






AIGC
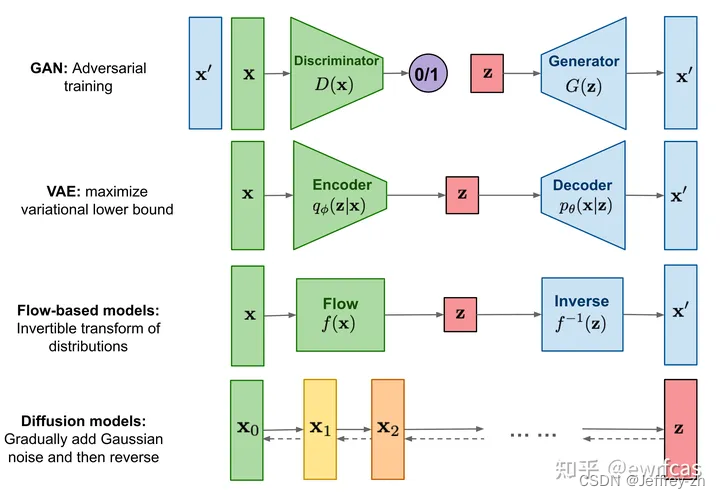
AE
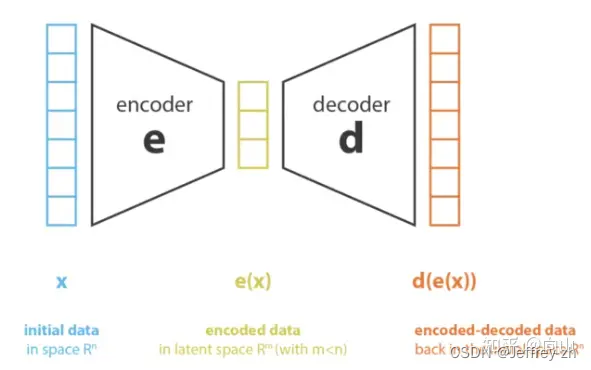
无监督学习方法:encoder将原始的高维数据映射到低维特征空间;decoder基于压缩后的低维特征来重建原始数据
AE很容易过拟合、无泛化能力只能根据高维特征空间的一个坐标点生成
VAE

- 将每个样本映射为一个分布,从分布上去取点,增强模型泛化能力,同时能增加采样的多样性;
- 同时假设输出的特征分布是一个正态分布
- VAE在训练的时候,还要求中间的正态分布都向标准正态分布靠拢,这样也就防止了方差变成0。
dVAE:将输入x做一定程度的扰动,最后优化目标一样,效果很好;证明了图像信息的冗余
GAN
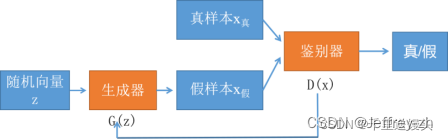
DNN网络使用MSE计算LOSS会使得图片失去随机性,引入一个DNN来判断是否是真实的还是生成的
模型结构
生成器和判别器:交替训练
生成器损失函数: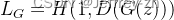
判别器损失函数:
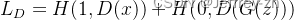
SAM(Segment Anything Model)
提出了一个基于提示的分割任务;可被看作CV界的基础模型
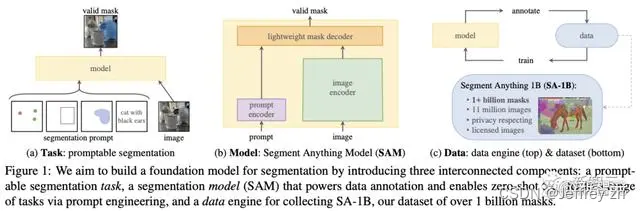
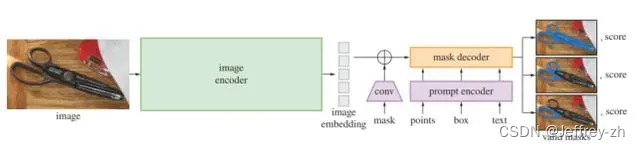
模型:
- 密集提示(Mask)利用卷积层来注入知识,稀疏提示(点(用户可以通过点击实现交互)、bbox(可以画一个box给提示)和text信息)利用prompt encoder来注入知识
- Image encoder使用的是MAE的ViT,decoder非常轻量级
- 数据标注->喂给模型训练->使用模型标注->循环
DDPM
Time embedding让模型知道现在到了反向扩散的哪一步,可以在初始扩散步骤的时候预测出轮廓,最后几步预测出边边角角
方法:
- 前向扩散过程是一个逐步加噪过程:
方差为固定值 β \beta β ,均值则由 β t \beta_t βt和 x t − 1 x_{t-1} xt−1共同决定

因此只要确定任意时刻的 β \beta β就能够由x_0 chain rule推出任意时刻的x_t(马尔可夫过程)
- 随着t增大不断接近一张完全的噪声图
- 一般t增大 β t \beta_t βt的值也会逐渐增大
2. 逆扩散去噪过程
如果能够从q(
x
t
−
1
∣
x
t
x_{t-1}|x_t
xt−1∣xt)中采样就可以实现重建,但是由于无法从完整数据集中找到数据分布,因此需要学习一个模型
p
0
p_0
p0来近似这个分布
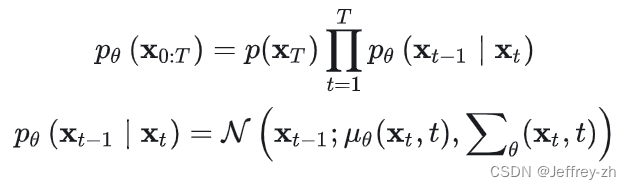
3. 加入time embedding让模型知道当前是在什么阶段,开始的时候可能生成轮廓,后面学习道物体的细小特征
总结

主要贡献
- 反向扩散过程提出去预测噪声而不是去预测 x t − 1 x_{t-1} xt−1
- 学习一个正太分布只需要去学习均值和方差,进一步实验表明只需要学习均值效果就足够好
Diffusion model beats GAN
classifier guidance:训练一个分类器作为生成模型的条件

RQ
-
现有的衡量指标例如FID\IS\Precision不能衡量生成多样性,GAN多样性不好
-
扩散模型虽然易于扩展、多样性好,但图片质量仍然不如GAN
Related work
-
训练目标是缩小真实噪音和训练噪音之间的均方误差
-
DDPM中高斯分布的方差可以学习也可以固定,学的话效果更好
-
DDIM将噪声设置为0,采样步骤更少
Method
- 优化Unet架构:加深模型、加宽维度、加多注意力头数
2.在噪声图像上训练分类器,利用分类器分数和目标之间的交叉熵损失计算梯度,利用梯度来引导下一步的生成采样

缺点
- 需要训练噪声数据版本的classifier网络
- 推理时每一步都需要额外计算classifier的梯度。
More Control for Free! Image Synthesis with Semantic Diffusion Guidance(语义引导方式)
- Guided Diffusion
基于类别的扩散模型,基于DDPM模型,在逆向过程中,加入分类器,对采样生成图片进行分类,然后计算交叉熵损失梯度,通过梯度向下传导,来控制采样方向与类别相关;
那么既然可以用类别来引导图像生成,同样也可以用文本语义和图像语义来引导。
2. Semantic Guidence Diffusion
扩散模型通过类别引导类似于图片优化问题,所以类似的提出了使用语义引导,即文本语义和图片语义进行引导。
3. 文本语义引导:这里主要使用CLIP来计算文本和采样生成图片相似度损失梯度,进行引导采样图片生成
4. 图片语义引导:希望生成与引导图片类似的图片,这里可以分为图片内容引导,即使用CLIP图片特征进行计算相似度,图片结构引导,使用encoder的空间特征分布,*图片风格引导,*基于Gram矩阵进行计算损失。
5. 混合引导 :通过将上述引导函数以一定比例加起来,可以基于多种条件进行生成。
GLIDE
RQ
使用了CLIP guidance和Classifier-free guidance方法发现后者在逼真度和对caption的相似性上更像
Method
除了进行文生图之外还可以进行进行图像编辑;
- 结构上:将text用trans编码替换ADM模型的class embed;最后一层trans embed被投影到了ADM模型的注意力层并且concat起来;
- 用了Classfier-free的方法
- “Noised CLIP models” (Nichol 等, 2022, p. 6) (pdf) “:输入噪音图像给CLIP但训练目标还是之前一样
DALL·E
classifier-free guidance
研究问题
数据量是限制模型能力得主要原因,而不是模型结构和loss设计
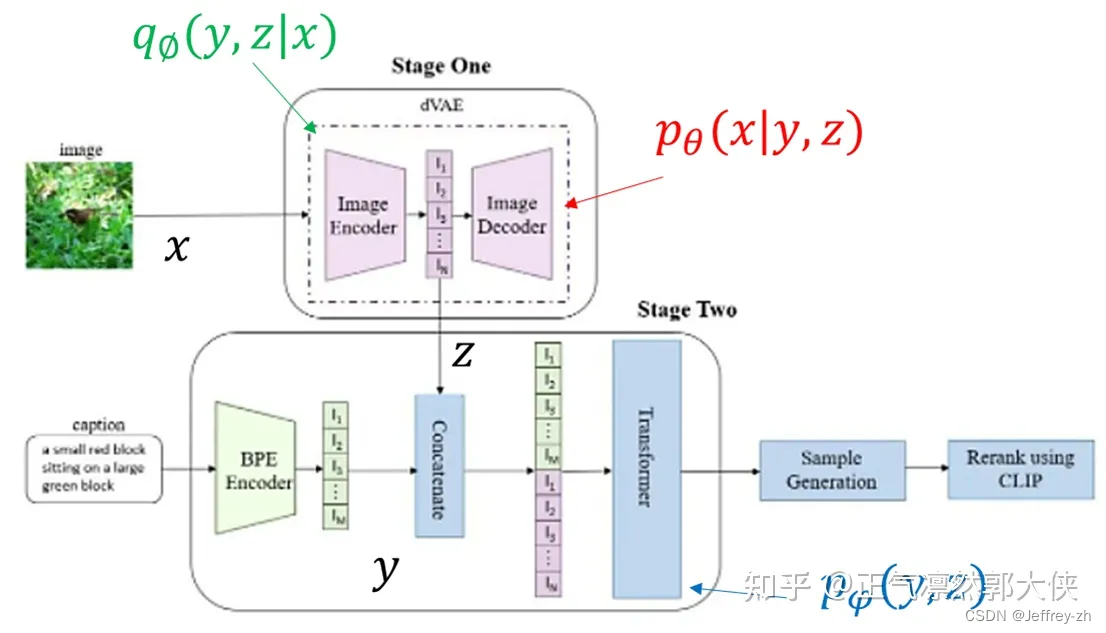
方法
-
首先训练一个dVAE来将RGB图像压缩成image token
-
将BPE编码的文本token与图像token(flatten)拼接起来训练一个自回归Trans
- BPE:字节对编码,一种子词算法。Subword 算法;每次将出现频率最高的字符进行合并加入到词表中,不断重复这个步骤;直到最大频率为1或者达到词表上界;
-
整体训练目标是最大化ELBO证据下界:
-
想要求p(z|x)利用贝叶斯公式展开后难以计算分母的积分
-
利用变分推理的思想:利用一个更简单的分布q(z)来近似p(z|x),利用KL散度来刻画两个分布的差异,优化目标就是最小化KL散度;
-
然而D中仍然有后验概率分布,没办法计算
-
ELBO:证据下界,最大化ELBO等价于最小化KL散度,因为左边是一个常数
- logp(z,x)与logq(z)比较容易计算,因此最大化他们(证据下界)即最小化KL
-
-
由于ELBO的参数q_phi(dVAE encoder),是一个离散的分布难以使用梯度优化:这里用gumbal softmax来优化
DALL·E 2
研究问题
使用CLIP的鲁棒表征能力来捕获图像的语义和风格,进而基于文本产生图像
比GLIDE、GAN的图像更多样化,GAN虽然逼真但是多样性不太好
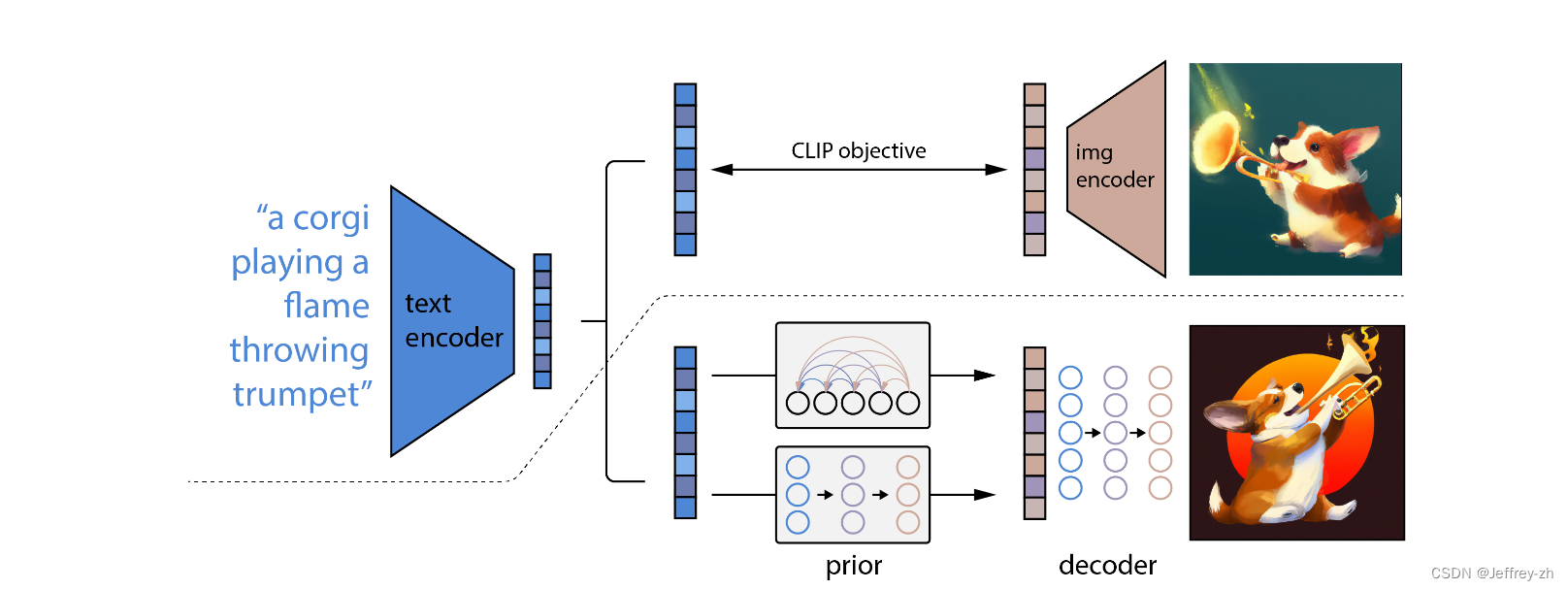
方法
层级式的生成图片,从低分辨率到高分辨率生成图像;
两阶段图像生成器,先生成图像特征再生成图像
推理过程
-
首先CLIP的文本embedding通过一个自回归或者diffusion prior产生图像embedding
-
这个图像embedding通过一个diffusuion decoder产生最终的图像
模块详解
CLIP+GLIDE
-
Decoder:使用了CLIP guidance和classifier-free guidance;纯CNN结构
-
prior:
-
自回归模型:把图像特征遮住,GPT式的预测
-
Diffusion模型:classifier-free guidance,没有像之前的模型一样去预测噪声然后相减,而是直接去重建特征;
-
训练过程
-
首先训练CLIP模型,这里用了一半CLIP的训练数据,用了一半DALLE的训练数据
-
使用CLIP img embedding来监督文本端经过prior生成的图像特征
缺陷
-
生成文字做的不好
-
细节缺失
-
不能读懂上下关系
DALLE 3
RQ
-
当前很多模型缺乏prompt-following能力,不能够生成与prompt细节一致的图像;
-
网络爬取的caption经常不正确,缺乏对图像的细节描述
数据
使用image captioner来合成图像的caption,提升文本质量,提高模型prompt-following的能力
-
文生图扩散模型容易过拟合数据集,如果文本总以空格开头,若没有空格则生成不了正确图像
-
因此采用混合合成caption和gt caption的方式引入正则化(GT是人类标注的有多样性)
Captioner
-
预训练CLIP
-
利用text和clip embedding采用语言建模损失训练一个LLM->还是会出现不描述细节的问题
-
在一个短文本描述数据集上微调的一个产生短文本的model;同理再长文本数据集上微调
模型评估
CLIP Score:利用CLIP编码合成的图像,和text计算相似性分数,然后对所有样本取平均
GPT4 V自动评估:将caption和产生的图像一起送给GPT让他给出答案正确或错误
“T2I-CompBench” :使用人工评估风格,形状颜色等
Detail
使用GT和95%的详细描述合成caption来训练
Stable Diffusion
重要贡献:在隐空间进行扩散,降低显存占用和计算复杂性
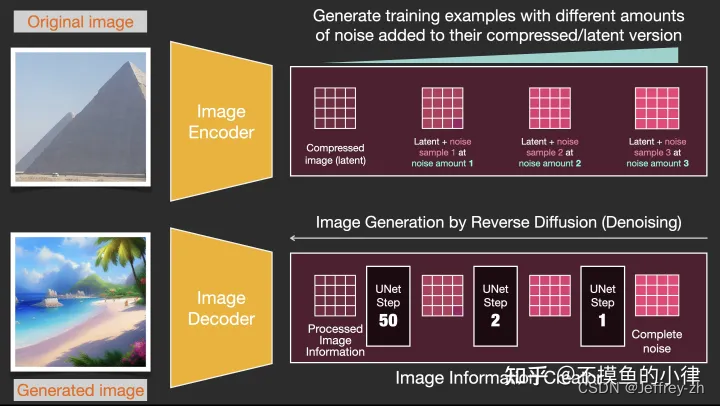
大致步骤:
- 数据集中选择一张图像
- 从K种噪音中随机产生噪音
- 将噪音逐步加在图像上,直到图像成为纯噪声
- 噪声图像输入U-net预测所加噪声,利用Scheduler逐步去噪(每次输入Unet中还有时序embedding使得网络知道当前时间步)
- 计算L2损失,反向传播更新参数
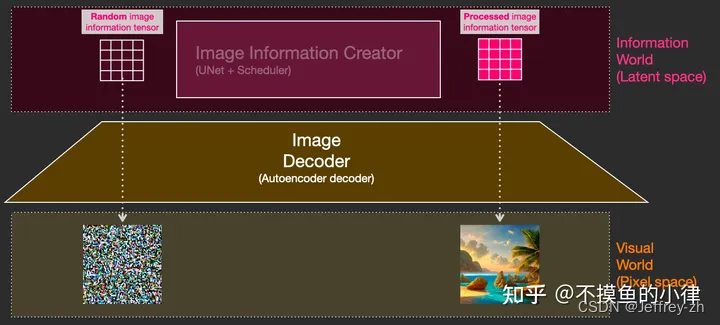
结构
- Text encoder:用CLIP抽取文本特征,用来控制图片的生成
- Unet添加文本信息:在原来残差块之间添加交叉注意力层,将CLIP文本特征加入来关注到文本信息隐变量
- Image Creater:用Unet当作Image creater逐步处理/扩散隐空间中的信息;输入由文本向量和噪声组成多维数组;
图中可以看到输入Image Creater前解码出来是乱码,输入Creater之后解码出来则是清晰图像 - Image Decoder:AE的解码器

LoRA
一言以蔽之:大模型基础上额外增加一些训练层,在冻住大模型的基础上,训练lora模型。
在Stable Diffusion微调的情况下,LoRA可以应用于与描述它们的提示相关的图像表示之间的交叉注意力层
- 训练速度更快
- 计算需求更低
- 训练权重更小,因为原始模型被冻结,我们注入新的可训练层,比UNet模型的原始大小小了近一千倍。
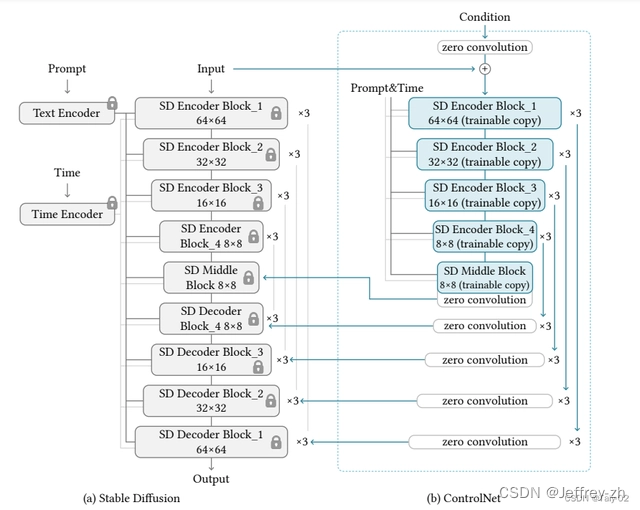
ControlNet
可以控制图片的构图、而LoRA是控制图片的风格;本质上还是文生图模型
RQ
虽然Stable Diffusion生成的图片质量远超以往的GAN,VAE等,但还达不到精细化可控生成的目的
作用
ControlNet提供了包括canny边缘,语义分割图,关键点,涂鸦在内的多种输入条件,拓展了SD的能力边界
模型思想
- 将SD模型拷贝两个副本,分别是固定权重,以及一个可训练副本;
- 用这种copy方式的动机是为了避免在数据集较小时过度拟合,并保持从数十亿图像中学习的大型模型的生产就绪质量。ControlNet的可视化结构如下图所示:

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









