








Abstract
本文介绍了一个端到端的共指消解模型,在不使用语法解析器或手工设计的提及检测器下,可以达到不错的效果。其关键思想是将文档中的所有span直接考虑为潜在提及,并了解每种可能的先行语的分布。该模型计算span嵌入,该span嵌入结合了上下文相关的边界表示和发现注意机制。
1.Instruction
本文第一次使用了端到端的模型解决共指问题。本文的模型时对所有span空间进行推理,直到最大长度,并直接优化来自gold共参考集群的先行span的边际可能性。它包括一个span排名模型,对每个span,他决定了之前的哪个span是一个很好的先行因素。
2. Model
本文的目标是学习条件概率
P
(
y
1
,
.
.
.
.
,
y
n
∣
D
)
P(y_1,....,y_n|D)
P(y1,....,yn∣D),其最有可能的配置会产生正确的集群。本文对每个span使用多项式的乘积:
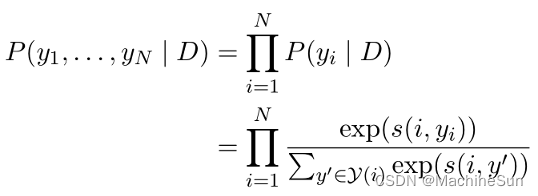
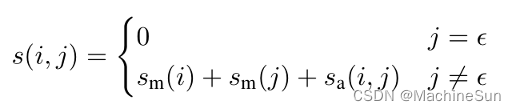
其中
s
(
i
,
j
)
s(i,j)
s(i,j)是计算span i 和 span j 指代同一对象的得分。
该得分有三个因素组成:
- span i 是否是一个有效提及
- span j 是否是一个有效提及
- j 是否是 i 的先行语
- s m ( j ) s_m(j) sm(j)是判断span i 是一个提及的概率得分
- s a ( i , j ) s_a(i,j) sa(i,j)是判断 j 为 i 的先行语的得分
2.1 Scoring Architecture
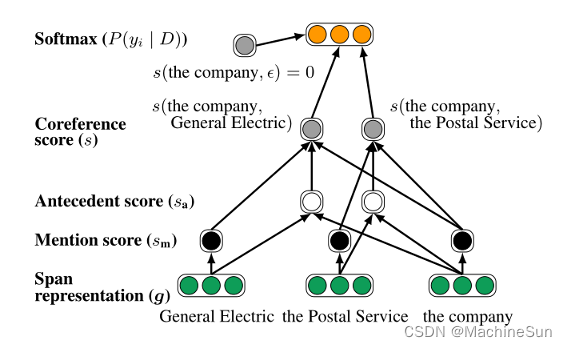
该模型的核心是每个可能的span i 的矢量表示
g
i
g_i
gi,在下一节详细描述。
在给定这些span表示的情况下,通过标准前馈神经网络计算评分函数:
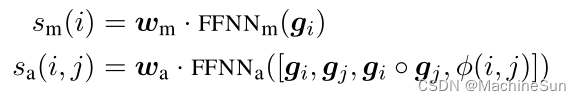
2.2 Span Representations
两种类型的信息对准确预测共指链接至关重要:围绕提及span的上下文和span内的内部结构。本文使用BiLSTM编码每个span内部和外部的词汇信息。在每个span中还包括了对单词的注意机制,以模拟中心词。
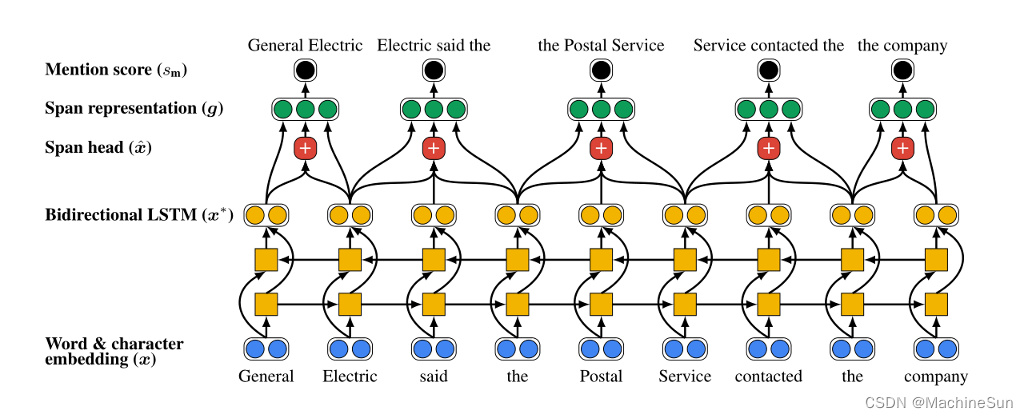
通过BiLSTM进行编码
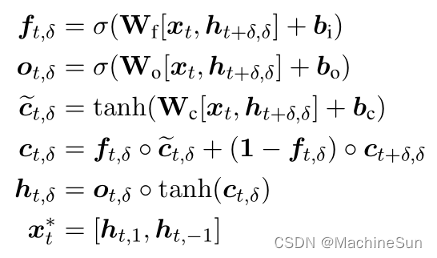
句法中心词通常被包含在以前的系统中作为特征,本文不依赖句法特征,而是使用注意力机制对每个span中的单词学习特定任务的headedness概念:
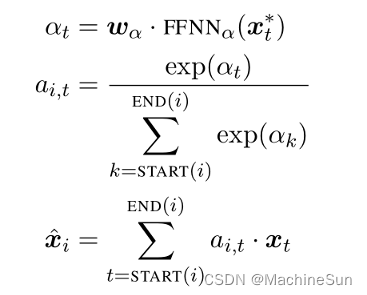
其中
x
i
∧
\overset{\wedge}{x_i}
xi∧表示span i 中单词向量的加权和。
a
i
,
t
a_{i,t}
ai,t是自动学习的,并且与传统的词义定义密切相关。
将上述span信息连接起来,作为span i 的最终表示
g
i
g_i
gi: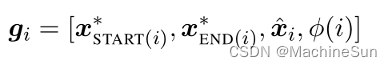
其中 x S T A R T ( i ) ∗ x^*_{START_{(i)}} xSTART(i)∗和 x E N D ( i ) ∗ x^*_{END_{(i)}} xEND(i)∗表示边界表示,保存了span外部的上下文信息。 x ∧ i \overset{\wedge}{x}_i x∧i表示soft head word向量,保存了span内部信息。 ϕ ( i ) \phi(i) ϕ(i)编码了span i 的特征向量
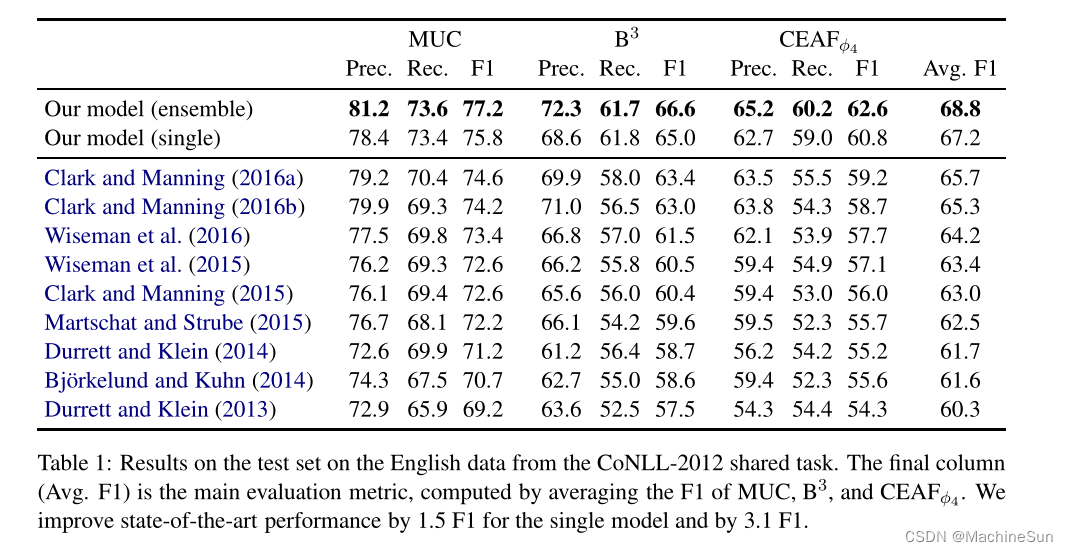
3. Experiments
4. 启示
- 现在来看是比较老的论文,虽然很老,但是值得一看,尤其是用注意力根据特定任务生成中心词的想法。
















 2878
2878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











