







参考:
[1] VAE1
[2] https://lilianweng.github.io/posts/2018-08-12-vae/
[3] VAE Code
进食顺序
1 VAE
1.1 VAE的直观理解
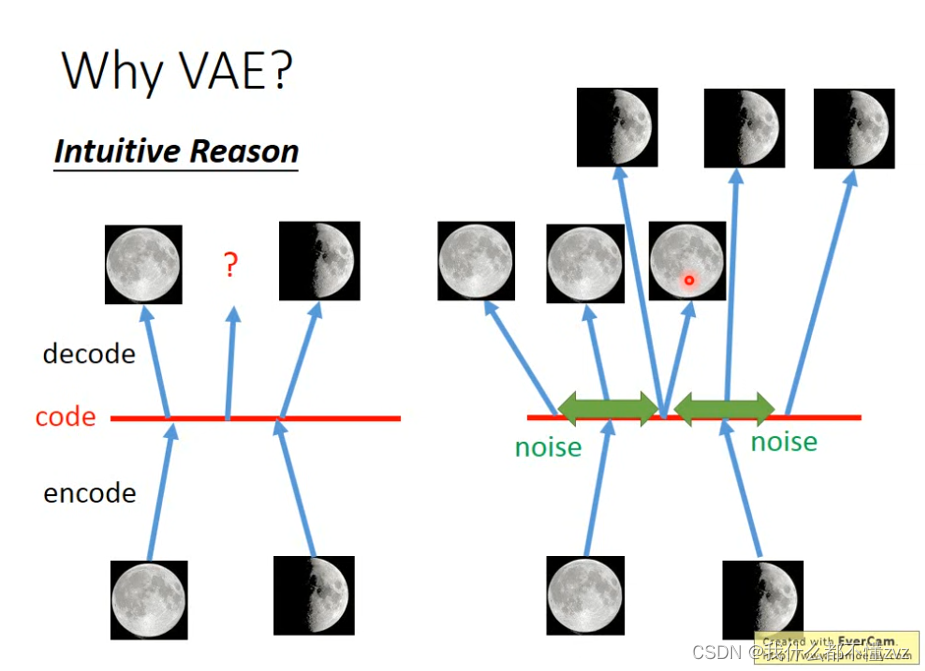
最直观的图莫过于[李宏毅ML18讲]以上这幅图。 对于AutoEncoder模型,模型其实是在拟合一个identity function,也就是对于每个输入
x
x
x,在隐空间(latant space)都有唯一的隐变量
z
z
z与之对应,那么生成的
x
′
x'
x′同理可知也是和
x
、
z
x、z
x、z唯一对应的。
那么问题来了,在采样过程中,由于隐变量 z z z所在的分布是连续的,我们的数据集 { x } \{x\} {x}又是有限的,所以不可能将所有的 z z z都和 x 或 x ′ x或x' x或x′对应上。而神经网络通常又是非线性的,对于一些从来没有见过的隐变量,也不可能通常线性关系去推导它对应的 x ′ x' x′是啥样的(比如上图中,满月和半月之间的 z z z对应的月亮大概率不是一个 2 3 \frac{2}{3} 32月亮,因为non-linear的原因)
而VAE机智的地方在于,它让每一个 x x x都对应一个随机分布,而不再是对应一个隐变量,那么上面提到的 2 3 \frac{2}{3} 32个月亮,可能就是两个分布的重叠部分,那么可以根据权值或者什么方式得到相应的月亮图。总之,观测数据 x x x不再是对应于一个值,而是对应于一个分布,我们在这个分布里采样,就可以得到不同的图像,此时模型就变成了生成模型。
1.2 VAE数学推导
1.2.1 混合高斯模型角度理解VAE(李宏毅ML课的说法)
混合高斯模型(mixture-gaussian model)可以简单定义为: 任何分布 p ( x ) p(x) p(x)都可以由多个不同均值和方差的高斯模型进行加权和进行拟合。(类似于傅里叶定理:不同信号都可以由多个正弦信号去进行拟合一样)
假设
z
z
z表示第几个高斯分布,则
p
(
x
)
=
∫
z
p
(
z
)
p
(
x
∣
z
)
d
z
p(x) = \int_zp(z)p(x|z)dz
p(x)=∫zp(z)p(x∣z)dz
其中
p
(
z
)
p(z)
p(z)可以理解为第z个高斯分布的权值(概率分布),
x
∣
z
∼
N
(
μ
z
,
Σ
z
)
x|z \sim N(\mu_z,\Sigma_z)
x∣z∼N(μz,Σz), 则
p
(
x
∣
z
)
p(x|z)
p(x∣z)为高斯分布。这是从混合高斯模型的角度来理解的VAE。
总结来说就是:我们要预测 p ( x ) p(x) p(x),但是模型很难直接预测出 p ( x ) p(x) p(x),因为分布未知并且分布复杂。但是我们可以通过预测很多个高斯分布去拟合 p ( x ) p(x) p(x)。VAE就是先预测 p ( z ) p(z) p(z),再去预测 p ( x ∣ z ) p(x|z) p(x∣z),从而预测出最终目标。
1.2.2 隐空间角度理解以及ELBO(变分下界)
这个 z z z又叫隐变量,为什么要用隐变量:我们可以理解为 p ( x ) p(x) p(x)很难直接求出,但是我们可以先求 p ( z ) p(z) p(z),然后通过 p ( z ) p(z) p(z)去求得 p ( x ) p(x) p(x),这样就方便多了,其中 p ( z ) p(z) p(z)可以是任意我们自定义的分布,VAE中使用的是 p ( z ) = N ( z ; 0 , I ) p(z)=N(z;0,I) p(z)=N(z;0,I)。
我们可以通过边际化来表示
p
(
x
)
p(x)
p(x)
p
(
x
)
=
∫
z
p
(
x
,
z
)
d
z
p(x) = \int_zp(x,z)dz
p(x)=∫zp(x,z)dz
又根据乘法公式:
p
(
x
,
z
)
=
p
(
x
)
p
(
z
∣
x
)
=
p
(
z
)
p
(
x
∣
z
)
p(x,z)=p(x)p(z|x)=p(z)p(x|z)
p(x,z)=p(x)p(z∣x)=p(z)p(x∣z)。根据贝叶斯公式,又有:
p
(
z
∣
x
)
=
p
(
x
∣
z
)
p
(
z
)
p
(
x
)
p(z|x) = \frac{p(x|z)p(z)}{p(x)}
p(z∣x)=p(x)p(x∣z)p(z)
其中
p
(
z
∣
x
)
p(z|x)
p(z∣x)叫后验概率;
p
(
x
∣
z
)
p(x|z)
p(x∣z)叫似然概率(通过z我们似乎可以预测出x);
p
(
z
)
p(z)
p(z)叫先验概率(我们自定义);
p
(
x
)
p(x)
p(x)叫证据(evidence)
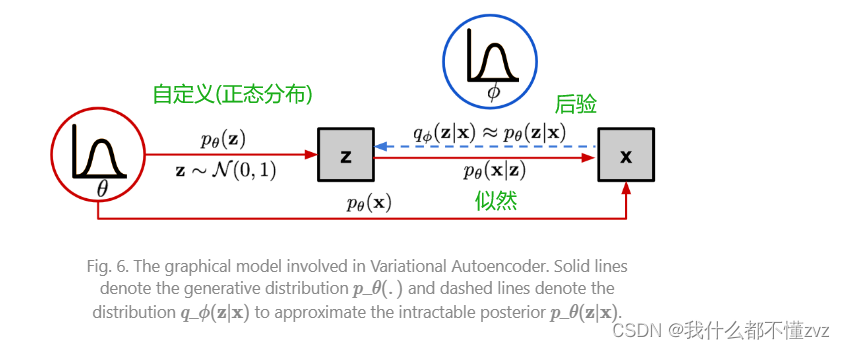
根据最大似然理论,我们要极大化:
l
o
g
p
(
x
)
=
l
o
g
∫
z
p
θ
(
x
,
z
)
d
z
=
l
o
g
∫
z
q
ϕ
(
z
∣
x
)
p
θ
(
x
,
z
)
q
ϕ
(
z
∣
x
)
d
z
=
l
o
g
E
z
∼
q
ϕ
(
z
∣
x
)
[
p
θ
(
x
,
z
)
q
ϕ
(
z
∣
x
)
]
≥
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
,
z
)
q
ϕ
(
z
∣
x
)
]
=
∫
z
q
ϕ
(
z
∣
x
)
l
o
g
p
θ
(
x
,
z
)
d
z
−
∫
z
q
ϕ
(
z
∣
x
)
l
o
g
q
ϕ
(
z
∣
x
)
d
z
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
,
z
)
]
−
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
q
ϕ
(
z
∣
x
)
]
=
L
(
q
,
θ
)
\begin{aligned} logp(x) &= log\int_zp_\theta(x,z)dz\\ &=log\int_zq_\phi(z|x)\frac{p_\theta(x,z)}{q_\phi(z|x)}dz\\ &=logE_{z\sim q_\phi(z|x)}[\frac{p_\theta(x,z)}{q_\phi(z|x)}]\\ &\geq E_{z\sim q_\phi(z|x)}[log\frac{p_\theta(x,z)}{q_\phi(z|x)}]\\ &=\int_zq_\phi(z|x)logp_\theta(x,z)dz-\int_zq_\phi(z|x)logq_\phi(z|x)dz\\ &= E_{z\sim q_\phi(z|x)}[logp_\theta(x,z)] - E_{z\sim q_\phi(z|x)}[logq_\phi(z|x)]\\ &= L(q,\theta) \end{aligned}
logp(x)=log∫zpθ(x,z)dz=log∫zqϕ(z∣x)qϕ(z∣x)pθ(x,z)dz=logEz∼qϕ(z∣x)[qϕ(z∣x)pθ(x,z)]≥Ez∼qϕ(z∣x)[logqϕ(z∣x)pθ(x,z)]=∫zqϕ(z∣x)logpθ(x,z)dz−∫zqϕ(z∣x)logqϕ(z∣x)dz=Ez∼qϕ(z∣x)[logpθ(x,z)]−Ez∼qϕ(z∣x)[logqϕ(z∣x)]=L(q,θ)
其中:
- 第二行上下同乘一个数,结果不变;
- 第四行是根据詹森不等式;
- 我们称 L ( q , θ ) L(q,\theta) L(q,θ)为ELBO(evidence lower bound,也是因为 p ( x ) p(x) p(x)为evidence),我们可以i通过最大化ELBO,去近似最大化似然函数。
我们刚刚用乘法定理得到: p ( x , z ) = p ( x ) p ( z ∣ x ) = p ( z ) p ( x ∣ z ) p(x,z)=p(x)p(z|x)=p(z)p(x|z) p(x,z)=p(x)p(z∣x)=p(z)p(x∣z),我们可以代入进去来看看ELBO的本质是什么:
1) 先代入
p
(
x
,
z
)
=
p
(
x
)
p
(
z
∣
x
)
p(x,z)=p(x)p(z|x)
p(x,z)=p(x)p(z∣x)
L
(
q
,
θ
)
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
(
x
)
]
+
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
z
∣
x
)
]
−
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
q
ϕ
(
z
)
]
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
(
x
)
]
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
θ
(
z
∣
x
)
)
=
l
o
g
p
(
x
)
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
θ
(
z
∣
x
)
)
\begin{aligned} L(q,\theta) &= E_{z\sim q_\phi(z|x)}[logp(x)]+E_{z\sim q_\phi(z|x)}[logp_\theta(z|x)]-E_{z\sim q_\phi(z|x)}[logq_\phi(z)] \\ &=E_{z\sim q_\phi(z|x)}[logp(x)] - KL(q_\phi(z|x)||p_\theta(z|x))\\ &= logp(x) - KL(q_\phi(z|x)||p_\theta(z|x)) \end{aligned}
L(q,θ)=Ez∼qϕ(z∣x)[logp(x)]+Ez∼qϕ(z∣x)[logpθ(z∣x)]−Ez∼qϕ(z∣x)[logqϕ(z)]=Ez∼qϕ(z∣x)[logp(x)]−KL(qϕ(z∣x)∣∣pθ(z∣x))=logp(x)−KL(qϕ(z∣x)∣∣pθ(z∣x))
所以我们可以得到(移位):
l
o
g
p
(
x
)
=
L
(
q
,
θ
)
+
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
θ
(
z
∣
x
)
)
logp(x) = L(q,\theta)+ KL(q_\phi(z|x)||p_\theta(z|x))
logp(x)=L(q,θ)+KL(qϕ(z∣x)∣∣pθ(z∣x))
我们可以发现,当我们将最小化KL散度让其接近于0,也就是使得
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)与
p
(
z
∣
x
)
p(z|x)
p(z∣x)分布靠近,那么我们就等近似将对数似然看作是ELBO。而
q
ϕ
q_\phi
qϕ可以看作是encoder,我们使用NN来拟合
p
θ
(
z
∣
x
)
p_\theta(z|x)
pθ(z∣x)
2) 代入
p
(
x
,
z
)
=
p
(
z
)
p
(
x
∣
z
)
p(x,z)=p(z)p(x|z)
p(x,z)=p(z)p(x∣z)
L
(
q
,
θ
)
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
(
z
)
]
+
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
−
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
q
ϕ
(
z
∣
x
)
]
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
\begin{aligned} L(q,\theta) &= E_{z\sim q_\phi(z|x)}[logp(z)]+E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)]-E_{z\sim q_\phi(z|x)}[logq_\phi(z|x)]\\ &= E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)]- KL(q_\phi(z|x)||p(z)) \end{aligned}
L(q,θ)=Ez∼qϕ(z∣x)[logp(z)]+Ez∼qϕ(z∣x)[logpθ(x∣z)]−Ez∼qϕ(z∣x)[logqϕ(z∣x)]=Ez∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))
其中第一项可以认为模型的decoder,既根据隐变量
z
z
z得到
x
x
x的概率分布对数似然最大化;第二项是最大化负的KL散度,既最小化KL散度,既使得
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)与
p
(
z
)
p(z)
p(z)更接近。这里可以认为我们希望encoder预测出来的
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)和我们自定义的
p
(
z
)
p(z)
p(z)越接近越好,此处KL散度相当于约束项。
至此我们可以发现ELBO的本质:(小小总结一下)
- 由第一项我们可以知道,我们可以用 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)来替代 p ( z ∣ x ) p(z|x) p(z∣x),训练模型去拟合该分布,这样对数似然可以等价于ELBO。为什么要替代 p ( z ∣ x ) p(z|x) p(z∣x),因为根据隐空间角度,我们不好直接求 p ( x ) p(x) p(x),所以设置隐变量 p ( x ) = ∫ z p ( z ) p ( x ∣ z ) d z p(x)=\int_zp(z)p(x|z)dz p(x)=∫zp(z)p(x∣z)dz,我们用模型去拟合后一项。
- 由第二项我们可以知道,ELBO实际包含了 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z)和 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),正好对应了decoder和encoder,并且我们还要尽量让 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x)去拟合 p ( z ) p(z) p(z),这也是一项约束项,否则我们只有重建损失( E z ∼ q ϕ ( z ∣ x ) [ l o g p θ ( x ∣ z ) ] E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)] Ez∼qϕ(z∣x)[logpθ(x∣z)])就变回AE了。
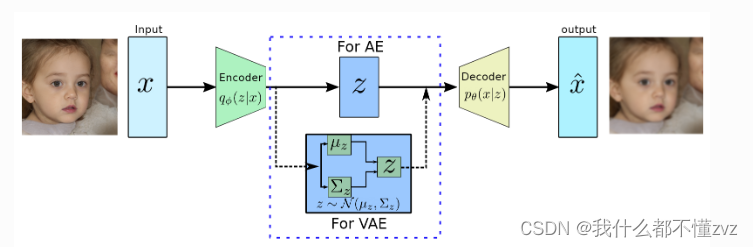
1.2.3 Encoder
VAE里假设
z
z
z是一个高斯变量,那么后验分布
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)也是高斯分布,我们不知道的是均值和方差,那么我们只要让encoder去拟合均值和方差,我们便可以知道该后验分布了。既
q
ϕ
(
z
∣
x
)
=
N
(
μ
ϕ
(
x
)
,
Σ
ϕ
(
x
)
)
q_\phi(z|x)=N(\mu_\phi(x),\Sigma_\phi(x))
qϕ(z∣x)=N(μϕ(x),Σϕ(x))
从这里我们也可以看到,
x
x
x对应的是一个高斯分布,而不是一个确定的
z
z
z值。
那么我们是如何衡量拟合的好坏的呢,根据上边的ELBO式子,我们有:
L
=
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
L = E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)]- KL(q_\phi(z|x)||p(z))
L=Ez∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))
也就是通过KL散度来衡量其与
p
(
z
)
p(z)
p(z)的拟合近似程度。
两个高斯分布的KL散度是有已知公式的,直接带入即可:
K
L
(
N
(
μ
ϕ
,
Σ
ϕ
)
∣
∣
N
(
0
,
1
)
)
=
1
2
(
σ
ϕ
2
+
μ
ϕ
−
1
−
l
o
g
σ
ϕ
2
)
KL(N(\mu_\phi,\Sigma_\phi)||N(0,1))=\frac{1}{2}(\sigma_\phi^2+\mu_\phi-1-log\sigma^2_\phi)
KL(N(μϕ,Σϕ)∣∣N(0,1))=21(σϕ2+μϕ−1−logσϕ2)
这也就是我们的分布约束项,直觉上来说,当 μ ϕ = 0 , Σ ϕ = 1 \mu_\phi=0,\Sigma_\phi=1 μϕ=0,Σϕ=1时,该KL散度会最小。
参数重整化(Reparameterization Trick)
我们已知
z
z
z是随机变量,既
z
z
z是从分布
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)随机采样出来的,那么对于输入同一个
x
x
x,可能每次采样的
z
z
z都是不一样的,所以这样是不可以梯度反传的。
这里使用参数重整化,既用一个确定值和随机值来代替一整个随机值,看下图
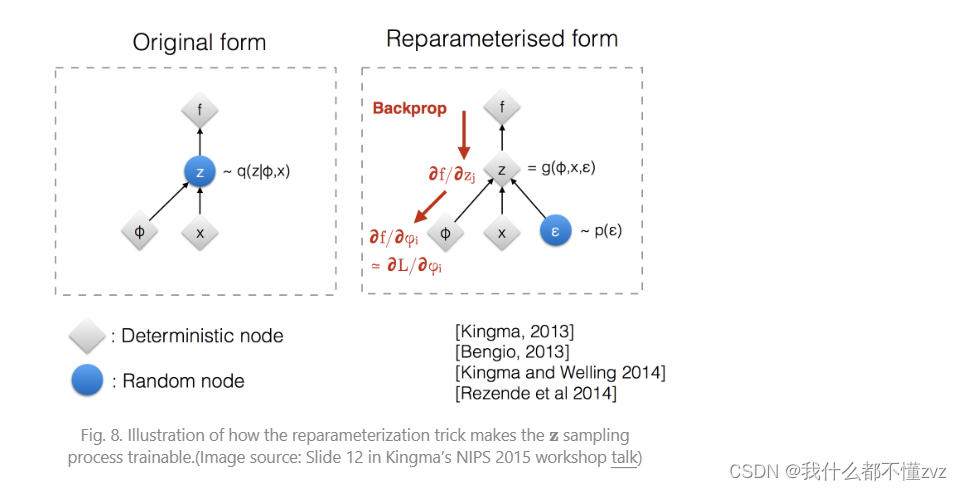
这里我们每次传入
x
x
x都生成均值和方差,这是确定的(因为传入的x不变,通过NN函数拟合当然是确定的),这里我们从
N
(
0
,
1
)
N(0,1)
N(0,1)的正态分布中采样噪声,这是随机的,然后我们通过乘方差加均值的方法得到满足
N
(
μ
,
Σ
)
N(\mu,\Sigma)
N(μ,Σ)的z,这样z就相当于从N(0,1)里采样,但是根据参数重整化得到与从后验概率分布中采样一样的道理,也就可以梯度反向传播了。
1.2.4 Decoder
同理,decoder输出的也是一个概率分布,最后输出的
X
X
X是随机变量。这里我们同样也是通过预测均值和方差的方法来预测该概率分布,只不过VAE(大多数其他方法)会将方差固定为一个常数,所以用均值来等价于
X
X
X。既
μ
x
=
d
e
c
o
d
e
r
(
z
)
\mu_x = decoder(z)
μx=decoder(z)

我们根据ELBO公式已知,优化目标为:
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)]
Ez∼qϕ(z∣x)[logpθ(x∣z)]
但是我们encoder输出的是概率分布而不是
Z
Z
Z的具体数值,所以期望本身是不能解析的。我们可以借助马尔可夫链蒙特卡罗法(MCMC)去近似,既从后验概率中随机采样多个
z
^
\hat z
z^去近似等价:
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
≈
1
L
∑
l
=
1
L
[
l
o
g
p
θ
(
x
∣
z
l
)
]
E_{z\sim q_\phi(z|x)}[logp_\theta(x|z)]\approx \frac{1}{L}\sum_{l=1}^L[logp_\theta(x|z^l)]
Ez∼qϕ(z∣x)[logpθ(x∣z)]≈L1l=1∑L[logpθ(x∣zl)]
根据经验,
L
=
1
L=1
L=1即可。
最终ELBO的式子:

1.3 VAE代码和细节实现
2 VQVAE
2.1 AE、VAE和VQVAE
已知AE由输入 x x x,经过encoder得到确定值 z z z,再经过decoder还原 x ′ x' x′,在编码过程中, x 、 z x、z x、z是唯一对应的,所以严格来说,AE并不是生成模型,而是一个数据压缩模型。
VAE就是对AE的一种改进,通过约束 z z z满足正态分布,这样解码器就认得编码器编码出的向量,也就能实现生成任务。注意,AE和VAE生成的都是连续变量(这里的连续可以理解为他们都生成了概率分布,只不过AE生成的是概率分布中的某个样本点,而VAE就是生成一个概率分布)。
但是VAE生成的图像质量并不高,VQVAE的作者认为VAE不好的原因是因为编码器生成的连续变量,而如果生成的是离散变量那么生成的图像质量会更好。比如画一个人,他是男(0)或者是女(1),我们可以用离散的向量进行编码,而不是连续向量(0.7为男,0.3为女)。
VQVAE采用NLP里的embedding的思想,embedding可以看作是特殊的连续向量,将编码器输出的变量 z z z与嵌入空间(embedding space, codebook)使用K最邻近算法(距离使用均方根差,然后使用argmin找到与该向量距离最小的索引)找出最接近的嵌入向量索引,然后根据索引用该嵌入向量替代原来的编码器的输出。
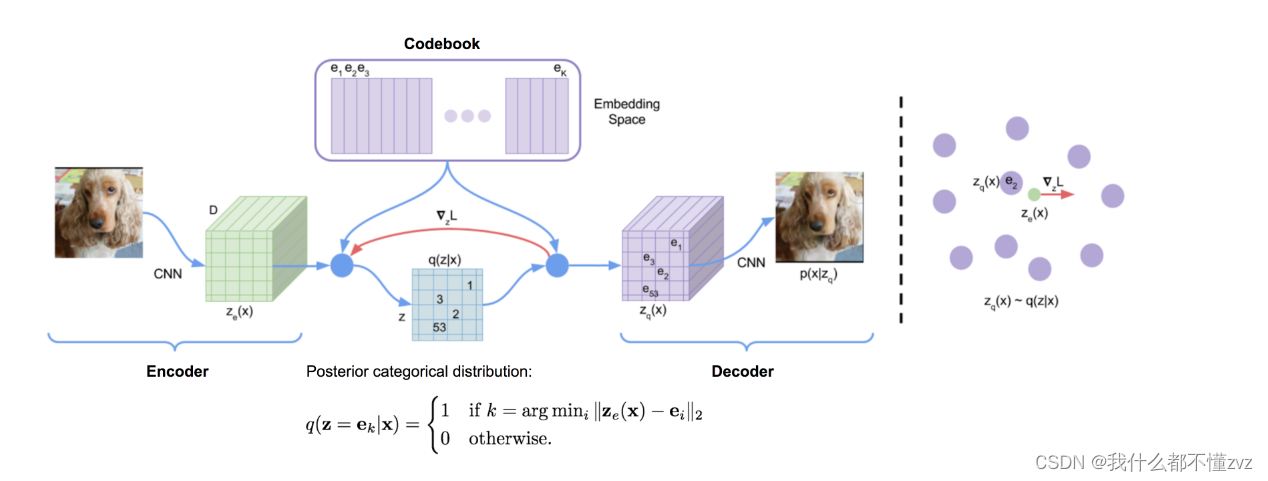
现有的问题就是:
- VAE约束 z z z满足正态分布形式,VQVAE又尝试将 z z z离散化,这样又会丢失掉编码空间的规范性,而离散化变量是不容易采样的,离散化后VQVAE不就不能生成图像了嘛?素嘟,VQVAE实际上是一个AE,只不过其编码出来的是离散的变量,VQVAE不是一个生成模型,他是一个图像压缩模型,而生成模型是其他的生成模型(pixelCNN、diffussion(构成stabe diffusion)等)
现在尝试理解以下问题:
- 如何输出离散变量?
- 如何优化encoder、decoder?
- 如何优化codebook(不是fixed,而是trainable的)
2.2 输出离散变量
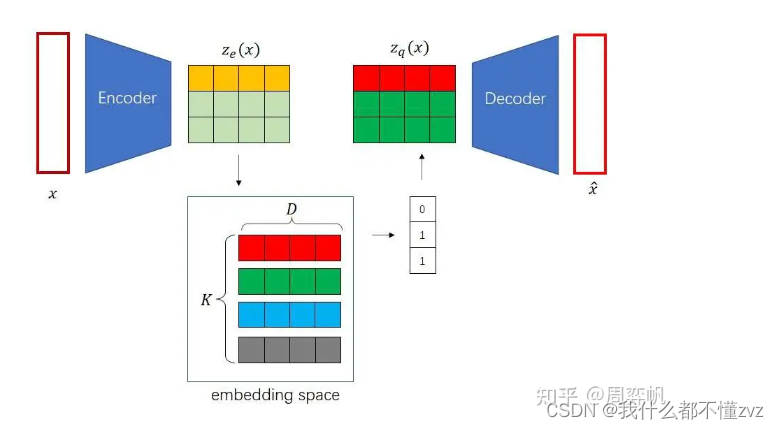
- 假设输入 x x x为 [B,C,N,N], 编码器encoder的输出 z z z为 [B,D,M,M] ,
- codebook的尺寸为 [K,D],表示有K个嵌入向量,每个嵌入向量的维度为D。在计算距离时,先让 z z z和codebook扩维(方便使用广播机制),既让 z z z 变为 [B,1,D,M,M], 而 codebook变为 [1,K,D,1,1], 然后使用均方根差计算距离,并在第二维(K)使用argmin 找到每个 z z z 对应嵌入向量最小距离的索引,然后得到索引之后我们就可以找到codebook中替代原编码输出的 z q z_q zq了。
- 索引的尺寸为 [B,M,M] 既每个输出都对应一个嵌入向量索引,少了D维是因为这就是嵌入向量的深度。所以 z q z_q zq的尺寸为 [B,D,M,M]
2.3 优化encoder和decoder
argmin是一个离散的操作,所以是不可导的。在AE中,我们的reconstrucion loss为:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
)
∣
∣
2
L = || x- decoder(z)||^2
L=∣∣x−decoder(z)∣∣2
VQVAE中变为:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
p
)
∣
∣
2
L = ||x-decoder(z_p)||^2
L=∣∣x−decoder(zp)∣∣2
而这项损失的梯度是不能传导到encoder的,因为
z
z
z到
z
p
z_p
zp之间的变化是离散的。
VQVAE这里使用一种叫Straight-Through Estimator的方法,既设计函数:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
−
s
g
(
z
p
−
z
)
)
∣
∣
2
L = ||x-decoder(z-sg(z_p - z))||^2
L=∣∣x−decoder(z−sg(zp−z))∣∣2
sg表示stop-gradient函数,在前向传播时为sg(x)=x,在反向传播时为0,也就是前向传播还是这么用,反向传播就不用了,直接把
z
p
z_p
zp求得的梯度去给encoder使用。
所以前向传播时:
x
−
d
e
c
o
d
e
r
(
z
p
)
x-decoder(z_p)
x−decoder(zp) , 反向传播时
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
)
∣
∣
2
L=||x-decoder(z)||^2
L=∣∣x−decoder(z)∣∣2
在pytorch中很容易实现:
l = x - decoder(z - (zp-z).detach())
前面提到,codebook也是可训练的,那么codebook优化的目标是什么呢? codebook优化的目标应该是: 尽可能使得codebook中的每一个嵌入向量都能尽可能表示编码器输出的每一类。比如【青年】这个的嵌入向量应该能表示14-48岁的所有编码器输出。
同样使均方根误差来计算,且使用sg函数将loss分成两部分,并配置不一样的权值(作者认为codebook应该学习的比encoder快,原论文参数为
β
=
1
,
α
=
0.5
\beta=1, \alpha=0.5
β=1,α=0.5,实验可知,
β
∈
(
0.1
,
2
)
\beta\in(0.1,2)
β∈(0.1,2)结果都差不多。
L
e
=
β
∣
∣
s
g
(
z
)
−
z
p
∣
∣
2
+
α
∣
∣
z
−
s
g
(
z
p
)
∣
∣
2
L_e = \beta||sg(z)-z_p||^2+\alpha||z-sg(z_p)||^2
Le=β∣∣sg(z)−zp∣∣2+α∣∣z−sg(zp)∣∣2
第一项又叫VQ(vector quantisation)误差,主要作用是优化codebook;
第二项又叫专注(commitment)误差,主要作用是使encoder输出不要偏离codebook太远。
2.5 VQVAE代码细节
VQVAE本质上还是一个AutoEncoder。
模型上代码上新增的几个部分主要在于:
- vq_embedding层: 使用
nn.Embedding(n_embedding, dim)作为codebook - encoder中要将输出的 z z z 与 vq_embedding的值进行均方距离的计算(算channel维度),得到[B,K,H,W]的距离矩阵,表示B*H*W个像素,每个像素对应codebook里的K个嵌入向量的距离,然后使用argmin找出距离最小的那个索引[B,H,W]。再将索引传入到vq_embedding进行运算,得到每个像素对应的嵌入向量的矩阵[B,H,W,D] (该D为嵌入向量的深度)
- decoder中,输入到decoder的数据变为:
z+(zq-z).detach()
训练过程新增的几个部分主要在于:
- 三个损失: 重建损失
mse_loss(x-x_hat),embedding损失mse_loss(z.detach()-zq),commitment损失mse_loss(z,zq.detach())
代码细节:
class VQVAE(nn.Module):
def __init__(self, input_dim, dim, n_embedding):
super().__init__()
self.encoder = nn.Sequential(nn.Conv2d(input_dim, dim, 4, 2, 1),
nn.ReLU(), nn.Conv2d(dim, dim, 4, 2, 1),
nn.ReLU(), nn.Conv2d(dim, dim, 3, 1, 1),
ResidualBlock(dim), ResidualBlock(dim))
self.vq_embedding = nn.Embedding(n_embedding, dim)
self.vq_embedding.weight.data.uniform_(-1.0 / n_embedding,
1.0 / n_embedding)
self.decoder = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1),
ResidualBlock(dim), ResidualBlock(dim),
nn.ConvTranspose2d(dim, dim, 4, 2, 1), nn.ReLU(),
nn.ConvTranspose2d(dim, input_dim, 4, 2, 1))
self.n_downsample = 2
def forward(self, x):
# encode
ze = self.encoder(x)
# ze: [N, C, H, W]
# embedding [K, C]
embedding = self.vq_embedding.weight.data
N, C, H, W = ze.shape
K, _ = embedding.shape
embedding_broadcast = embedding.reshape(1, K, C, 1, 1)
ze_broadcast = ze.reshape(N, 1, C, H, W)
distance = torch.sum((embedding_broadcast - ze_broadcast)**2, 2)
nearest_neighbor = torch.argmin(distance, 1)
# make C to the second dim
zq = self.vq_embedding(nearest_neighbor).permute(0, 3, 1, 2)
# stop gradient
decoder_input = ze + (zq - ze).detach()
# decode
x_hat = self.decoder(decoder_input)
return x_hat, ze, zq

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









