






深度学习中Python常用知识点
在学习YOLOP的过程中,记录python及Pytorch教程,深度学习知识点。
1.Python知识:
- Python中if name == ‘main‘:的作用和原理
- enumerate 用法总结:enumerate参数为可遍历的变量
- eval 可以将字符串生成语句执行
- import time:
格式化时间对象有9个属性,均为int型:tm_year=2020,表示当前是2020年
tm_mon=10,表示当前是10月
tm_mday=10,表示当前是10日
tm_hour=13,表示当前是13时(注意是格林尼治时间,加8小时才是北京时间)
tm_min=50,表示当前是50分
tm_sec=24,表示当前是24秒
tm_wday=5,表示当前是一周的第6天(周日是0,周一是1,周六是6)
tm_yday=284,表示当前是一年的第284天
tm_isdst=0,表示不是夏令时(=1表示是夏令时)
- range(17,25):左闭右开区间
- Lambda;Python的Lambda函数用法详细说明
在Python中有两种函数,一种是def定义的函数,另一种是lambda函数,即匿名函数。
冒号:之前的a,b,c表示它们是这个函数的参数。
匿名函数不需要return来返回值,表达式本身结果就是返回值。
eg:
lf = lambda x: ((1 + math.cos(x * math.pi / cfg.TRAIN.END_EPOCH)) / 2) *
(1 - cfg.TRAIN.LRF) + cfg.TRAIN.LRF # cosine
lr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
-
Round:round() 方法返回浮点数x的四舍五入值。
以下是 round() 方法的语法:round( x [, n] )
参数:
x – 数值表达式。
n – 数值表达式,表示从小数点位数。 -
Path.cwd()使用注意事项:
python中cwd其实就是current work dir
Path.cwd()获取的位置就是终端所在的位置 -
Python relpath函数:
import os
os.path.relpath(path, start)
path 需要获取的路径。
start 开始的路径。
返回从 start 路径到 path 的相对路径的 字符串。如果没有 start 参数,就使用当前工作目录作为开始路径。 -
path.resolve()
path.resolve总是返回一个以相对于当前的工作目录(working directory)的绝对路径。 -
argparse.ArgumentParser()
使用步骤:
1:import argparse 导入该模块;
2:parser = argparse.ArgumentParser() 创建一个解析对象;
3:parser.add_argument() 添加命令行参数和选项,每一个add_argument方法对应一个参数或选项;
4:parser.parse_args() 调用parse_args()方法进行解析;解析成功之后即可使用 -
os.getenv()
用途:获取环境变量键的值(存在),否则返回默认值
用法:os.getenv(key, default = None)
2.Pytorch知识:
- Dataoader:
pytorch 的数据加载到模型的操作顺序是这样的:
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练 - weights for [P, R, mAP@0.5, mAP@0.5:0.95]
mAP@.5:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
3.YOLOP知识:
为使每次运行网络,相同输入情况下得到相同的输出:
需要:1.使用相同的网络结构,学习率,迭代次数,batch size,固定随机数种子;
2.固定PyTorch等框架的种子;固定cuda的随机数种子;
3.torch.backends.cudnn.deterministic设置为true,那么每次返回的卷积算法是确定的默认算法。
- BCE 交叉熵损失函数Binary CrossEntropy
- Focal Loss:focal loss 是一种处理样本分类不均衡的损失函数,FL(pt)=−(1−pt)γlog(pt)

- 各种优化器的比较
优化器在机器学习、深度学习中往往起着举足轻重的作用,同一个模型,因选择不同的优化器,性能有可能相差很大,甚至导致一些模型无法训练
θ←θ−λg
import torch
#改代码不可运行
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
#梯度清零
optimizer.zero_grad()
loss_fn(model(input), target).backward()
#参数更新
optimizer.step()
针对传统梯度优化算法的缺点,许多优化算法从梯度方向和学习率两方面入手。有些从梯度方向入手,如动量更新策略;而有些从学习率入手,这涉及调参问题;还有从两方面同时入手,如自适应更新策略。
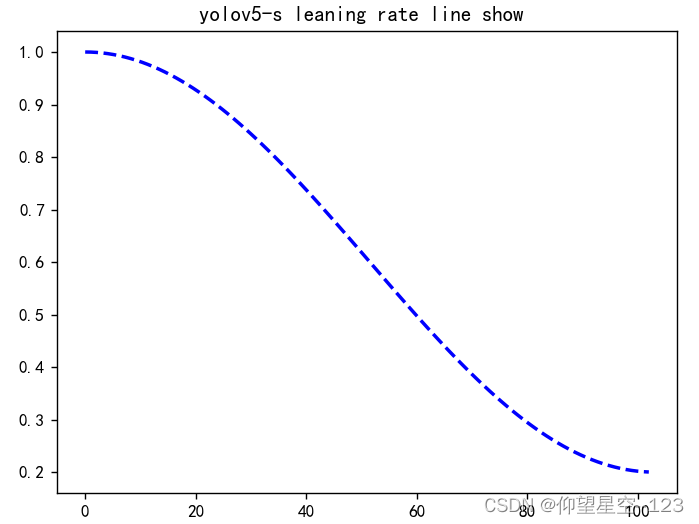
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp[‘lrf’]) + hyp[‘lrf’] # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
- 深度学习八股文
- Tricks:
-scaler
对Pytorch的AMP(autocast与Gradscaler进行对比)自动混合精度对模型训练加速 - YOLOv5训练与测试参数介绍
–evolve:是否寻找最优参数
–resume: 指定之前训练的网络模型,并继续训练这个模型















 5200
5200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









