







随着生成式大语言模型应用的日益广泛,其输入输出模态受限的问题日益凸显,成为制约技术进一步发展的瓶颈。为突破这一局限,本文聚焦于研究多模态信息的协同交互策略,旨在探索一种能够统一理解与生成的多模态模型构建方法。在此基础上,深入研究可控的混合多模态信息生成技术,力求揭示多模态语义层次间的隐含关系,从而实现对生成内容的精准编辑。此外,本文还致力于构建具备强时空一致性的多模态混合输出生成式模型,以期实现时序一致的长视频生成,并在复杂的音视频内容理解与生成任务中进行实践应用验证,为推动多模态大模型技术的全面发展贡献力量。
1.生成式模型输入输出模态受限
对于现有的大语言模型,一方面,其大多局限于关注于某种单一模态信息的处理,而缺乏真正「任意模态」的理解;另一方面,其都关注于多模态内容在输入端的理解,而不能以任意多种模态的灵活形式输出内容。
text -> text :GPT-3.5, LLaMa, 百川
text -> image :Dalle3,Midjourney
text -> audio :sunoAI
text + image -> video : 可灵AI
text + image -> text: GPT-4, 文心一言
NExT-GPT:实现输入到输出「模态自由」, NUS华人团队开源
What Makes Multimodal Learning Better than Single (Provably)
从泛化角度解释多模态优越性的第一个理论处理,制定了一个多模态学习框架,该框架在实证文献中得到了广泛的研究,以严格地理解为什么多模态优于单模态,因为前者可以获得更好的隐空间表示。
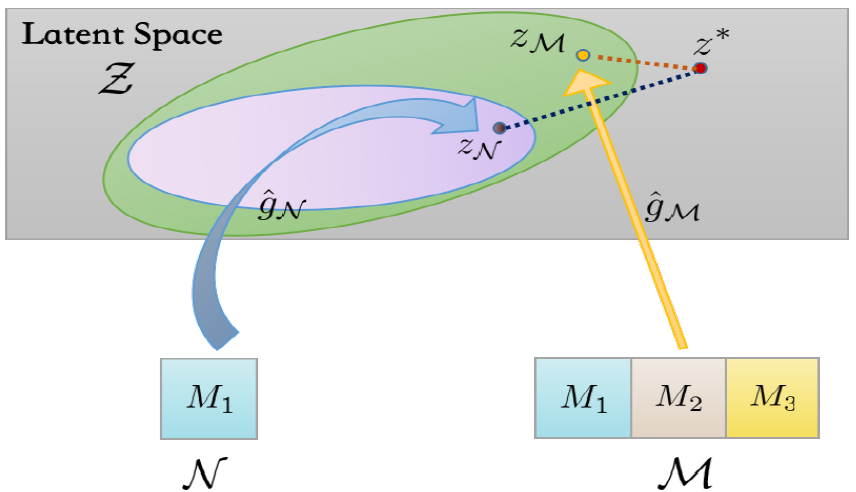
本文基于一种经典的多模态学习框架,即无缝进行潜空间学习(Latent Space Learning)与任务层学习(Task-specific Learning)。具体地,首先将异构数据编码到一个统一潜空间 Z \mathcal{Z} Z,对应的映射函数族为 G \mathcal{G} G,要寻找的最优的映射是 g ∗ \mathcal{g}^* g∗。接着,潜空间的表示再经过任务层的映射被用于指定任务中,映射的函数族为 H \mathcal{H} H,其中最优映射为 h ∗ \mathcal{h}^* h∗。
2.多模态信息协同交互策略
在深度学习中,多模态(multimodal)融合策略用于集成来自不同模态的数据,以提升模型的性能和泛化能力。多模态数据可以包括文本、图像、音频、视频、传感器数据等,通过有效融合这些不同类型的数据,能够从中提取更丰富和全面的信息。以下是几种常见的多模态融合策略:
-
早期融合(Early Fusion)
-
晚期融合(Late Fusion)
-
中期融合(Intermediate Fusion)
-
混合融合(Hybrid Fusion)
-
基于注意力机制的融合(Attention-based Fusion)
-
基于图神经网络的融合(Graph Neural Networks-based Fusion)
-
联合学习(Joint Learning)
3.统一理解与生成的多模态模型构建方法, 探索统一理解与生成的多模态模型构建方法
LaVIT 将文本和视觉两种模态以统一的形式表示,以便复刻 LLM 的学习方法——下一个 token 预测,模型如图 所示。

给定一对图像和文本,图像被分词成离散 token,并与文本 token 连接形成多模态序列。然后,LaVIT 在统一的生成目标下进行优化
视觉分词器:将非语言图像转换为 LLM 可以理解的输入。视觉分词器接收预训练的视觉编码器的视觉特征,并输出一系列具有类似词汇高级语义的离散视觉 token。
通过精心设计的分词器,视觉输入可以与文本 token 集成,形成一个多模态序列,然后在统一的自回归训练目标下输入到 LLM 中。
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
AnyGPT,一种 any-to-any 的多模态大语言模型。采用离散的表征统一处理语音、文本、图像和音乐等多种不同模态信号。文章构建了一个多模态,以文本为中心的数据集 AnyInstruct-108k。该数据集利用生成模型合成,是一个大规模多模态指令数据集。

使用多模态分词器 (tokenizer),将原始的多模态数据,比如图像和语音,压缩成离散语义 token 的序列。再使用多模态解分词器 (de-tokenizer),将离散语义 token 的序列转换回原始模态数据。离散表征的好处是能够过滤掉高频的,特定于模态的感知信息,同时保留基本的低频语义信息。架构层面,继承现有的 LLM 架构,无需任何修改。同时允许直接应用现有的 LLM 工具,从而提高训练和推理的效率。AnyGPT 使用 LLaMA-2-7B作为基座模型,它在 2TB 的文本标记上进行了预训练。除了重塑 embedding matrix 和预测层外,其余语言模型保持不变。
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
4.构建强时空一致性的多模态混合输出生成式模型,多模态语义层次的隐含关系
时空一致性(Spatiotemporal Coherency)指的是空间和时间上的连贯性或一致性。在多个领域,如深度学习、神经科学、计算机视觉等,这一概念都有重要的应用。
在计算机视觉领域中,时空连贯性常用于视频分析、运动检测、显著性检测等任务。例如,在显著性检测中,研究者们利用时空连贯性来识别视频中的显著区域,这些区域在时间和空间上都与周围区域存在显著差异。这有助于实现更准确的视频分析和理解。
通过语义分割视频和生成视频音频语音字幕来优先考虑时空一致性。
INTERNVIDEO2: SCALING FOUNDATION MODELS FORMULTIMODAL VIDEO UNDERSTANDING
数据处理的创新:时空一致性的重要性
在数据处理方面,InternVideo2强调了时空一致性的重要性。通过语义分割视频并生成视频-音频-语音字幕,改进了视频和文本之间的对齐。
-
视频剪辑的语义分割
为了保持时空一致性,使用AutoShot模型代替传统的SceneDet滤镜来分割视频剪辑。AutoShot基于时间语义变化而不是像素差异来预测边界,从而生成语义完整的剪辑,避免混入不一致的上下文。
-
视频、音频和语音字幕的生成与融合
在MVid数据集中,视频来自多个来源,包括YouTube和其他匿名来源,以提高数据集的多样性。对于视频数据集,首先保留超过2秒的剪辑。对于超过30秒的视频剪辑,如果剪辑中的片段来自同一镜头,则随机选择一个30秒的片段。此外,还自动为MVid的视觉、音频和语音生成字幕,然后使用LLM校正并融合它们,以便训练使用。
多模态融合(Multimodal Fusion)是指结合来自不同模态(如视觉、听觉、文本等)的数据,以提升信息处理和理解能力的技术方法。多模态数据通常具有不同的物理性质和信息特征,通过融合这些多模态信息,可以获得更全面和准确的理解。这种融合过程可以发生在数据层、特征层和决策层:
- 数据层融合:直接对不同模态的数据进行融合。
- 特征层融合:提取不同模态的数据特征后进行融合。
- 决策层融合:对不同模态的处理结果进行融合。
多模态融合的应用场景
多模态融合技术在各个领域有着广泛的应用,以下是一些典型的应用场景:
-
图文生成与理解
- 图像描述生成:根据图像内容生成自然语言描述。
- 文本到图像生成:根据文本描述生成对应的图像。
-
语音和视觉结合的情感分析
通过结合语音和视觉数据,识别用户的情感状态,提高情感分析的准确性。- …
5.实现时序一致的长视频生成。在复杂音视频内容理解与生成任务中进行应用验证
大模型CoDi,具有任意输入和输出图、文、声音、视频4种模态的能力。
从声音、文字、图像到视频,所有模态被彻底打通,如同人脑一般,实现了真正意义上的任意输入,任意输出。
无论是单模态生成单模态(下图黄)、多模态生成单模态(下图红)、还是多模态生成多模态(下图紫),只要指定输入和输出的模态,CoDi就能理解并生成想要的效果:
只需告诉大模型,想要“一只玩滑板的泰迪熊”,并输入一张照片+一段声音:

模型设计二阶段:
阶段一:组合条件训练,给每个模态都打造一个潜在扩散模型(LDM),进行组合训练。
阶段二:进一步增加生成的模态数量。
扩散模型(Diffusion Model)是一种生成模型,最近在图像生成、视频生成、语音合成等领域取得了显著的进展。与传统的生成对抗网络(GAN)和变分自编码器(VAE)不同,扩散模型通过逐步将噪声添加到数据并反转这一过程来生成新样本。
Any-to-Any Generation via Composable Diffusion
总结
1.多模态信息处理能力:选取合适的基座模型(LaVIT,LLaMA-2)。此类模型需要能够理解和处理多种模态的信息,包括但不限于文本、图像、音频和视频。这要求模型具有跨模态的交互能力,能够解析并融合来自不同模态的数据。
2.大规模多模态数据集:构建一个包含多模态数据的大型数据集(AnyGPT AnyInstruct-108k),这些数据集应覆盖广泛的模态组合和复杂的交互场景。例如,可以构建包含多轮对话、图像描述、音频解说和视频剪辑等多种模态信息的数据集,用于模型的预训练和微调。
3.统一的多模态表示:参考AnyGPT、所采用的离散序列建模方法,需要一个统一的表示框架来整合和处理不同模态的数据。这种表示方式应能够捕获各模态之间的内在联系,并实现跨模态信息的有效转换和传递。
4.可控的混合多模态信息生成方法:设计一种能够精确控制多模态信息生成的方法(CoDi 二阶段),允许用户在生成过程中指定所需的模态和内容。这要求模型能够理解并响应用户的多模态输入,并生成相应的、符合用户期望的输出。
5.强时空一致性的生成能力:参考InternVideo2构建具有强时空一致性的生成模型,确保生成的长视频在时序和空间上保持连贯性和一致性。这要求模型能够处理复杂的时序信息和空间布局,以确保生成的视频内容在逻辑和视觉上都是合理的。
















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











