









 本文介绍了一种自动化提取上市公司年报中会计师事务所数据的方法,并详细解释了处理不同格式数据的策略及代码实现流程。
本文介绍了一种自动化提取上市公司年报中会计师事务所数据的方法,并详细解释了处理不同格式数据的策略及代码实现流程。
阅读本文之前可以看浏览一下上面这篇文章,对大数据分析和年报处理有一个大概的了解。
目录
一、前言
有位研究生同学,看到上面链接的文章,找到我,让我帮忙做一个年报的数据提取,随即我们便开展了合作。之前也做过年报数据的提取,比如3张财务表、金融衍生数据、银行理财数据、年报特定词汇频率统计等等,和我合作的大都是依据年报做投资的投资客和在校硕士和博士研究生,看得出来金融大数据分析是一个当前很热门的研究课题。小编是计算机相关专业的,对金融数据感兴趣,在金融数据的统计分析与模型回归方面可能是外行,但是在自动、批量提取数据方面还是很熟练的。这要感谢计算机和编程语言发明者,为我们节省宝贵的时间和解放懒人的生产力。
二、需求分析
(1)、提取年报中的会计师事务所数据,包括地址和名称
(2)、年报范围:2000--2020年所有上市公司年报
(3)、输出为excel统计表
(隐含需求1)、获取所有上市公司列表:中国上市公司分类2020四季度.xlsx
(隐含需求2)、获取所有上市公司2000--2020年的年度报告
接到这个需求的时候,感觉问题不大,第一条需求没有接触过,也不知道会遇到什么坑,不过做过类似的数据提取,问题不大。小编爽快答应合作了,就这样入坑了。
三、数据特征分析
提取数据之前我们先来看看年报中的会计师事务所信息长什么样子,方便“程序er”和她确认一下眼神,再把她高兴地娶回家(excel)。打开PDF左看看、右翻翻、上看看、下瞧瞧,发现她是长这样的:
1、模样一:在表格table中,分两行两列显示姓名和地址。长得比较正点,符合审美。

2、模样二:在表格table中,分两行三列显示姓名和地址。长得比较内敛,勉强看得过去,但不容易发现她的美。

3、模样三:不在表格中,直接年报中分两行显示姓名和地址。这个需要一定的境界才看得顺眼,需要点实力。



4、模样四:不在表格中,分三行显示,第一行显示主要信息,后面两行分别显示姓名和地址。这枚不是那么好追的,得一步一步来,坚持住。

以上四种模样就包含了年报中大部分的模样,按照这样去找,把满足要求的都娶回家的可能性很大,可以开始code了。等等,穿的衣服不一样怎么办,傻傻分不清,地址显示模糊,不过没关系,经过小编一番研究,发现穿啥衣服都能一眼看出来。
![]()
四、代码实现
重点来了----代码实现流程
1、获取公司代码列表,上述已经给出链接,小编也是利用spider爬取的,一般一年爬一次即可。
2、年报下载、这个可以小编自动spider的,主要是两个网站,同花顺和巨潮资讯网。
3、读取excel.xlsx文件,一方面读取模样信息的抽象词组,一方面保存整理提取的数据信息。
'''
读取.xlsx文件,按照行读取表格数据,返回二维数组
'''
def loadStockExcel_xlsx(xlsx_name):
wbb=load_workbook(xlsx_name)
sheet_names=wbb.sheetnames
sheet1 = wbb[sheet_names[0]]
dataByLine=[]
for row in sheet1.rows:
list_sheet1_all=[]
for cell in row:
if cell.value is None:
continue
list_sheet1_all.append(cell.value)
dataByLine.append(list_sheet1_all)
wbb.close()
return dataByLine4、主流程
##需要自己安装的库
##excel
from openpyxl import Workbook ##.xlsx format
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter #,column_index_from_string
##系统自带
import platform
import time
from random import randint
import random
##需要自己安装的库
###pdf
import pdfplumber
ws=wb['会计师事务所统计信息']
title_name=['公司股票代码',"年份",'会计师事务所名称','会计师事务所地址']
ws.append(title_name)
wb.save(os.path.join(cur_path,'Accountingfirm_info.xlsx')) ##填写表头
# print(stock_data)
# stock_data=random.sample(stock_data,3)
for line in stock_data:
try:
# line=stock_data[index]
code=line[0]
name=line[1]
# out_dir=os.path.join(os.path.join(cur_path,'year_reports'),str(code))
out_dir=os.path.join(os.path.join(cur_path,'year_reports'),str("PDF"))
if not os.path.exists(out_dir):
os.system("mkdir -p "+out_dir)
##下载年报到year_reports+code文件下
downloadYeareportFromWANGYI(code,out_dir,year_list,end_year)
pdf_list=[]
for pdf_file in os.listdir(out_dir):##获取该文件夹下的PDF文件
path_file=os.path.join(out_dir,pdf_file)
pdf_list.append(path_file)
pdf_list.sort()
print(pdf_list)
# exit()
##提取数据
yansheng_table=get_yansheng_dataFrom_pdfV2(wb,code,name,pdf_list,key_tables,year_list)
##自动调整列宽
column_widths = []
for row in wb['会计师事务所统计信息'].iter_rows():
for i, cell in enumerate(row):
try:
column_widths[i] = max(column_widths[i], len(str(cell.value)))
except IndexError:
column_widths.append(len(str(cell.value)))
for i, column_width in enumerate(column_widths):
wb['会计师事务所统计信息'].column_dimensions[get_column_letter(i + 1)].width = column_width
wb.save(os.path.join(cur_path,'Accountingfirm_info.xlsx'))
except:
print(code,name," run failed")
pass
delay=randint(0,2)
time.sleep(delay)
wb.close()5、提取数据实现细节
'''
检测当前表格是否包含‘会计师事务所’关键词
'''
def check_tableContainsKey(table,key_words):
for row in table:
for col in row:
if key_words in str(col):
return True
return False'''
从一系列年报名录中提取关键词
wb 统计表
code 股票代码
name 股票名称
pdf_list 年报PDF文件列表
key_tables 关键词列表
year_list 年份列表
'''
def get_yansheng_dataFrom_pdfV2(wb,code,name,pdf_list,key_tables,year_list):
if len(key_tables)<1:
print("key_tables for search is empty,please fill them in excel")
exit(0)
ws=wb['会计师事务所统计信息']
yansheng_table=[]
year=''
for key_list in key_tables: ##我们的关键词表只有一行
for pdf_name in pdf_list: ##循环处理年报PDF文件
year=get_report_year(pdf_name,year_list) ##获取年份
if '--' in str(year):
continue
else:
try:
print("...."+pdf_name+"....")
with pdfplumber.open(pdf_name) as pdf: ##打开pdf年报文件
yansheng_data=search_page_list_tableMode(pdf.pages,key_list) ##优先表格模式
if len(yansheng_data)<1:
print("samle line mode")
yansheng_data=search_page_list_samelineMode(pdf.pages,key_list) ##其次同行文本模式
if len(yansheng_data)<1:
print("another line mode")
yansheng_data=search_page_list_anotherlineMode(pdf.pages,key_list) ##再次分行模式
if len(yansheng_data)<1: ##提取数据失败则执行下一份PDF
continue
file_name=os.path.basename(pdf_name).split(".")[0]
#提取后的数据提取处理
yansheng_data2=[file_name,str(year)]##表格名称和年份
yansheng_data[0:0]=yansheng_data2
yansheng_table.append(yansheng_data)
ws.append(yansheng_data)##写入表格并保存,每一分PDF都会保存一次,避免程序崩溃数据丢失
wb.save(os.path.join(os.getcwd(),'Accountingfirm_info.xlsx'))
except:
pass
return yansheng_table具体进一步的实现细节可以咨询小编,代码量有点大,这里不一一贴出
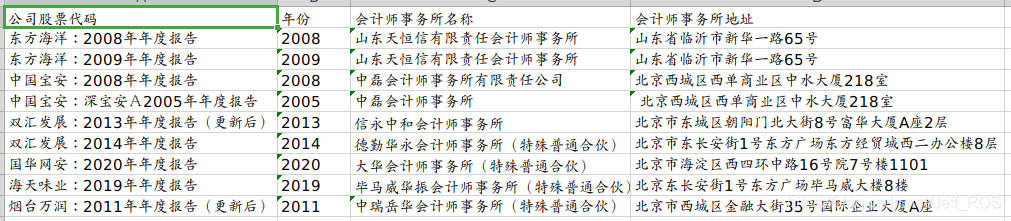
五、提取结果示列
欢迎读者交流!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











