用可以本地部署的大语言模型ChatGLM-6b,和本地知识库test.txt,简单的十几行代码就完成了我们要做的问答系统,分别是加载文件、文件内容切割、向量化,然后根据向量化的内容和Query进行Prompt组装,就是这么简单。
当然引入LangChain也有带来很多副作用,开发过低代码的朋友肯定知道,虽然使用图形化的方式可以降低系统开发的复杂度,但是同时也降低了系统的性能,原来最精简的代码只要3分钟的执行时长可能会被拉长到数倍。
LangChain核心功能
好了,有了信心之后,我们学习一下LangChain有哪些能力。
模板 PromptTemplate
`1from langchain.prompts import PromptTemplate 2 3prompt = PromptTemplate( 4 input_variables=["product"], 5 template="What is a good name for a company that makes {product}?", 6) 7print(prompt.format(product="colorful socks"))`
输出:What is a good name for a company that makes colorful socks?
通过PromptTemplate就可以给Prompt添加变量了,很简单吧
链 Chain
`1from langchain.prompts import PromptTemplate 2from langchain.llms import OpenAI 3 4llm = OpenAI(temperature=0.9) 5prompt = PromptTemplate( 6 input_variables=["product"], 7 template="What is a good name for a company that makes {product}?", 8) 9 10from langchain.chains import LLMChain 11chain = LLMChain(llm=llm, prompt=prompt) 12 13chain.run("colorful socks")`
输出:# -> ‘\n\nSocktastic!’
这样就使用了LangChain的Chain了,还是很简单吧。
代理Agent
为了用好代理,需要理解以下概念:
- 工具(tools): 执行特定任务的功能。这可以是: Google 搜索、数据库查找、 Python REPL、其他链。工具的接口目前是一个函数,预计将有一个字符串作为输入,一个字符串作为输出。
`1from langchain.agents import load_tools 2from langchain.agents import initialize_agent 3from langchain.agents import AgentType 4from langchain.llms import OpenAI 5 6# 首先,让我们加载用于控制代理的语言模型。 7llm = OpenAI(temperature=0) 8 9# 接下来,让我们加载一些要使用的工具。请注意,“llm-math”工具使用 LLM,因此我们需要将其传入。 10tools = load_tools(["serpapi", "llm-math"], llm=llm) 11 12# 最后,让我们用工具、语言模型和我们想要使用的代理类型来初始化一个代理。 13agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) 14 15# 现在让我们测试一下! 16agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")`
输出:
> Entering new AgentExecutor chain…
I need to find the temperature first, then use the calculator to raise it to the .023 power.
Action: Search
Action Input: “High temperature in SF yesterday”
Observation: San Francisco Temperature Yesterday. Maximum temperature yesterday: 57 °F (at 1:56 pm) Minimum temperature yesterday: 49 °F (at 1:56 am) Average temperature …
Thought: I now have the temperature, so I can use the calculator to raise it to the .023 power.
Action: Calculator
Action Input: 57^.023
Observation: Answer: 1.0974509573251117
Thought: I now know the final answer
Final Answer: The high temperature in SF yesterday in Fahrenheit raised to the .023 power is 1.0974509573251117.
Finished chain.
加入Agent之后,是不是有点智能的味道了,它知道自己去搜索,观察,使用工具,最后形成结论。
内存Memory
到目前为止,我们经历过的所有工具和代理都是无状态的的。
但是通常,您可能希望链或代理具有某种“内存”概念,以便它可以记住关于其以前的交互的信息。
最简单明了的例子就是在设计一个聊天机器人时——你想让它记住之前的消息,这样它就可以利用这些消息的上下文来进行更好的对话。
ConversationChain 这是一种“短期记忆”。
输入:
`1from langchain import OpenAI, ConversationChain 2llm = OpenAI(temperature=0) 3# 让我们看一下如何使用这个链(设置 verbose=True,这样我们就可以看到提示符)。 4conversation = ConversationChain(llm=llm, verbose=True) 5output = conversation.predict(input="Hi there!") 6print(output) 7`
输出
`1> Entering new chain... 2Prompt after formatting: 3The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. 4Current conversation: 5Human: Hi there! 6AI: 7> Finished chain. 8' Hello! How are you today?'`
输入
`1output = conversation.predict(input="I'm doing well! Just having a conversation with an AI.") 2print(output)`
输出
`1> Entering new chain... 2Prompt after formatting: 3The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know. 4Current conversation: 5Human: Hi there! 6AI: Hello! How are you today? 7Human: I'm doing well! Just having a conversation with an AI. 8AI: 9> Finished chain. 10" That's great! What would you like to talk about?"`
LangChain专门对于聊天模型进行了封装
聊天模型
LangChain 中当前支持的消息类型是
AIMessage,HumanMessage,SystemMessage, 和ChatMessage,ChatMessage接受任意角色参数。大多数时候,您只需要处理HumanMessage,AIMessage, 和SystemMessage.
`1from langchain.chat_models import ChatOpenAI 2from langchain.schema import ( 3 AIMessage, 4 HumanMessage, 5 SystemMessage 6) 7chat = ChatOpenAI(temperature=0) 8chat([HumanMessage(content="Translate this sentence from English to French. I love programming.")]) 9# -> AIMessage(content="J'aime programmer.", additional_kwargs={})`
您还可以为 OpenAI 的 gpt-3.5-turbo 和 gpt-4型号传递多条消息。
`1messages = [ 2 SystemMessage(content="You are a helpful assistant that translates English to French."), 3 HumanMessage(content="Translate this sentence from English to French. I love programming.") 4] 5chat(messages) 6# -> AIMessage(content="J'aime programmer.", additional_kwargs={})`
您可以更进一步,使用generate为多组消息生成完成。
这将返回一个带有附加message参数的 LLMResult。
`1batch_messages = [ 2 [ 3 SystemMessage(content="You are a helpful assistant that translates English to French."), 4 HumanMessage(content="Translate this sentence from English to French. I love programming.") 5 ], 6 [ 7 SystemMessage(content="You are a helpful assistant that translates English to French."), 8 HumanMessage(content="Translate this sentence from English to French. I love artificial intelligence.") 9 ], 10] 11result = chat.generate(batch_messages) 12 13result 14# -> LLMResult(generations=[[ChatGeneration(text="J'aime programmer.", generation_info=None, message=AIMessage(content="J'aime programmer.", additional_kwargs={}))], [ChatGeneration(text="J'aime l'intelligence artificielle.", generation_info=None, message=AIMessage(content="J'aime l'intelligence artificielle.", additional_kwargs={}))]], llm_output={'token_usage': {'prompt_tokens': 71, 'completion_tokens': 18, 'total_tokens': 89}})`
有点聊天历史的感觉
同样的,聊天也有链 ,也有聊天代理
索引 Indexes
还记得我们一开始举的例子吗,我们要怎么切分、存储、检索自己的文档呢?
加载文件后有三个主要步骤:
-
将文档分割成块
-
为每个文档创建嵌入
-
在向量库中存储文档和嵌入
`1# 加载文档 2documents = loader.load() 3# 将文档切块 4from langchain.text_splitter import CharacterTextSplitter 5text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) 6texts = text_splitter.split_documents(documents) 7# 然后,我们将选择要使用的嵌入 8from langchain.embeddings import OpenAIEmbeddings 9embeddings = OpenAIEmbeddings() 10# 最后,我们创建用作索引的向量存储 11from langchain.vectorstores import Chroma 12db = Chroma.from_documents(texts, embeddings) 13# 这就是创建索引的过程,然后,我们在一个检索接口中公开这个索引 14retriever = db.as_retriever() 15# 像以前一样,我们创建一个链,并使用它来回答问题 16qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever) 17query = "What did the president say about Ketanji Brown Jackson" 18qa.run(query)`
默认情况下,LangChain 使用 Chroma 作为向量存储来索引和搜索嵌入
好了,你已经学完了LangChain最核心的功能,接下来可以自己动手了。
LangChain官网文档
LangChain中文教程
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









