







往期文章链接目录
文章目录
Bagging v.s. Boosting:
Bagging:
Leverages unstable base learners that are weak because of overfitting.
Boosting:
Leverages stable base learners that are weak because of underfitting.
XGBoost
Learning Process through XGBoost:
- How to set a objective function.
- Hard to solve directly, how to approximate.
- How to add tree structures into the objective function.
- Still hard to optimize, then have to use greedy algorithms.
Step 1. How to set an objective function
Suppose we trained
K
K
K trees, then the prediction for the ith sample is
y
^
i
=
∑
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
\hat{y}_i = \sum_{k=1}^K f_k(x_i), f_k \in \mathcal{F}
y^i=k=1∑Kfk(xi),fk∈F
where
K
K
K is the number of trees,
f
f
f is a function in the functional space
F
\mathcal{F}
F, and
F
\mathcal{F}
F is the set of all possible CARTs.
The objective function to be optimized is given by
obj
=
∑
i
n
l
(
y
i
,
y
^
i
)
+
∑
k
=
1
K
Ω
(
f
k
)
\text{obj} = \sum_i^n l(y_i, \hat{y}_i) + \sum_{k=1}^K \Omega(f_k)
obj=i∑nl(yi,y^i)+k=1∑KΩ(fk)
The first term is the loss function and the second term controls trees’ complexity. We see the undefined terms in this objective function are the loss function
l
l
l and model complexity
Ω
(
f
i
)
\Omega (f_i)
Ω(fi). Functions
f
i
f_i
fi are what we need to learn, each containing the structure of the tree and the leaf scores.
we use an additive strategy to build the model. That is, fix what we have learned, and add one new tree at a time. This is called Additive Training.
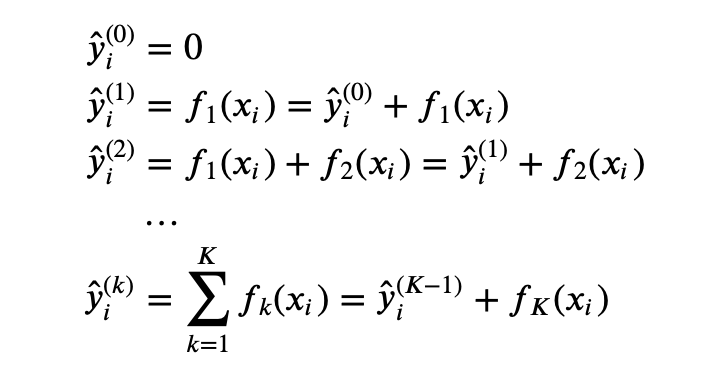
Note that given x i x_i xi, the prediction y ^ i ( K ) = y ^ i ( K − 1 ) + f K ( x i ) \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i) y^i(K)=y^i(K−1)+fK(xi), where the term y ^ i ( K − 1 ) \hat{y}_i^{(K-1)} y^i(K−1) is known and only f K ( x i ) f_K(x_i) fK(xi) is unknown.
Now, we can rewrite the objective function as
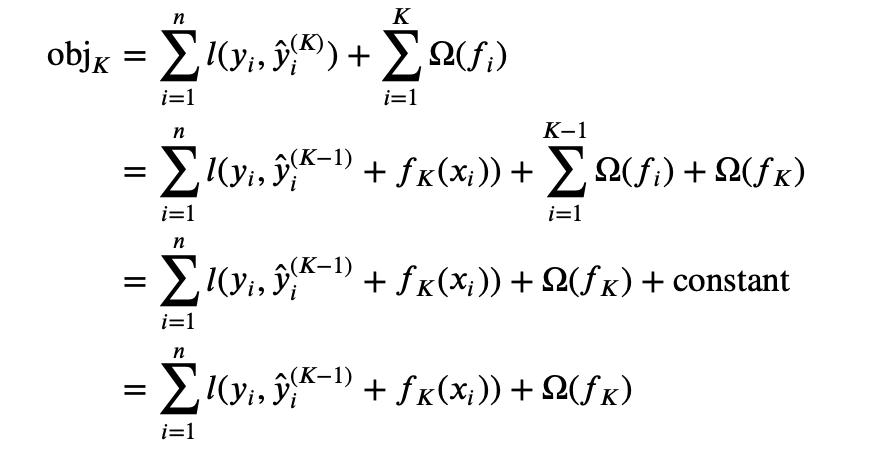
Step 2. Hard to solve directly, how to approximate
If the loss function is the MSE, then the objective function has a nice form. But for a general loss function, it is hard to optimize directly. Therefore, we need to approximate it. Here, we use second order Taylor approximation
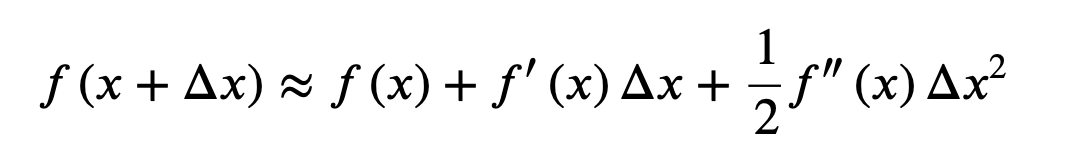
So we can re-write the objective function as
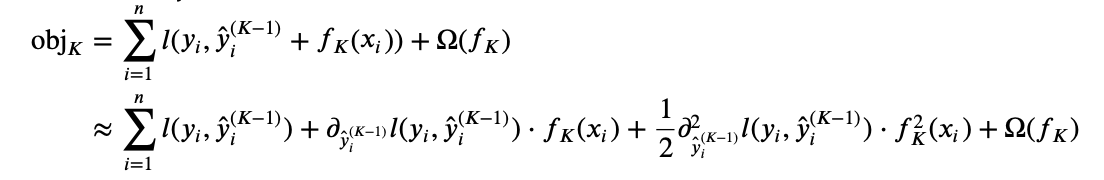
If we define constant term
g
i
g_i
gi,
h
i
h_i
hi as
g
i
=
∂
y
^
i
(
K
−
1
)
l
(
y
i
,
y
^
i
(
K
−
1
)
)
f
i
=
∂
y
^
i
(
K
−
1
)
2
l
(
y
i
,
y
^
i
(
K
−
1
)
)
g_i = \partial_{\hat{y}_i^{(K-1)}} l(y_i, \hat{y}_i^{(K-1)}) \\ f_i = \partial_{\hat{y}_i^{(K-1)}}^2 l(y_i, \hat{y}_i^{(K-1)})
gi=∂y^i(K−1)l(yi,y^i(K−1))fi=∂y^i(K−1)2l(yi,y^i(K−1))
Also, since previous
K
−
1
K-1
K−1 trees are fixed, we have
∑
i
=
1
n
l
(
y
i
,
y
^
i
(
K
−
1
)
)
\sum_{i=1}^n l(y_i, \hat{y}_i^{(K-1)})
∑i=1nl(yi,y^i(K−1)) fixed. Then we can write the objective function as
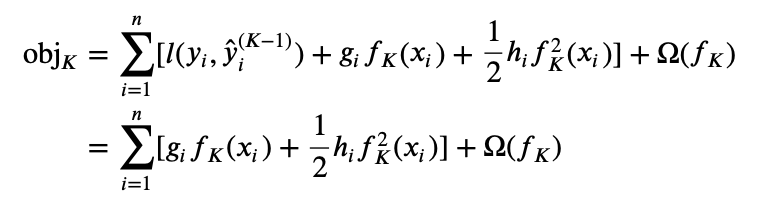
Now, all previous trees’ information is stored in terms
g
i
g_i
gi and
h
i
h_i
hi. That’s how the
K
K
Kth tree is related to previous trees. Our new objective function now is
obj
K
=
∑
i
=
1
n
[
g
i
f
K
(
x
i
)
+
1
2
h
i
f
K
2
(
x
i
)
]
+
Ω
(
f
K
)
\text{obj}_K = \sum_{i=1}^n [g_if_K(x_i) + \frac{1}{2}h_if_K^2(x_i)] + \Omega(f_K)
objK=i=1∑n[gifK(xi)+21hifK2(xi)]+Ω(fK)
The unknown at this point are
f
K
f_K
fK and
Ω
(
f
K
)
\Omega(f_K)
Ω(fK).
Step 3. How to add tree structures into the objective function
Redefine a tree:
- Define I j = { i ∣ q ( x i ) = j } I_j = \{i|q(x_i)=j\} Ij={i∣q(xi)=j} to be the set of indices of data points assigned to the 𝑗-th leaf.
- T T T is the number of leaves.
- q ( x i ) q(x_i) q(xi) is which leaf the i i i-th sample is assigned to. Term q ( x ) q(x) q(x) defines the tree structure.
- w q ( x i ) w_{q(x_i)} wq(xi) is the score of the assigned leaf.
- In XGBoost, we define the complexity as Ω ( f ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^T w_j^2 Ω(f)=γT+21λ∑j=1Twj2
Now the revised objective function is
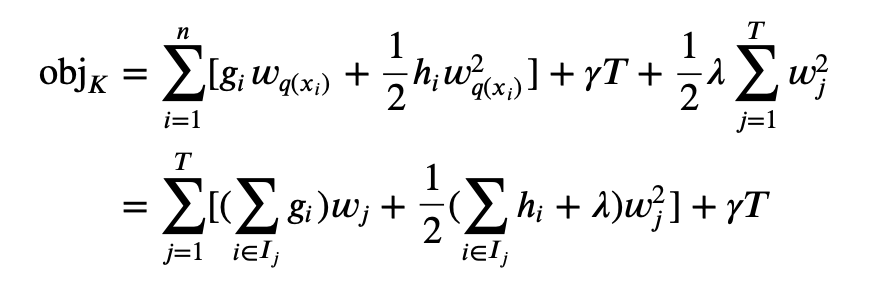
Define
G
j
=
∑
i
∈
I
j
g
i
G_j = \sum_{i\in I_j} g_i
Gj=∑i∈Ijgi and
H
j
=
∑
i
∈
I
j
h
i
H_j = \sum_{i\in I_j} h_i
Hj=∑i∈Ijhi constants. The the objective function is
obj
K
=
∑
j
=
1
T
[
G
j
w
j
+
1
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
\text{obj}_{K} = \sum^T_{j=1} [G_jw_j + \frac{1}{2} (H_j+\lambda) w_j^2] +\gamma T
objK=j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
Right now, the only unknown is
w
j
w_j
wj, which is independent respect to other terms. Take the derivative and set it to zero, we have
w
j
=
−
G
j
H
j
+
λ
w_j = -\frac{G_j}{H_j+\lambda}
wj=−Hj+λGj
Then the objective function achieve its minimum at
obj
K
=
−
1
2
∑
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
\text{obj}_K = -\frac{1}{2} \sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T
objK=−21j=1∑THj+λGj2+γT
Step 4. Still hard to optimize, then have to use greedy algorithms
For any tree structure, we are now able to find the minimum value of the objective function. Ideally we would brute force all possible tree structures and pick the one with the minimum objective function. However, this is impossible in practice and we use greedy algorithm instead. When we build decision trees, we use entropy to calculate the information gain. Now we are still going to use information gain, but the formula changes to
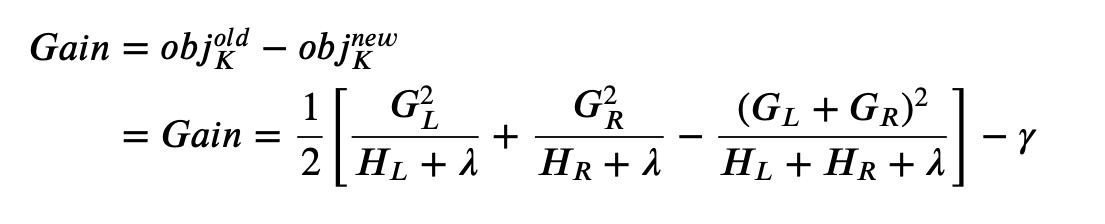
where L L L is the left leaf and R R R is the right leaf.
Reference:
https://xgboost.readthedocs.io/en/latest/tutorials/model.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









