






目录
3. Masked Image Modeling(MIM)方法
1.简介
其实自监督学习的核心思想很简单,利用大量的无标签数据训练模型,然后将其作为预训练模型在下游任务上进行微调(有标签)。在用无标签图像训练模型时主要通过设计辅助任务,用图像自身的信息作为标签训练。常见的就是对比学习,将原图本身和经过图像增强的图像作为正样本,其他作为负样本。
对比学习,cv通过对输入图像进行数据增强,将数据增强的图像作为原图的正样本,其他输入图像作为负样本。但是这种模式在nlp中却不好使用,将一句话中的单词替换为同义词,预测的结果很可能会产生偏差,所以nlp选择用dropout的方法。同一张图像通过两个分支进行dropout,其中dropout的层是不一样的,随机选择的,所以产生的结果向量也是不同的,那么这两个向量就互相为正样本了。
token。Tokenization is a way of separating a piece of text into smaller units called tokens.And tokens are the building blocks of Natural Language,which can be either words, characters, or subwords.
token包含:class token、patch token,在NLP叫每一个单词为token,然后有一个标注句子语义的标注是CLS,在CV中就是把图像切割成不重叠的patch序列(其实就是token)。
在大型语言模型中,"token"是指文本中的一个最小单位。通常,一个token可以是一个单词、一个标点符号、一个数字、一个符号等。在自然语言处理中,tokenization是将一个句子或文本分成tokens的过程。
在大型语言模型的训练和应用中,模型接收一串tokens作为输入,并尝试预测下一个最可能的token。对于很多模型来说,tokens还可以通过embedding操作转换为向量表示,以便在神经网络中进行处理。由于大型语言模型处理的文本非常大,因此对于处理速度和内存占用等方面的考虑,通常会使用特定的tokenization方法,例如基于字节对编码(byte-pair encoding,BPE)或者WordPiece等算法。
在NLP比如BERT,输入一段句子,分词器会将句子中的单词、符号转换成一个个token。对于视觉Transformer,把每个像素看作是一个token的话并不现实,因为一张224x224的图片铺平后就有4万多个token,计算量太大了,BERT都限制了token最长只能512。所以ViT把一张图切分成一个个16x16的patch(具体数值可以自己修改)每个patch看作是一个token,这样一共就只有(224/16)*(224/16)=196个token了。当然了,单单的切分还不够,还要做一个线性映射+位置编码等等。不同的Transformer在处理细节上也会有不同,比如最近看的Swin-T加入了多尺度,从最开始的4*4的patch缩放到后边的32*32。
BEIT最终得到的就是一个ViT预训练模型,用这个预训练模型在下游任务上进行训练,效果会有明显提升。
2.对比学习方法
2.1 MoCov1
对比学习的本质实际上是让两个相似(比如相同类别)的图像在特征空间内尽可能相近,不相似的图像尽可能远,这里相似的图像就是正样本,不相似的图像就是负样本。而如何区分正负样本对的方法就形成了各式各样的代理任务(pretext task)。那MoCo所用的代理任务就是个体判别了,每张图像都是单独的一类,在网络中只有原图经过数据增强后的图像属于原图的正样本,其他的图像都是负样本。
有了区分正负样本的方法后就是常规的,进入encoder提取特征,输出的特征用NCEloss进行反向传播,梯度下降。
MoCo把对比学习看作是一个动态字典的任务,他把锚点图像看作是一个query,将query与字典中的所有特征进行查询匹配,与正样本更加接近,与负样本远离。为了使字典中的k0,k1...与q能匹配上,字典的编码器是要一直随着锚点的编码器更新的,尽可能与锚点编码器相似,所以字典是动态的。
为了使对比学习结果更好,字典应该具有两个特性,一个是字典足够大,第二个是在训练时要保持尽可能的一致性。
(1)字典足够大才能学习到真正将正负样本区分开的特征。
(2)只有锚点的编码器和字典的编码器保持一致,才能让网络真正匹配到正样本。如果用了不同的编码器,那么q很有可能匹配到与q特征相似,但是匹配到的是负样本的情况。
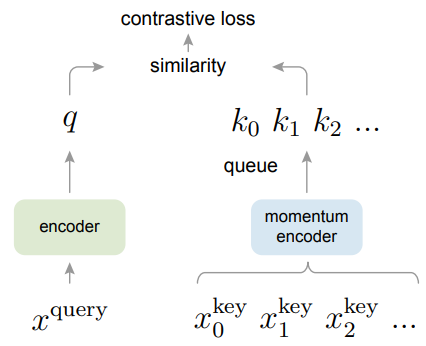
MoCo的主要改进在于做了一个动态的字典,其中包括一个队列和一个移动平均编码器,也就是动量编码器。
MoCov1的原理很简单,输入一个batchsize的数据,分别进行两次数据增强,一个作为锚点,一个作为正样本。先计算每个图片的锚点与正样本的损失函数,使她两尽可能相近。然后计算队列中的特征与锚点的损失函数,使她两尽可能远离。最后用这个batch的正样本特征替换队列中的最老特征,完成梯度更新。动量编码器也更新。
通过队列和动量编码器的设置,MoCo就可以创建一个又大又一致的字典了。
创新点:
- 使用队列代替memory bank,将负样本大小与batchsize的关系分开。
- 使用动量编码器,让参数更新的比锚点encoder慢一点,使得队列中的特征尽量保持一致。
- 使用InfoNCE损失函数。
2.2 SimCLR
SimCLR是一个里程碑,使得自监督学习的模型在imagnet上超越有监督模型。SimCLR利用了对比学习。
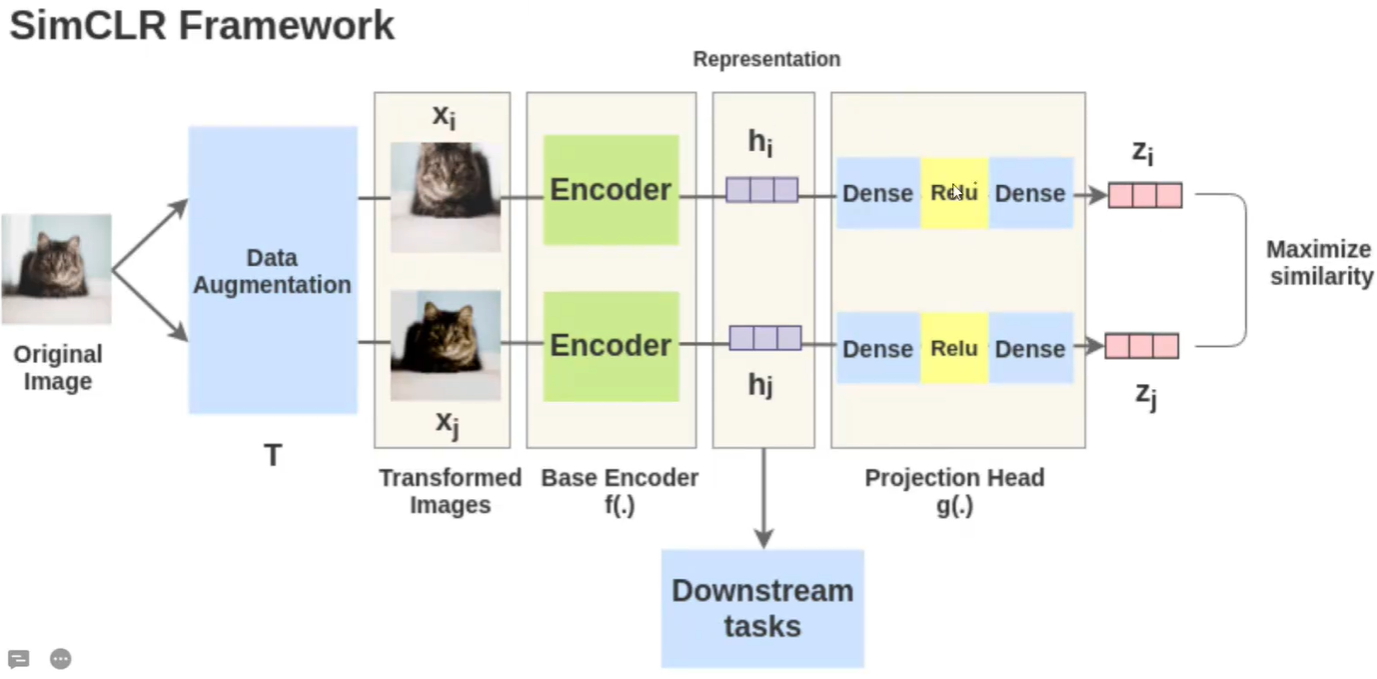
优点:
- 摒弃了之前对比学习使用的memory bank,仅使用同一个batch中的其他图像作为负样本。
- SimCLR的两个编码器参数是共享的,使得正负样本提取出来的特征和锚点特征是同步的。
- 增加了多个数据增强的操作,提升了模型的性能。
- 引入可学习的非线性变换,也就是在提取好的特征后又加入了一个MLP层,SimCLR中叫做projection head,大大提高了学习到的特征的质量。
- SimCLR使用了一种对比损失,称为“NT-Xent损失”(归一化温度-尺度交叉熵损失)。
- SimCLR在更大的batchsize、更长的训练时间和更大的模型上表现更好。
缺点:
- 训练所需的代价太大,原文中用了8192的batchsize,大的batchsize难以优化。
上面加粗的部分为创新点。
SimCLR的原理非常简单,输入一个图像,对该图像先进行数据增强得到不同的两个图象,然后经过encoder进行特征提取,分别得到hi和hj,在经过一个MLP得到最终的向量Zi和Zj。训练好后拿出特征提取器Encoder,这样在用到下游任务上时训练速度精度都会更好。
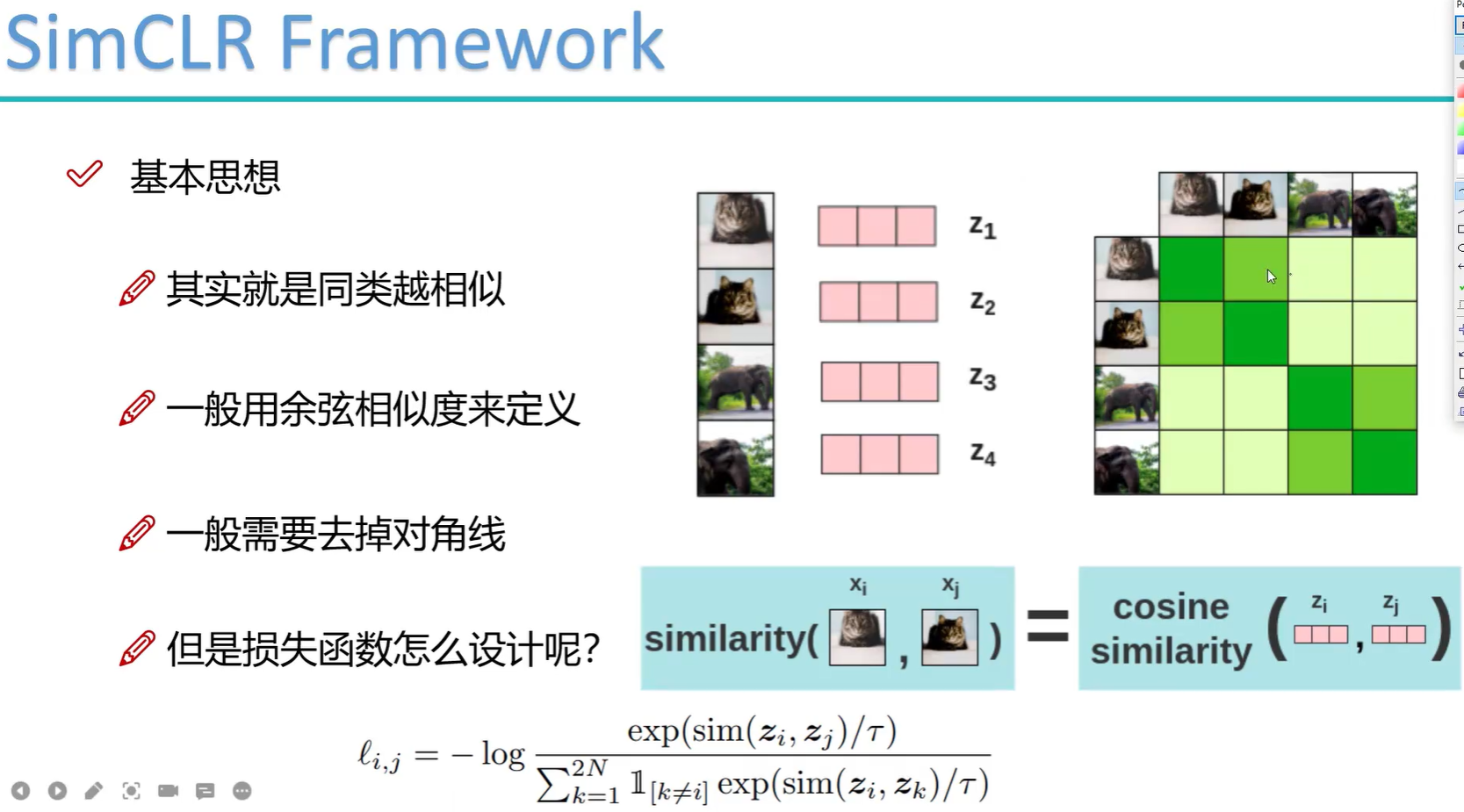
训练过程的batchsize为8192,所以需要的硬件条件比较苛刻。训练时输入经过数据增强的数据,将其他8191个样本作为负样本,原图的数据增强图作为正样本。对输出的向量算余弦相似度,对角线上的值接近一。
2.3 MoCov2
借鉴SimCLR加入了两个改进,一个是在Encoder后加入MLP层,一个是更加多样的数据增强。
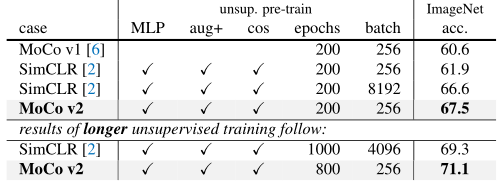
创新点:
- 在特征提取模块后加入MLP层。
- 加入更多样的数据增强方式。
- 加入余弦学习率策略。
2.4 BYOL
MoCo,SimCLR等对比学习方法都依赖于负样本,BYOL不需要负样本也能在ImageNet上取得74.3%的top-1分类准确率。
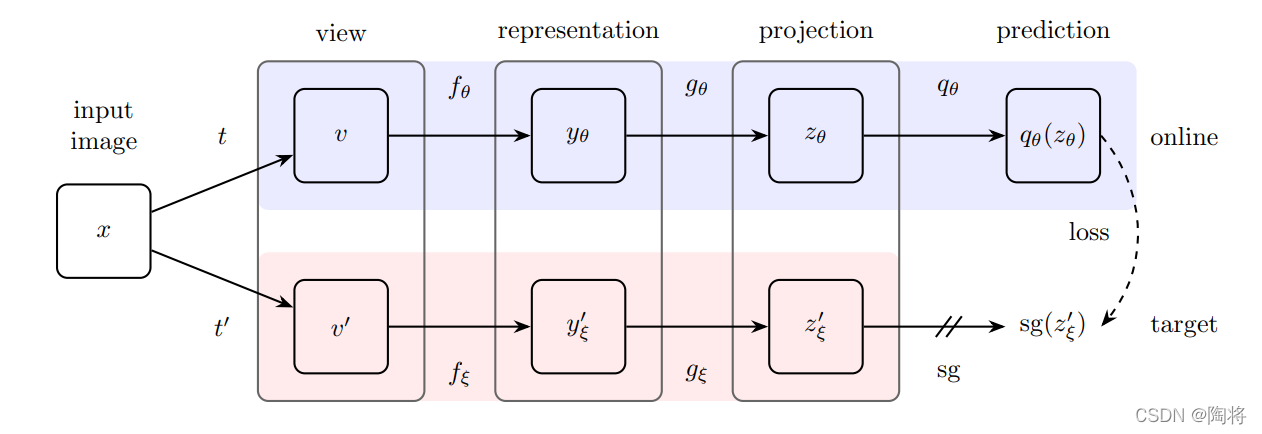
BYOL使用两个神经网络,online网络和targets网络。target网络与online网络有相同的架构,但是拥有不同的参数。
BYOL借鉴了MoCo的momentum网络,添加了一个MLP层q θ 从z预测z ′,p = q θ ( z )。BYOL用正则化后的目标z ′和正则化后映射输出p的L2损失函数替代了对比损失函数。BYOL中不需要负样本,所以BYOL不需要memory bank。
- SimCLR中的MLP,每个线性层后都带有BN。
- MoCo V2中的MLP,不使用BN。
- BYOL中的MLP,只在第一个线性层之后带有BN。
BN似乎是BYOL成功的主要因素。可以参考BYOL-CSDN博客
创新点:
- 提出了BYOL,不需要负样本的自监督学习方法。
- 在online层添加了预测器。
- target网络的参数使用EMA(指数滑动平均)公式(与MoCo的动量更新公式相似)进行更新。
- 采用L2损失函数代替对比损失。
2.5 SwAV
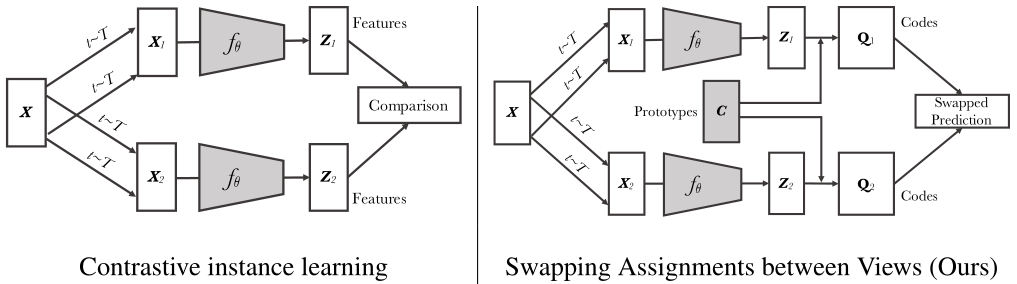
无监督图像表示已经显著减少了与监督预训练的差距,特别是对比学习方法的最新成就。这些对比方法通常在线工作,并且依赖于大量显式的两两特征比较,这在计算上具有挑战性。经典对比学习方法如图左所示,输入一张图像,经过不同的数据增强得到一个锚点和一个正样本,分别经过编码器得到特征,最后对特征算相似度来进行梯度下降。
SwAV则在通过相同的编码器编码后同时对数据进行聚类,同时加强对同一图像的不同增强(或“视图”)产生的聚类分配之间的一致性。Z1、Z2经过聚类分类方法与prototypes C生成得到目标Q1和Q2,然后Z1与C点乘生成p1去预测Q2,Z2与C点乘生成p2去预测Q1。相当于Q1和Q2是groundturth,计算p1与Q2和p2与Q1之间的差别,损失函数Loss = loss(Z1, Q2) + loss(Z2, Q1)。
损失函数为:
![]()
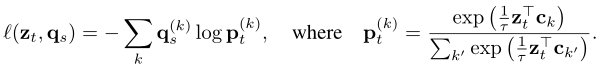
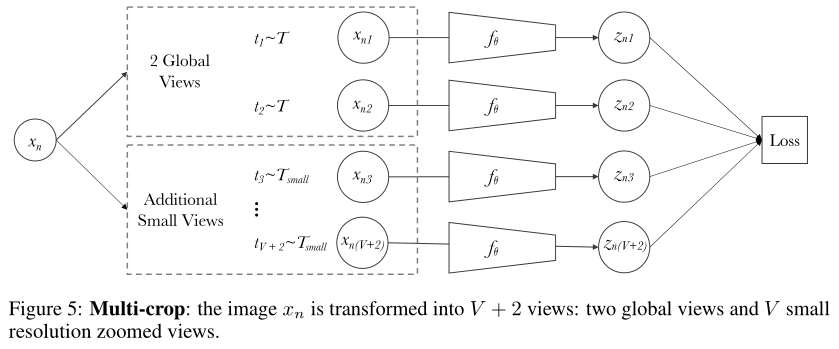
SwAV另一个非常有效的手段就是muti-crop数据增强方法。
代码如下所示:
训练脚本为
python -m torch.distributed.launch --nproc_per_node=8 main_swav.py \
--data_path /path/to/imagenet/train \
--epochs 400 \
--base_lr 0.6 \
--final_lr 0.0006 \
--warmup_epochs 0 \
--batch_size 32 \
--size_crops 224 96 \
--nmb_crops 2 6 \
--min_scale_crops 0.14 0.05 \
--max_scale_crops 1. 0.14 \
--use_fp16 true \
--freeze_prototypes_niters 5005 \
--queue_length 3840 \
--epoch_queue_starts 15class MultiCropDataset(datasets.ImageFolder):
def __init__(
self,
data_path,
size_crops,
nmb_crops,
min_scale_crops,
max_scale_crops,
size_dataset=-1,
return_index=False,
):
super(MultiCropDataset, self).__init__(data_path)
assert len(size_crops) == len(nmb_crops)
assert len(min_scale_crops) == len(nmb_crops)
assert len(max_scale_crops) == len(nmb_crops)
if size_dataset >= 0:
self.samples = self.samples[:size_dataset]
self.return_index = return_index
color_transform = [get_color_distortion(), PILRandomGaussianBlur()]
mean = [0.485, 0.456, 0.406]
std = [0.228, 0.224, 0.225]
trans = []
for i in range(len(size_crops)):
randomresizedcrop = transforms.RandomResizedCrop(
size_crops[i],
# 随机裁剪图像的原始尺寸,比如原本1024*1024的图像,就会缩放到512*512后再进行裁剪
scale=(min_scale_crops[i], max_scale_crops[i]),
)
trans.extend([transforms.Compose([
randomresizedcrop,
transforms.RandomHorizontalFlip(p=0.5),
transforms.Compose(color_transform),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)])
] * nmb_crops[i])
self.trans = trans
def __getitem__(self, index):
path, _ = self.samples[index]
image = self.loader(path)
multi_crops = list(map(lambda trans: trans(image), self.trans))
if self.return_index:
return index, multi_crops
return multi_crops我们只需要关注这几个参数,
--size_crops 224 96 \
--nmb_crops 2 6 \
--min_scale_crops 0.14 0.05 \
--max_scale_crops 1. 0.14 \size_crop表示resize后的图像尺寸,指定最终得到的图片大小。num_crops表示输出的图像个数。scale指定裁剪区域的面积占原图像的面积的比例范围,是一个二元组,如(scale_lower, scale_upper),我们会在[min_scale_crops, max_scale_crops]这个区间中随机采样一个值。
先进行随机大小和随机宽高比的Crop操作,再对Crop出来的区域进行Resize操作。
第一列表示的是常规的数据增强操作,输出两个数据增强后不同的224*224图像。裁剪区域的面积占原图像的面积的比例范围为[1,0.14]。第二列是SwAV中的操作,添加6个数据增强后不同的96*96图像。裁剪区域的面积占原图像的面积的比例范围为[0.14,0.05]。

所以SwAV除了用两个增强的原尺寸图片之外,还使用了V个低像素crops,这样就一共有了V+2个sanmples,但是为了计算方便,作者只在原尺寸图像上计算了q,对于低像素的图片,这里并没有计算code。那么低像素的crops有什么用呢,这在损失函数中体现出来了。
不加muti-crops的损失函数为
![]()
加入之后变为
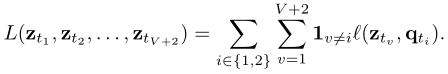
其中的q只通过全分辨率crops计算。但是z是每一个数据增强后的图像都要算。
创新点:
- 将聚类方法和对比学习融合起来,预测的结果与聚类中心相对比。
- 使用了multi-crops数据增强方法,极大提高了模型性能。
2.6 SimSiam
孪生网络已经成为最近各种无监督视觉表示学习模型中的常见结构。这些模型最大化了一幅图像的两个增强之间的相似性,在一定的条件下避免坍塌。在本文中,我们报告了令人惊讶的经验结果,即简单的孪生网络即使不使用以下任何一种也可以学习有意义的表示:(i)负样本对,(ii)大batchsize,(iii)动量编码器。我们的实验表明,对于损失和结构确实存在坍塌解,但停止梯度操作在防止坍塌方面起着至关重要的作用。我们提供了一个关于停止梯度含义的假设,并进一步展示了验证它的概念验证实验。我们的“SimSiam”方法在ImageNet和下游任务上实现了竞争性结果。我们希望这个简单的基线能够激励人们重新思考孪生网络架构在无监督表示学习中的角色。
对比学习
无监督表示学习的一类方法是基于对比学习。对比学习的核心思想是吸引正样本对,排斥负样本对。
在实践中,对比学习方法得益于大量的负样本。这些样本可以保存在内存库中。在孪生网络中,MoCo维持一个负样本队列,并将一个分支变为动量编码器,以提高队列的一致性。SimCLR直接使用当前批中共存的负样本,并且需要较大的批大小才能正常工作
聚类
无监督表示学习的另一类方法是基于聚类。它们在聚类表示和学习预测聚类分配之间交替进行。
SwAV通过从一个视图计算分配并从另一个视图预测分配,将聚类集成到Siamese网络中,SwAV在平衡分区约束下对每个批进行在线聚类,该问题由Sinkhorn-Knopp变换解决。
动量编码器
BYOL直接从另一个视图预测一个视图的输出。它是一个连体网络,其中一个分支是动量编码器,假设动量编码器对于BYOL避免坍塌很重要,并且报告了移除动量编码器的失败结果,我们的实证研究挑战了动量编码器防止坍塌的必要性。
文章思路
SimSiam 在 MoCo 、 SimCLR 、 SwAV 以及 BYOL 的基础上提出了一个新的对比学习方法,解决了对比学习中模型坍塌、负样本难以构造的问题,且结构简单。同时探讨了不会出现模型坍塌的原因,结论为 stop gradient 的操作对于避免模型坍塌有很大作用。
SimSiam 可以看作,没有负样本的SimCLR、没有在线聚类的SwAV、没有动量编码器的BYOL。
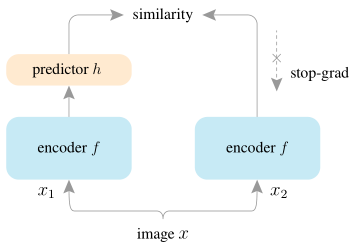
SimSiam的网络结构非常的简单,一张图像,不同的数据增强,通过网络模型相同并且参数相同的encoder,都经过一个predictor来预测对方的输出(上图右边的predictor没画出来),通过MSELoss作为目标函数。

文章中的伪代码看起来也是非常的简洁。其中Z1、Z2作为标签不进行梯度更新。
其中函数D为最小化p1和z2的负余弦相似度
![]()
损失函数为:
![]()
创新点:
- 使用了非常简单的网络结构达到了不错的效果。
- 使用了stop gradient操作使得网络不坍塌。
2.7 MoCov3
本文没有描述一种新的方法。相反,考虑到计算机视觉的进展,它研究了一个直接的、增量的、但必须知道的基线:视觉变压器(ViT)的自我监督学习。虽然标准卷积网络的训练配方已经高度成熟和健壮,但ViT的配方还没有构建,特别是在训练变得更具挑战性的自我监督场景中。在这项工作中,我们回到基本知识,并调查几个基本组件对训练自我监督ViT的影响。我们观察到,不稳定性是降低准确性的一个主要问题,而且它可以被明显好的结果所掩盖。我们发现,这些结果确实是部分失败的,当训练更加稳定时,它们可以得到改善。我们在MoCov3和其他几个自监督框架中对ViT结果进行了基准测试,并在各个方面进行了消融。我们讨论目前积极的证据,以及挑战和开放的问题。我们希望这项工作将为今后的研究提供有用的数据点和经验。

由于MoCov3论文里没有给出网络结构图,只给了伪代码,我们就来看一下这个伪代码。
从伪代码中可以看出,这个结构很像BYOL,上层是一个ViT+proj head+pred mlp,下层是一个动量编码器ViT+proj head,也用的是互相预测来计算损失。
结构很简单,主要就是把ResNet替换成了ViT,精度上升了,但是训练中出现了稳定性问题。
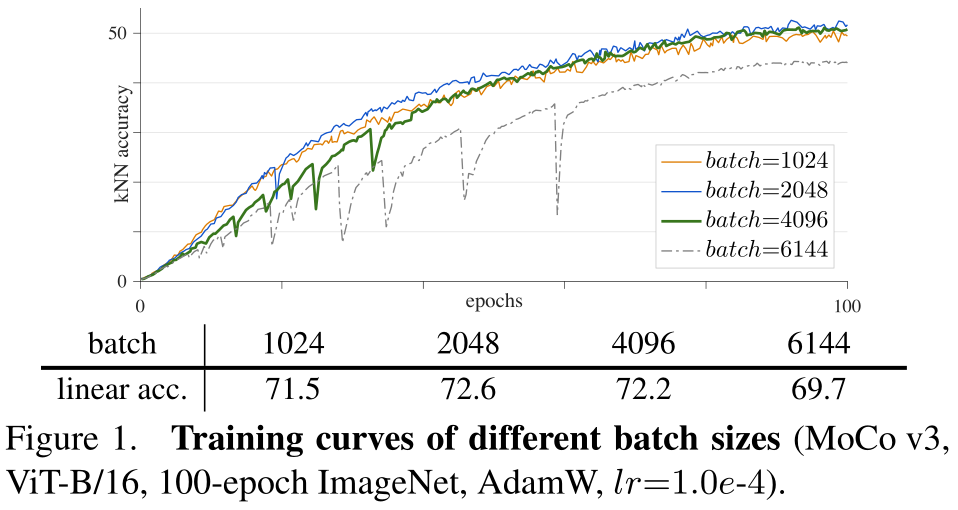
从图中可以发现,模型在训练过程中曲线会出现突然下降的情况,这就说明训练不稳定。
从图中我们还发现batchsize越大,训练越不稳定。
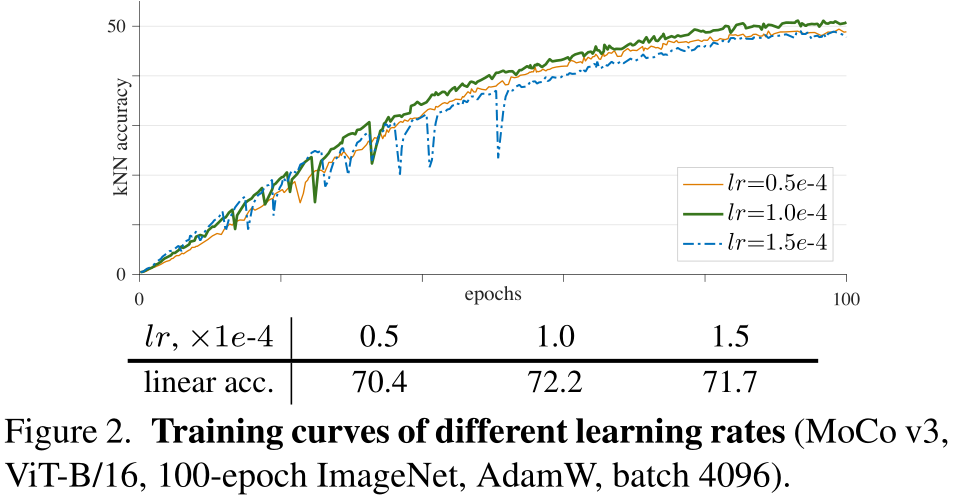
从上可以发现,学习率越大,训练越不稳定。
然后通过做实验观察,作者发现在patch embedding时梯度波动的最明显,当把patch embedding层冻结不学习的时候,训练曲线就比较稳定了。所以作者使用一个固定的随机patch embedding层来嵌入补丁,这是不学习的。
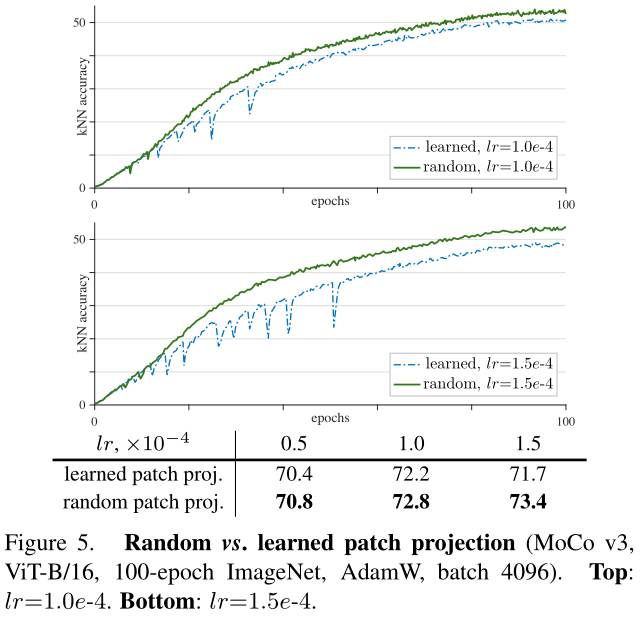
并且在作者做的消融实验中发现,这个技巧在所有这些自我监督框架中都是有效的。
创新点:
- 提出了MoCov3,去掉了队列,加入pred mlp预测另一个输出。
- 提出了一个解决ViT训练不稳的trick,就是冻结patch embedding层,随机初始化,不进行训练。
3. Masked Image Modeling(MIM)方法
以上的方法都是自监督学习当中的对比学习的方法,而接下来的时间都是masked image modeling(MIM)方法了。该方法会随机mask一些图像patch,通过encoder来预测mask掉的部分,使得encoder学习到图像的重要特征。训练完成后将该encoder提取出来作为下游任务的特征提取器。
3.1 BEIT
我们引入了一种自监督视觉表示模型BEIT,它代表来自图像转换器的双向编码器表示。继BERT 在自然语言处理领域的发展之后,我们提出了一个掩膜图像建模任务来预训练视觉变形器。具体来说,在我们的预训练中,每个图像都有两个视图,即image patches(如16×16像素)和visual tokens(即离散tokens)。我们首先将原始图像“tokenize”为visual tokens。然后我们随机屏蔽一些图像块并将它们输入主干ViT。预训练的目标是基于损坏的图像补丁恢复原始的visual tokens。在预训练BEIT后,我们通过在预训练的编码器上附加任务层来直接微调下游任务的模型参数。在图像分类和语义分割方面的实验结果表明,我们的模型取得了与之前的预训练方法相当的效果。
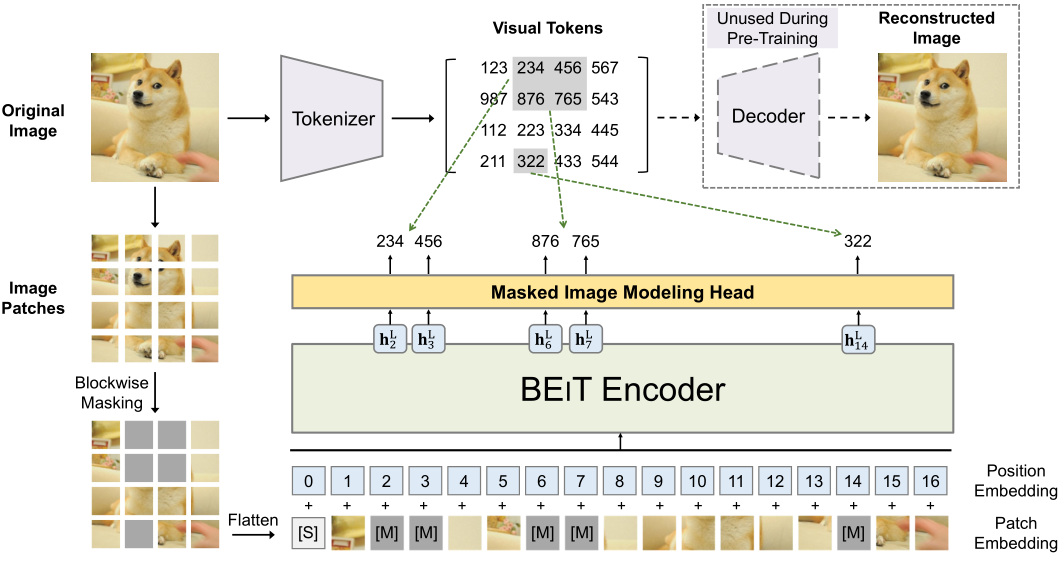
上图就是BEiT的网络结构图。首先,作者模仿NLP中的词汇表建立了一个包含3000种类别的code book,每一个图像块都可以被归为这3000类别中的一类。原始图像先经过tokenizer得到了每个图像块的code作为图像块分类任务的标签。然后就是常规的ViT操作,只不过会mask一些patch。最后网络会输出一个预测值,预测每个mask在codebook中的类别。将预测值与标签对比就得到了损失,整个网络就训起来了。
上面tokenizer其实是一个编码器,是作者通过dVAE离散变分自编码器预训练出来的。
MIM 主要受到 MLM 的启发,MLM 是 NLP 中最成功的预训练 objective 之一。此外,blockwise (或 n-gram) masking 也被广泛应用于 BERT-like 模型。然而,直接使用像素级 auto-encoding (即恢复 masked patches 的像素) 进行视觉预训练,会 pushes 模型聚焦于短程依赖和高频细节。BEiT 通过预测离散视觉 tokens 来克服上述问题,并将细节 summarizes 高级抽象。第 3.3 节的消融研究表明,BEiT 明显优于像素级 auto-encoding。
创新点:
- 提出了MIM代理任务,并且使用了ViT作为backbone。
- 使用离散变分自编码器来编码图像,得到每个图像块的code。
3.2 MAE
本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习算法。我们的MAE方法很简单:我们屏蔽输入图像的随机补丁并重建缺失的像素。它基于两个核心设计。首先,我们开发了一个非对称编码器-解码器架构,其中一个编码器仅对补丁的可见子集(没有掩码令牌)进行操作,以及一个轻量级解码器,该解码器从潜在表示和掩码令牌重建原始图像。其次,我们发现掩盖输入图像的高比例,例如75%,产生了一个重要的和有意义的自我监督任务。这两种设计的结合使我们能够高效地训练大型模型:我们加速了训练(3倍或更多)并提高了准确性。我们的可扩展方法允许学习泛化良好的大容量模型:例如,在仅使用ImageNet-1K数据的方法中,vanilla ViT-Huge模型达到了最好的准确率(87.8%)。下游任务的迁移性能优于监督预训练,并显示出有希望的缩放行为。
关于MAE我推荐这篇博文:MAE(Masked Autoencoders) 详解_mae式模型-CSDN博客(讲的非常好)
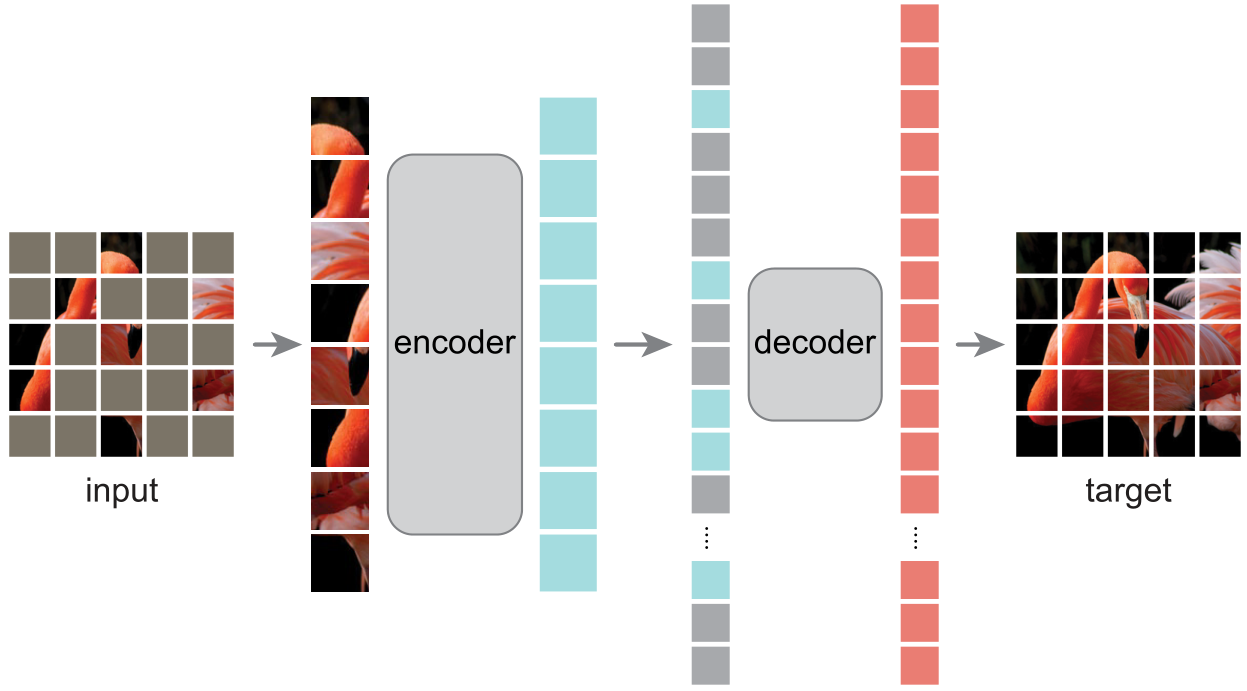
以上就是MAE的网络结构,非常简洁,但是细看也有很多的设计细节。
- MAE设计了一个非对称的编码器-解码器结构。编码器仅仅对可见的patches进行编码,不对mask tokens进行任何处理,解码器将编码器的输出(latent representation)和mask tokens作为输入,重构image。
- MAE中encoder和decoder的模型大小也不一样,因为最后我们只需要encoder作为我们的特征提取器,所以作者把encoder设计的很大,而decoder就又浅(网络深度浅)又瘦(通道数少)。
- MAE的mask比例很高,效果最好的是mask75%,mask的多少决定了预训练代理任务是否具有足够的挑战性,从而影响着 Encoder 学到的
潜在特征表示 以及Decoder 重建效果的质量。 - MAE是直接重建mask patches的像素值,整个流程简单朴素。
除了从图中发现的一些细节外,训练过程中也有很多细节。
- patch 在图像中是服从
均匀分布来采样的,这样能够避免潜在的“中心归纳偏好”(也就是避免 patch 的位置大多都分布在靠近图像中心的区域)。 -
Decoder 不仅需要处理经过 Encoder 编码的 un-masked 的 tokens,还需要处理 masked tokens。但请注意,masked token 并非由之前 mask 掉的 patch 经过 embedding 转换而来,而是可学习的。所有 masked patches 都共享的1个向量,对,仅仅就是1个!其中,不同的mask patch通过position embedding来区分。,每个mask token都是由一个共享参数的向量+position embedding构成的。
-
MAE 预训练任务的目标是
重建像素值,并且仅仅是 masked patches 的像素值,也就是仅对 mask 掉的部分计算 loss,而 loss 就是很大众的 MSE。具体方式就是将每个masked tokens通过一个全连接层,输出为一个patch的所有像素值(P*P*C),target是mask部分的原始像素值,与预测结果算MSE loss。 -
作者提到使用
归一化的像素值作为 target 效果更好,能够提升学到的表征的质量。这里的归一化做法是:计算每个 patch 像素值的均值与标准差,然后用均值与标准差去归一化对应的 patch 像素。
创新点:
- 使用了一个非对称的编码-解码网络。
- 使用更加轻量级的解码器。
- mask比例高达75%。
3.3 SimMIM
SimMIM和MAE发布时间仅仅相隔一周,而且也都是做像素重建的,只能说太卷了。
SimMIM是一种简单的MIM框架。我们简化了最近提出的相关方法,而不需要特殊的设计,例如通过离散VAE或聚类进行块屏蔽和标记化。为了研究是什么使MIM任务学习到良好的表征,我们系统地研究了框架中的主要组件,并发现每个组件的简单设计都揭示了非常强的表征学习性能:
1)用中等大小的mask patches(例如,32)随机mask输入图像,使其成为强大的文本前任务;
2)直接回归预测原始像素RGB值的效果不差于设计复杂的patch分类方法(如BEiT);
3)预测头可以像线性层一样轻,性能不差于较复杂的层。
使用ViT-B,我们的方法通过在该数据集上进行预训练,在ImageNet-1K上达到了83.8%的top-1微调精度,比之前的最佳方法高出0.6%。当应用于一个更大的模型,大约有6.5亿个参数SwinV2H时,仅使用ImageNet-1K数据,它在ImageNet-1K上达到87.1%的top-1精度。我们还利用这种方法来解决大规模模型训练所面临的数据匮乏问题,即3B模型(SwinV2-G)被成功训练,使用比以前的实践(JFT-3B)少40倍的标记数据,在四个代表性视觉基准上达到最先进的精度。
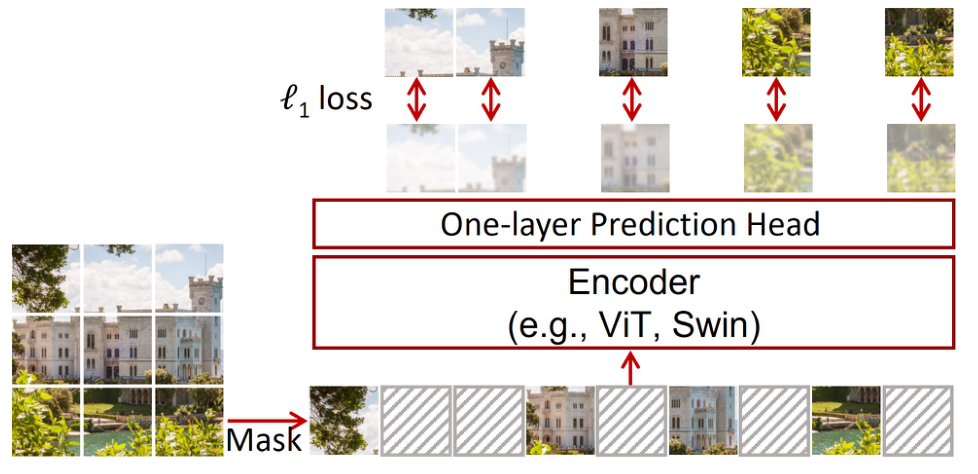
SimMIM的网络结构图可以说是相当简陋了,就是一个ViT结构,并且从图上来看也没有什么好说的,接下来说说文章中提到的一些网络训练时的细节。
- SimMIM只重建 masked patches,而MAE的decoder则是重建了全部patches。
- SimMIM把mask patches替换成了可学习的mask token向量输入到encoder中,而MAE的encoder直接舍弃了mask patches。
- SimMIM的mask size为32*32。
- Prediction head的输入为encoder输出,输出为重建的像素,也就是将输出的特征图映射到与原始图像相同的分辨率,比如输出一个mask patches的特征图shape为(w,h,c),那我们就通过1*1卷积映射到(32*32*3)这个维度上去。
说实话,SimMIM整体来说结构还是非常清晰明了的。
创新点:
- 使用MIM方法重建RGB像素。
- mask size更大,效果会更好。
- SimMIM之重建mask patches。
- 使用encoder提取特征后,仅仅使用一个简单的prediction head效果就非常好了。
3.4 MaskFeat
我们提出了用于视频模型自监督预训练的屏蔽特征预测(MaskFeat)。我们的方法首先随机屏蔽一部分输入序列,然后预测被屏蔽区域的特征。我们研究了五种不同类型的特征,发现直方图定向梯度(HOG),一种手工制作的特征描述符,在性能和效率方面都表现得特别好。我们观察到HOG中的局部对比度归一化对于良好的结果至关重要,这与早期使用HOG进行视觉识别的工作是一致的。我们的方法可以学习丰富的视觉知识,并驱动大规模的基于变压器的模型。在不使用额外的模型权重或监督的情况下,MaskFeat在未标记视频上进行预训练,在Kinetics-400上使用mviti - l获得了前所未有的86.7%的结果,在kinetics - 600上获得了88.3%的结果,在Kinetics-700上获得了80.4%的结果,在AVA上获得了39.8 mAP,在SSv2上获得了75.0%的结果。MaskFeat进一步推广到图像输入,可以将其解释为单帧视频,并在ImageNet上获得具有竞争力的结果。
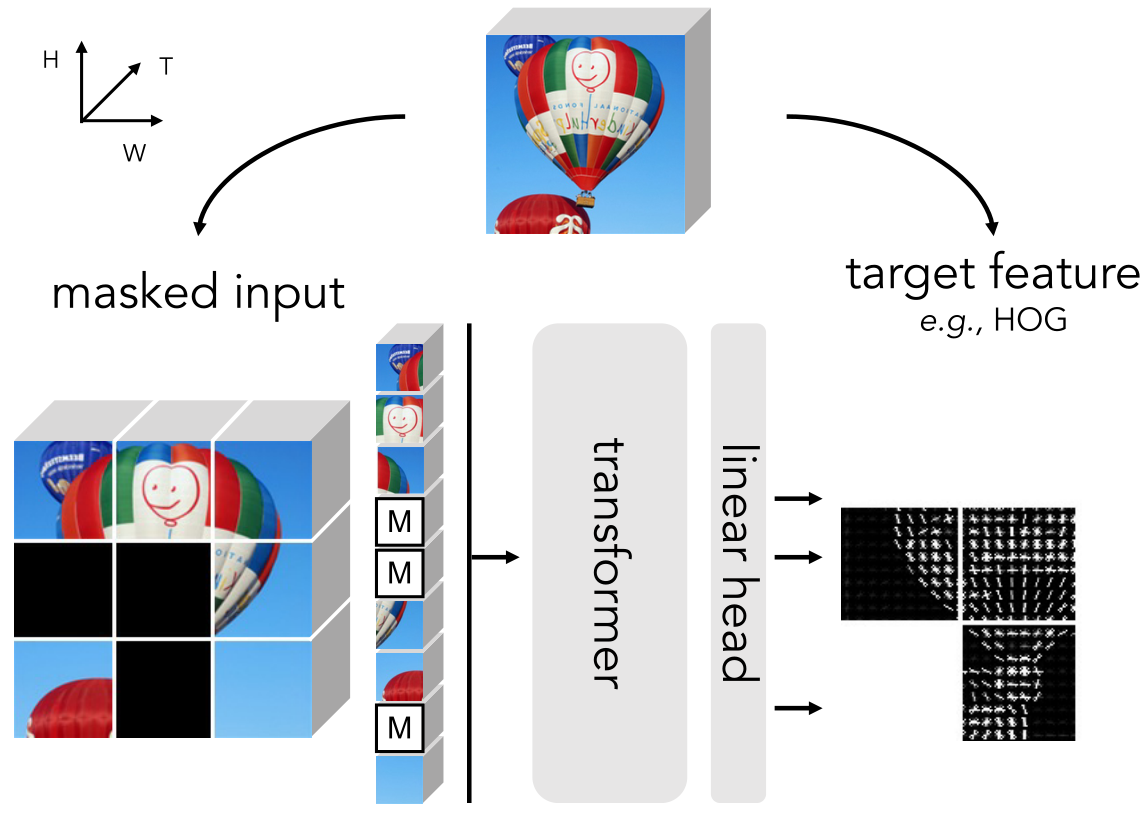
MaskFeat最核心的改变就是将MAE对图像像素(pixel)的直接预测,替换成对图像的方向梯度直方图(HOG)的预测。
那为什么预测图像的HOG比直接预测像素更好呢?
像素作为预测目标,有一个潜在的缺点,那就是会让模型过度拟合局部统计数据(例如光照和对比度变化)和高频细节,而这些对于视觉内容的解释来说很可能并不是特别重要。
相反,方向梯度直方图(HOG)是描述局部子区域内梯度方向或边缘方向分布的特征描述符,通过简单的梯度滤波(即减去相邻像素)来计算每个像素的梯度大小和方向来实现的。
这次,MaskFeat引入HOG,其实正是将手工特征与深度学习模型结合起来的一次尝试。
MaskFeat首先随机地mask输入序列的一部分,然后预测被mask区域的特征。
从MaskFeat的网络结构图来看,几乎和SimMIM一模一样,只不过把预测的目标替换成了mask patches的HOG图像。
创新点:
- 将重建目标改为了输入图像的HOG图像。
3.5 CAE
我们提出了一种新的掩模图像建模(MIM)方法,上下文自编码器(CAE),用于自监督表示预训练。我们通过在编码的表示空间中进行预测来预训练编码器。预训练任务包括两个任务:掩模表示预测—预测掩模块的表示,以及掩模块重建—重建被掩模块。
该网络是一个编码器-回归器-解码器架构:编码器将可见的patch作为输入;回归量使用可见补丁的表示以及可见和被掩盖的补丁的位置来预测掩码补丁的表示,该掩码补丁预计将与从编码器计算的表示对齐;解码器根据预测的编码表示重建掩码补丁。CAE设计鼓励将学习编码器(表示)与完成相关任务分离:掩码表示预测和掩码补丁重建任务,并且在编码的表示空间中进行预测经验地显示了表示学习的好处。我们通过在下游任务(语义分割、对象检测和实例分割以及分类)中优越的传输性能证明了我们的CAE的有效性。
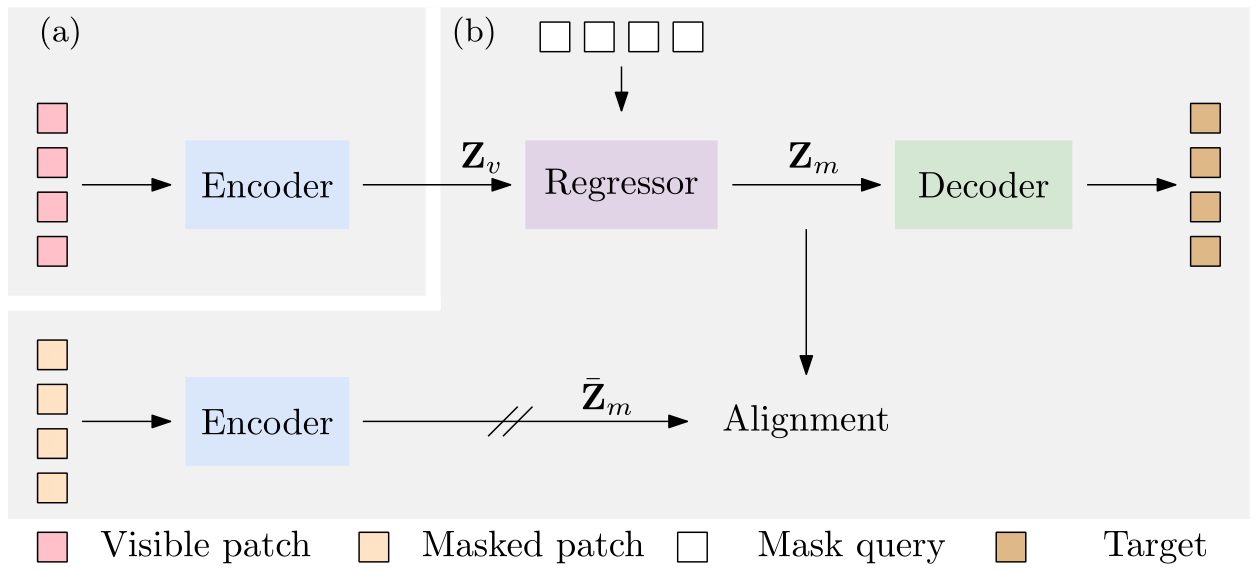
上图是CAE的结构,a部分输入没有被mask的patches,输出没有被mask的patches的特征Zv。Zv和带位置信息的可学习的mask tokenes输入到回归器中,输出预测的mask patches的特征Zm。Zm与下面提取出的mask patches的特征进行比较算loss。Zm还经过decoder输出重建的mask patches的像素进行回归。
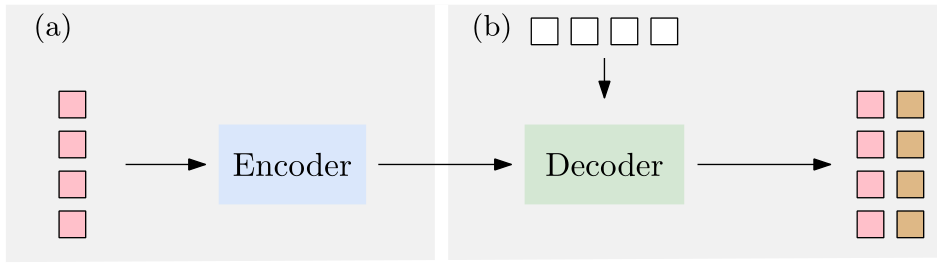
下图是CAE论文中MAE的结构,
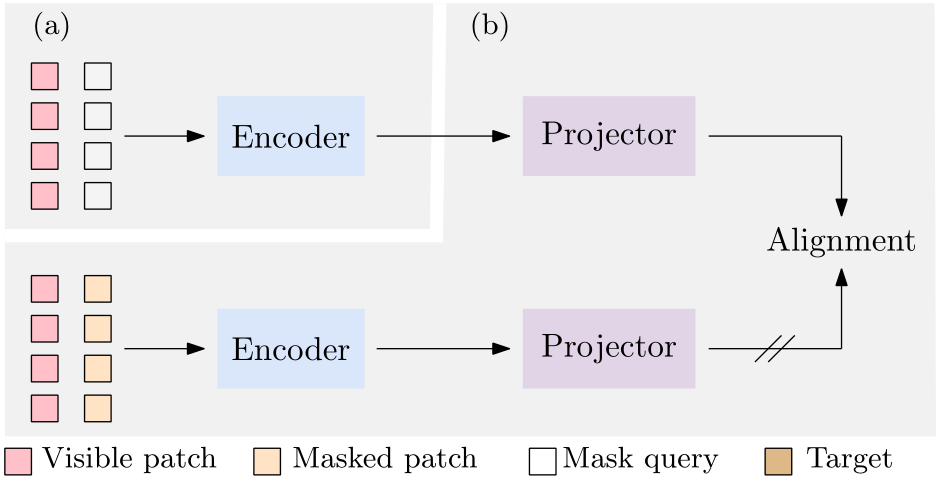
下图是CAE论文中iBoT的结构。
创新点:
- 将掩码表示预测和掩码补丁重建任务分开。
- 利用了mask patches的信息。
3.6 iBoT
语言Transfomer的成功主要归功于掩码语言建模(MLM)的代理任务,其中文本首先被标记为语义上有意义的片段。在这项工作中,我们研究了蒙面图像建模(MIM),并指出了使用语义上有意义的visual tokenizer的优点和挑战。我们提出了一个自监督框架iBOT,它可以使用 online tokenizer执行mask预测。具体来说,我们对mask patch token进行自蒸馏,并将教师网络作为 online tokenizer,同时对class token进行自蒸馏以获得视觉语义。 online tokenizer与MIM目标是可联合学习的,并且省去了需要预先对tokenizer进行预训练(BEiT)的多阶段训练管道。我们通过在ImageNet1K上评估获得82.3%的线性探测精度和87.8%的微调精度来显示iBOT的突出性。除了最先进的图像分类结果之外,我们还强调了新兴的局部语义模式,这有助于模型获得强大的鲁棒性,以抵御常见的损坏,并在密集的下游任务上取得领先的结果,例如对象检测、实例分割和语义分割。
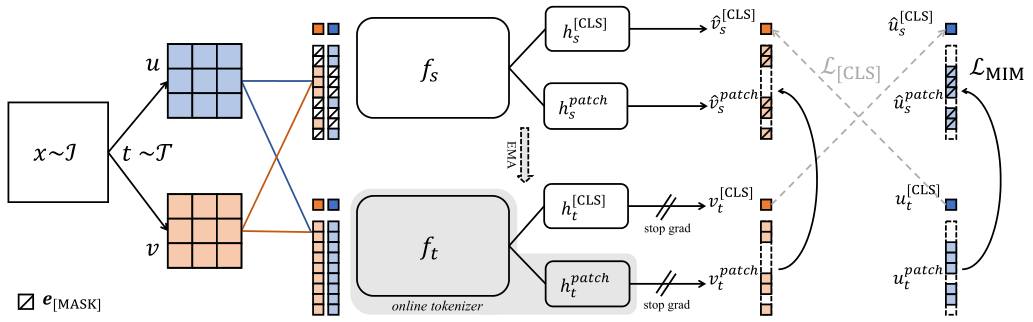
上图为iBoT的网络结构图。可以看出这个结构图里面有好几个模型的影子,上下两个视角的SimCLR,stop grad的SimSiam等等,使用了两个loss,一个是cls Loss,一个是MIM loss,这相当于将对比学习和MIM结合起来了。
创新点:
- 结合了对比学习的思想来做MIM任务。
- 利用了mask patches的信息。
3.7 MILAN
在过去的几年中,基于自关注的变压器模型一直主导着许多计算机视觉任务。
它们卓越的模型质量在很大程度上依赖于超大的标记图像数据集。为了减少对大型标记数据集的依赖,基于重建的掩码自编码器越来越受欢迎,它从未标记的图像中学习高质量的可转移表示。出于同样的目的,最近的弱监督图像预训练方法从图像附带的文本标题中探索语言监督。在这项工作中,我们提出了基于语言辅助表示的蒙面图像预训练,称为MILAN。我们的预训练目标不是预测原始像素或低级特征,而是用使用标题监督获得的大量语义信号重建图像特征。此外,为了适应我们的重建目标,我们提出了一个更有效的提示解码器架构和语义感知掩码采样机制,进一步提高了预训练模型的传输性能。实验结果表明,该方法比以往的方法具有更高的精度。当蒙面自动编码器在输入分辨率为224×224的ImageNet-1K数据集上进行预训练和微调时,MILAN在viti - base上达到了85.4%的前1精度,比之前的最先进水平高出1%。在下游语义分割任务中,MILAN在ADE20K数据集上使用viti - base实现了52.7 mIoU,比之前的掩码预训练结果高出4个点。
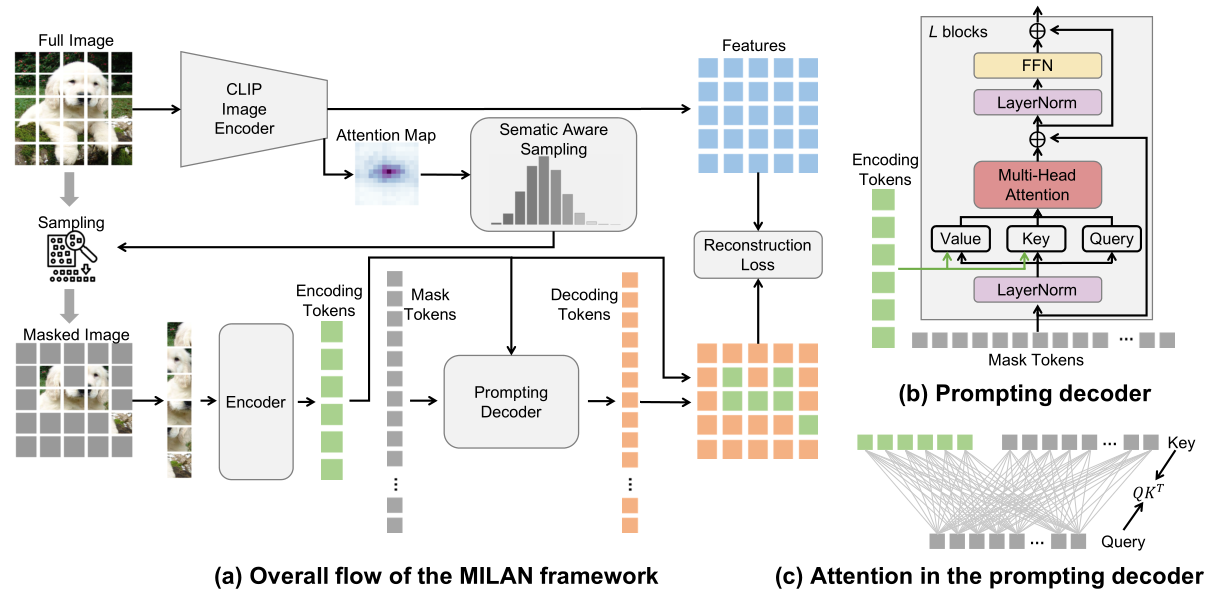
上图为MILAN的网络结构图。(a)掩码自编码器使用CLIP模型的输出作为重建目标。一个高效的prompting decoder会冻结encoding tokens的特性,只更新mask tokens。使用semantic aware sampling来指导unmasked image patches的选择。重构损失是根据masked and unmasked patches的表示特征计算的。(b)prompting decoder的详细图。(c)prompting decoder中的注意力计算。
创新点:
- 使用CLIP Image Encoder提取的图像特征作为重构的目标。
- 重构损失计算的是unmask和mask的patches的特征。
3.8 BEiTv2
观点:大多数现有的研究都是针对低级图像像素的,这阻碍了对表示模型的高级语义的开发。
改进:使用语义丰富的 visual tokenizer 作为 masked 预测的重建目标,为将MIM从像素级提升到语义级提供了一种系统的方法。
具体:vector-quantized 的知识提取来训练 tokenizer ,该 tokenizer 将连续的语义空间离散化为紧凑的代码。然后,我们通过预测 masked image patches 的原始 visual tokens 来预训练视觉 Transformers 。
效果:在图像分类和语义分割方面的实验表明,BEITV2优于所有比较的MIM方法。在ImageNet-1K(224尺寸)上,基本尺寸BEIT V2实现了85.5%的微调精度和80.1%的线性预测精度。大尺寸BEIT V2 微调中top-1准确率 87.3%,在ADE20K上mIoU 56.7%。
现有的MIM方法可以根据重建目标大致分为三类:
- 低级图像像素(例如,MAE;CIM)
- 手工特征(例如,HOG特征;MaskFeat)
- visual tokens : BEiT; PECO;
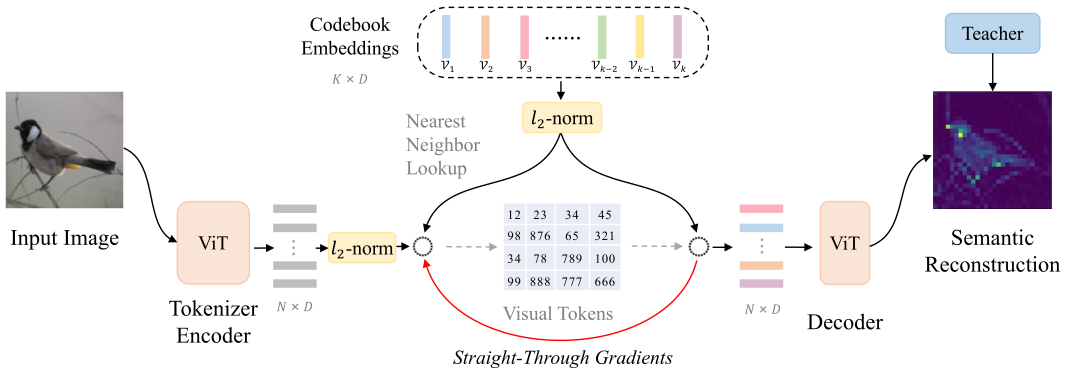
上图为BEiT中的visual tokens预训练网络结构图,训练好后提取出Tokenizer encoder,输入图像经过Tokenizer encoder得到visual tokens,并将其作为MIM head重建的target。
下图为MIM预训练网络的主干,MIM head重建的对象就为上图得到的visual tokens。
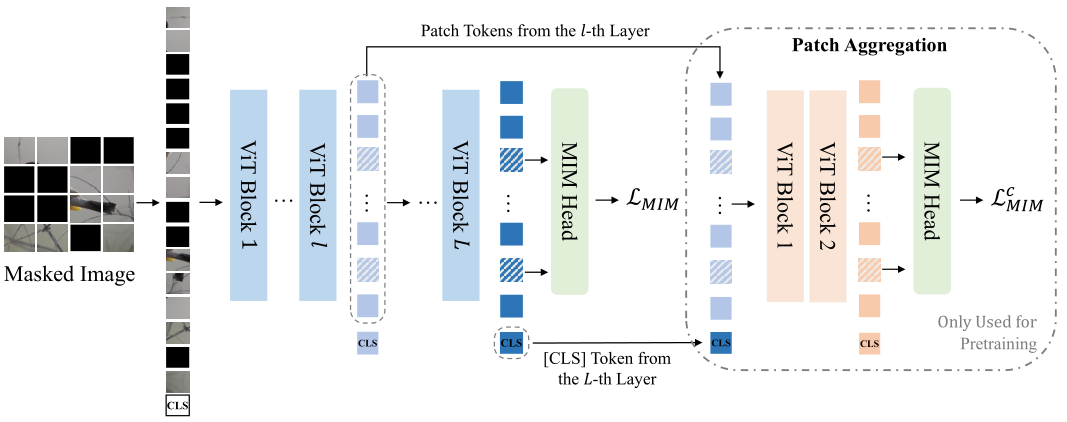
创新点:
- 提出了 Vector-Quantized 知识蒸馏,将MIM从像素级提升到语义级,用于自监督表示学习。主要体现在visual tokens预训练网络的过程中,重建的是语义图像。
- 引入了一种 patch 聚合策略,该策略在给定离散语义 token 的情况下强制执行全局结构,并提高了学习表示的性能。
3.9 EVA
推荐博文:【自监督论文阅读笔记】EVA: Exploring the Limits of Masked Visual Representation Learning at Scale-CSDN博客
本文推出了 EVA,这是一个以视觉为中心的基础模型,旨在仅使用可公开访问的数据来探索大规模视觉表示的局限性。EVA 是一种经过预训练的普通 ViT,用于重建 以可见图像块为条件的屏蔽掉的图像-文本对齐(image-text aligned)的视觉特征。通过这个前置任务,我们可以有效地将 EVA 扩展到 10 亿个参数,并在图像识别、视频动作识别、目标检测、实例分割和语义分割等广泛的代表性视觉下游任务上创造新记录,而无需大量监督训练。
此外,我们观察到 缩放 EVA 的量变导致迁移学习性能的质变,这在其他模型中是不存在的。例如,EVA 在具有挑战性的大词汇量实例分割任务中取得了巨大飞跃:本文的模型在具有超过一千个类别的 LVISv1.0 数据集和只有八十个类别的 COCO 数据集上实现了几乎相同的最先进性能。
除了纯粹的视觉编码器,EVA 还可以作为 以视觉为中心的多模态的支点 来连接图像和文本。我们发现从 EVA 初始化巨型 CLIP 的视觉塔可以 以更少的样本和更少的计算 极大地稳定训练 并优于从头开始的训练,为 扩大 和 加速 多模态基础模型的昂贵训练 提供了新的方向。为了方便未来的研究,本文发布了所有代码和十亿规模的模型。
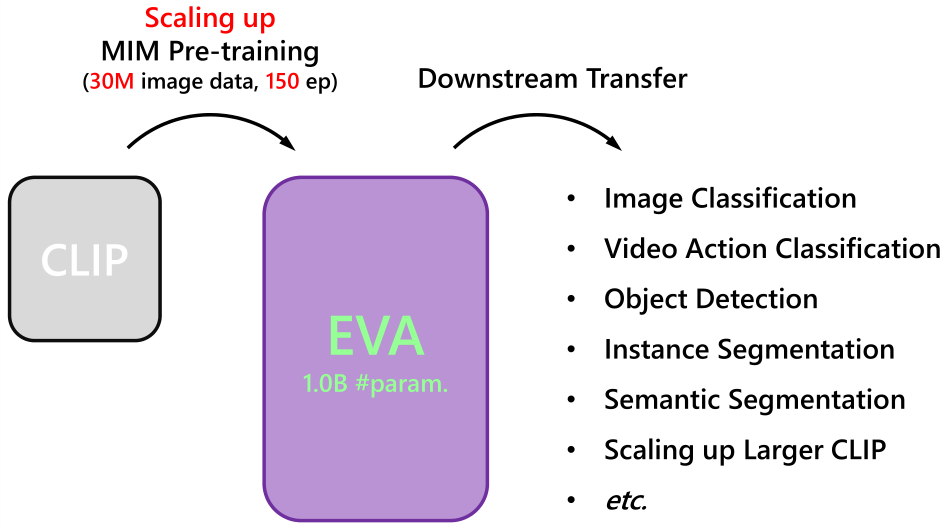
基于之前的视觉预训练模型研究工作,有两个主流方案:
- 重建masked out tokenized semantic vision features(BEiT系列)。
- 重建来自大规模预训练模型蒸馏的特征(Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation);
两者都使用了预先训练图像文本对齐的视觉特征。通过下面的一些实验,可以发现CLIP的特征标记化对于好的下游任务表现不是必须的;随着预训练时间延长,重建蒸馏特征并不能带来一致的性能增益。作者发现简单地重建以可见图像块为条件的masked图像文本对齐视觉特征,效果更好。
也就是说EVA直接用CLIP的image encoder输出的特征作为重建的目标。EVA输出特征首先归一化,然后通过线性层映射成CLIP特征相同的维度。使用negative cosine similarity作为损失函数。
创新点:
- 重建目标来自使用224×224像素图像训练的OpenAI CLIP-L/14视觉encoder。
3.10 MixMIM(or MixMAE)
在本研究中,作者提出了混合(Mixed)和掩蔽(Masked)图像建模(MixMIM),这是一种简单但有效的MIM方法,适用于各种层次的视觉Transformer。现有MIM方法将输入token的随机子集替换为一个特殊的[MASK]符号,目的是从损坏的图像重建原始图像token。然而,作者发现使用[MASK] token会大大减慢训练速度,并由于较大的掩蔽率(例如,BEiT中的40%),会导致训练和微调不一致。相反,作者将一个图像的mask token替换为另一个图像的视觉token,即创建一个混合图像。然后,作者进行双重重建,从混合输入中重建原始两幅图像,这显著提高了效率。虽然MixMIM可以应用于各种架构,但本文探索了一种更简单但更强大的层次Transformer,并使用MixMIM-B、-L和-H进行缩放模型。实验结果表明,MixMIM可以有效地学习高质量的视觉表示。
自注意操作有一个全局感受野,每个token都可以和其他token交互。完全融合两个部分图像的token也会导致预训练和微调的差异,因为这两组token可能来自外观显著不同的图像。为了避免引入新的差异,MixMIM使用了一种掩蔽注意机制来明确防止两组token之间的交互。此外,作者在层次编码器的不同阶段通过最近插值对混合掩码进行上采样,以匹配attention map的分辨率。
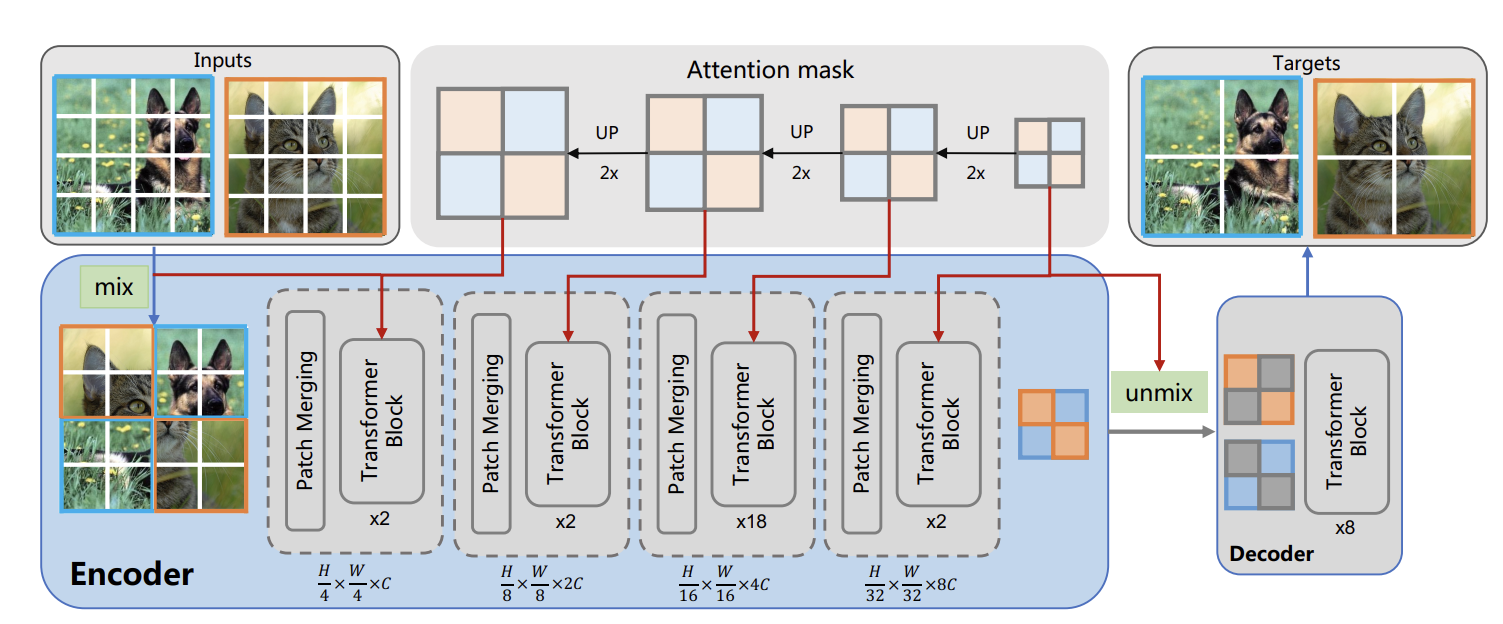
上图为MixMIM的网络结构图。乍一看感觉很牛逼,使用数据集里的图像代替mask,但是仔细一看,特征提取过程还加了一个attention mask, 相当于只对同一张图像里面的部分做自注意力,这不就是两张图象的MAE过程合并到一起了吗?离谱,这也能发CVPR?
还是讲一下模型吧,就是随机选两张图象,混合起来输入进网络中,然后通过attention mask自己算自己图像的自注意力,attention mask上采样来匹配每一个阶段的Transfomer Block,encoder部分输出提取的特征,然后把两个图像分开,这里不知道是和MAE一样填充mask token还是就只有visual token,反正将分开的两个图象输入进decoder中,输出为两个图象,也就是说重建两个图象的低级像素特征。
创新点:
- 使用数据集中的其他图像来代替mask部分。
- 同时重建两个图像的像素。
3.11 PixMIM
随着掩模自编码器(MAE)和自编码器(BEiT)的出现,掩模图像建模(MIM)取得了可喜的进展。然而,随后的工作使框架变得复杂,有了新的辅助任务或额外的预训练模型,不可避免地增加了计算开销。本文从像素重建的角度对MIM进行了基本分析,研究了输入图像补丁和重建目标,并强调了两个关键但之前被忽视的瓶颈。在此基础上,我们提出了一种非常简单有效的方法PixMIM,该方法采用两种策略:
1)从重建目标中过滤高频成分,以减轻网络对纹理丰富细节的关注;
2)采用保守的数据增强(主要因为随机裁剪造成的前景丢失)策略,以减轻MIM训练中前景缺失的问题。
PixMIM可以很容易地集成到大多数现有的基于像素的MIM方法中(即,使用原始图像作为重建目标),而无需额外的计算。我们的方法在不同的下游任务中持续改进了三种MIM方法:MAE、ConvMAE和LSMAE。我们相信这种有效的即插即用方法将作为自我监督学习的强大基线,并为未来改进MIM框架提供见解。
1、重建目标
现阶段,大多数MIM方法与MAE一样,将原始的像素值作为重建目标,这使得网络需要对masked patchs有优秀的重建能力,包括复杂的细节纹理。这种重建目标使得网络浪费建模能力来关注短期依赖和高频细节。而本文认为在 MIM 任务中,模型应该更关注浅层特征,即形状偏置。
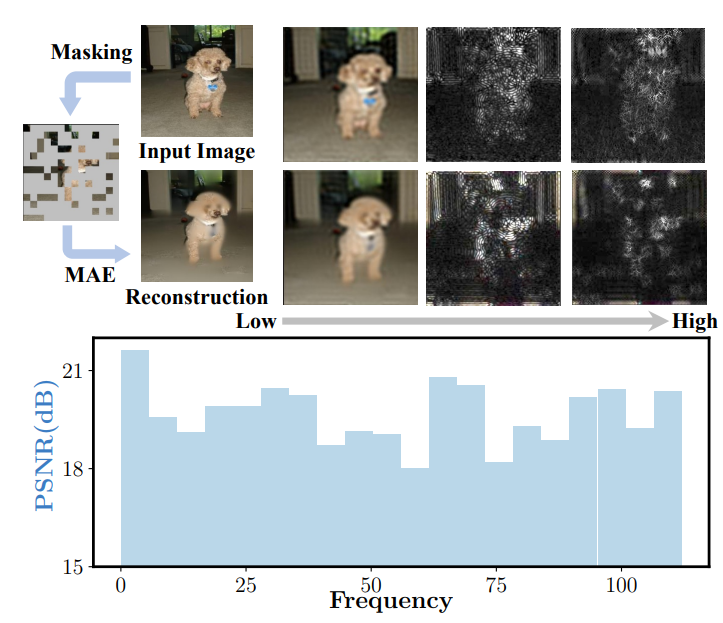
2、输入patchs
MAE中使用Random Resized Crop作为数据增强手段,但是,当结合RRC和高掩码率技巧时,MAE输入的patchs平均只占整体目标的17.1%。语义丰富的前景对于模型学习到好的特征是至关重要的。在训练过程中,较低的前景模型收敛会阻碍模型学习形状偏差。

现在的MIM模型的重建目标,不可避免地会引入texture biases,偏离了之前工作地初衷,可能损害representation质量。与之对应的是,模型应该在重建目标中弱化high-frequency分量。
如下图所示,作者为了评估MIM算法中输入patchs中包含目标的百分比,提出了以下的重叠面积计算公式。图中A1为原图中目标的区域,A2为裁剪后图像中目标的区域,A2和A1的比值可以得出占比。

作者发现,在MAE算法中,当使用RRC数据增强后,比值为68.3%,RRC结合掩码之后,占比只有17.1%,说明MAE的输入中缺乏有效的前景信息。如DeiT Ⅲ中提出的:前景相对于背景能编码更多语义信息,缺乏前景信息会导致在下游任务中优化欠佳。因此,需要一个简单的方法来保留更多的前景信息。
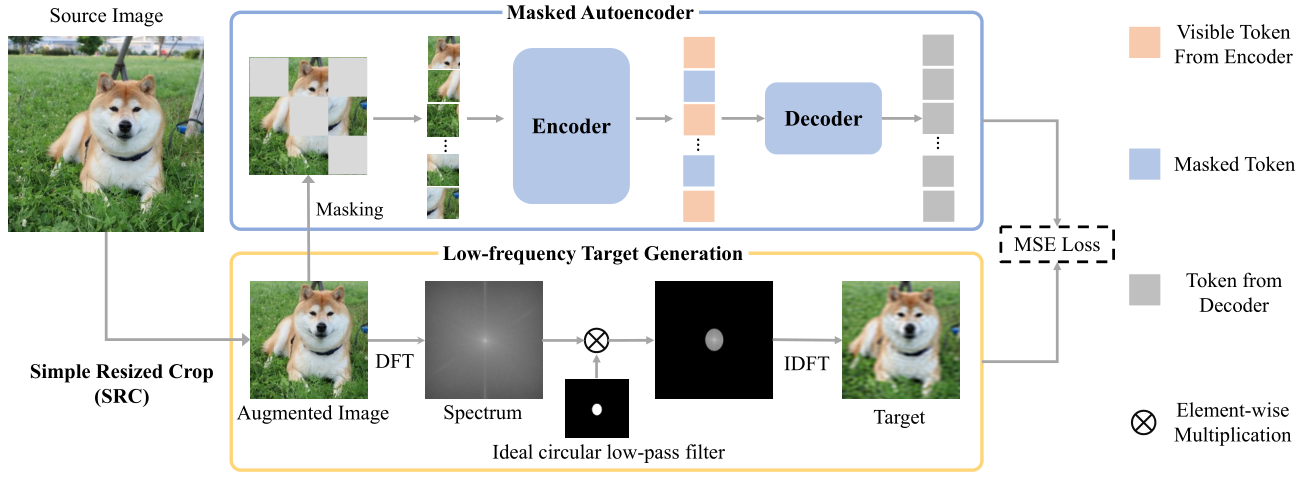
上图为PixMIM的网络结构图,通俗易懂,就两点,第一,将数据增强时的random crop换成了simple resize crop,第二,将模型重建的目标改为了去除了高频信息的输入图像。
生成Low-frequency重建目标
为了削弱模型学习到texture为主导的high-frequency细节信息,提出了一个新的目标生成器decoder,生成的目标依旧是RGB像素值,但是过滤掉了high-frequency分量。
具体而言,生成low-frequency目标分为如下三步:
- domain conversion from spatial to frequency(空间域到频率域的转换),使用2D 离散傅里叶变换;
- low-frequency components extraction(低频成分提取)。在频谱Fdft(Ii)上应用了理想的低通滤波器Flpf。理想的低通滤波器定义为:
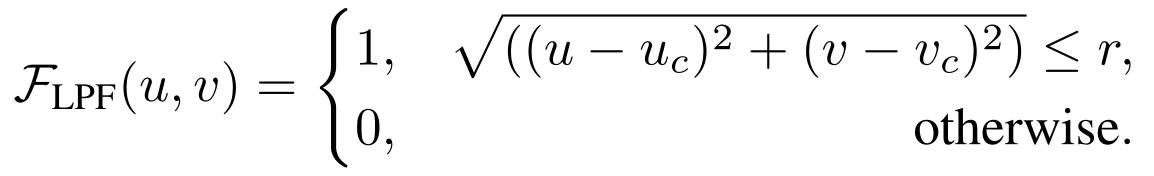
- reconstruction target generation from frequency domain(频域重建目标生成)。我们对滤波后的频谱进行离散傅立叶反变换(IDFT) FIDFT,生成RGB图像作为最终重建目标。
更加保守的数据增强方案
为了更好的保留输入前景信息,没有修改高掩码方式,而是提出了一个更加保守的数据增强方案。
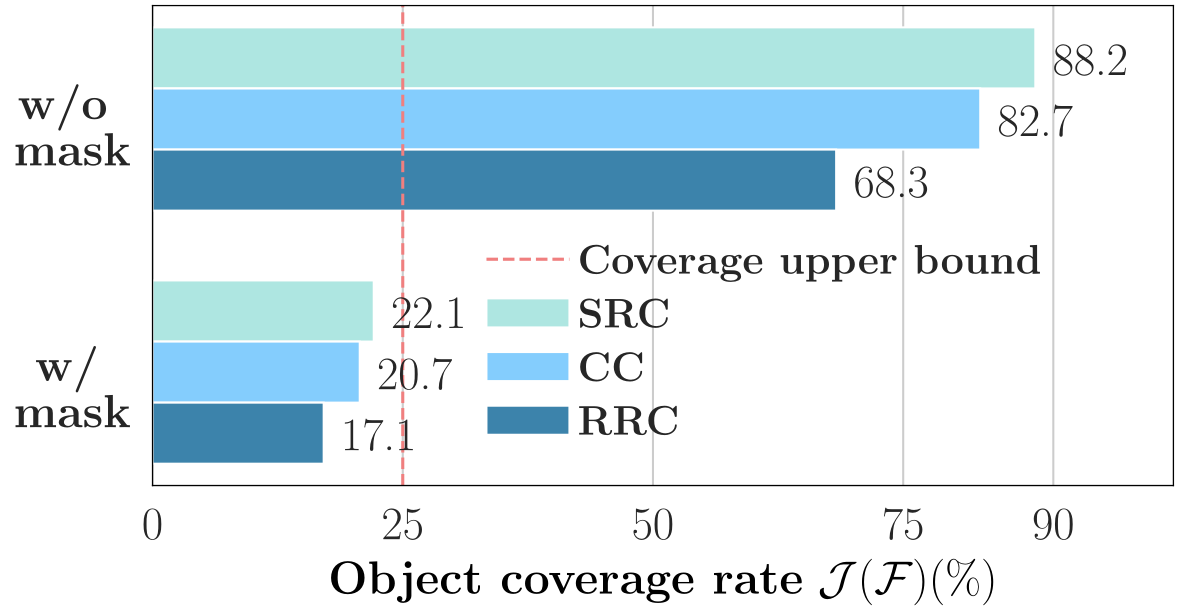
对象覆盖分析。即使在MAE的高屏蔽策略下,SRC仍然比RRC和CC保持更高的比例。注意,当应用MAE的掩蔽策略时,目标覆盖率的上限为25%。(RRC:随机调整裁剪,SRC:简单调整裁剪,CC:中心裁剪)
Simple Resized Crop(SRC),最先在AlexNet中被使用,具体做法是先将最短边resize到输入大小,然后在两侧应用 4 像素的反射填充,最后随机裁剪一个输入大小的区域。
CenterCrop(CC),就是从图像中间裁剪一个固定大小的区域。
最后可以看到SRC的前景占比为22.1%,非常接近25%(掩码率为75%)。
创新点:
- 采用了更好的图像裁剪策略来解决前景丢失的问题。
- 将重建目标改为了低频图像,减少网络对于纹理细节等冗余信息的学习。
4. 总结
对比学习:
- 一开始主要是个体判别代理任务,每一个图像都是一个类,除了数据增强的图像外都是负样本,所以在对比学习的初期就是在解决负样本数量的问题,SimCLR的batchsize太大,memory bank的特征差异又大,所以出现了moco使用动量编码器和队列来解决问题。
- 然后发现数据增强对效果影响挺大,并且特征提取器后面的projection head也非常重要。
- 随后BYOL被提出来,不需要负样本也可以训练。BYOL是用一张图像来预测另一个数据增强不同的图像的特征。
- SwAV结合了聚类到对比学习方法中,提取后的特征与聚类中心比而不是特征之间想比,并且SwAV使用了交换预测的方法,multi-crop也大大提高了SwAV的性能。
- SimSiam大道至简,用stop-grad停止一个分支的更新,然后两个分支使用相同参数的encoder,最后交换预测。
- MoCov3解决了ViT训练不稳的trick,使用了ViT作为特征提取器。
以上就是对比学习的发展史,总的来说后面发展趋于相近,不使用负样本,动量编码器的使用与否,并使用更强的数据增强(如multi-crop),添加预测层,交叉预测比较。
MIM方法:
MIM其实主要就围绕三个问题,第一个最重要的就是重建的目标,第二个就是encoder的输入是否包括mask tokens,第三个是mask patches的使用。还有就是网络结构,大部分只有encoder,小部分有decoder。
MIM方法中,unmask patches就是没有被遮盖掉的图像块,mask patches是遮盖的图像块,mask tokens是替代mask patches的可学习向量。
- BEiT重建的目标为visual tokens。encoder的输入有mask tokens,并且只重建mask部分。而且需要先训练visual token提取器,再训练BEiT。
- MAE重建目标为低级像素。encoder只输入unmask patches。deocder输入unmask patches fature和mask token,输出与原图一样shape的特征,但是只对mask patches做loss。
- SimMIM重建目标为低级像素。encoder输入包含mask tokens,输出只有mask部分。
- MaskFeat重建的目标为HOG。输入包含mask tokens,输出只有mask部分。
- iBoT将对比学习的思想加入到MIM中,使用数据增强后的两个图像来交叉预测cls,重建的对象为teacher分支输出的特征。iBoT的student分支输入包含mask tokens,输出mask部分的特征,teacher分支输入完整的图像,输出mask部分的特征作为target。iBoT算是首先使用mask patches信息的模型。
- CAE重建的目标为mask部分像素。但是CAE在MAE的基础上加了一个分支,利用了mask patches的信息来回归。有decoder。
- MILAN重建的目标为CLIP image encoder提取的图像特征。encoder只输入unmask patches,decoder输入包含mask tokens,输出整个图像的特征。
- BEiTv2中,visual tokenizer训练的重建目标为语义特征,BEiTv2的重建目标为visual tokens。BEiTv2输入包含mask tokens,输出为预测的visual tokens。
- EVA重建的目标为CLIP image encoder提取的图像特征。EVA输出特征首先归一化,然后通过线性层映射成CLIP特征相同的维度。
- MixMIM重建的目标为两个不同的图像的低级像素。输入为两张不同的图像,其中一张取出mask对应的部分来代替mask。其实就是两张图象的MAE过程合并到一起。
- PixMIM重建的目标为去除了高频信息的图像低级像素。encoder输入不包括mask部分,decoder输入包括mask tokens,输出全部图像像素。
以上就是MIM方法目前为止的发展过程,逐渐多元化,目前还没看到非常相近的趋势。重建的目标可以是低级像素,也可以是处理过的低级像素(HOG,low-frequency等),还有encoder提取出来的特征(如visual tokenizer、CLIP等),有的encoder输入mask tokens,有的decoder输入mask tokens,有的利用了mask patches信息作为输入等等。


















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









