






准备工作
常用的激励函数一般有两种,一种是sigmoid函数,它的值域为 ( 0 , 1 ) (0,1) (0,1),因此这个函数能很好地解释概率方面的意义。另一个函数是tanh函数,它的值域为 ( − 1 , 1 ) (-1,1) (−1,1)。两个函数的形态都差不多,都是S型。
sigmoid函数的形式被定义为:
f
(
z
)
=
1
1
+
exp
(
−
z
)
f(z)=\frac{1}{1+\exp(-z)}
f(z)=1+exp(−z)1
其导数为
f
′
(
z
)
=
f
(
z
)
(
1
−
f
(
z
)
)
f'(z)=f(z)(1-f(z))
f′(z)=f(z)(1−f(z))
tanh函数的形式被定义为:
f
(
z
)
=
t
a
n
h
(
z
)
=
exp
(
z
)
−
exp
(
−
z
)
exp
(
z
)
+
exp
(
−
z
)
f(z)=tanh(z)=\frac{\exp(z)-\exp(-z)}{\exp(z)+\exp(-z)}
f(z)=tanh(z)=exp(z)+exp(−z)exp(z)−exp(−z)
其导数为:
f
′
(
z
)
=
1
−
(
f
(
z
)
)
2
f'(z)=1-(f(z))^2
f′(z)=1−(f(z))2
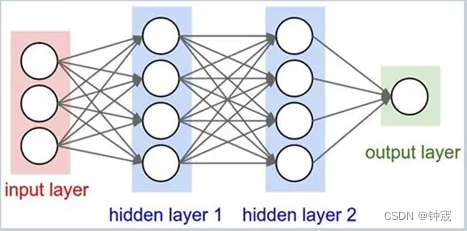
三层BP神经网络前向传导
这里说的三层,是指包含输入层、隐含层、输出层一共为三层。其前向传导可以用公式写为:
a
(
1
)
=
x
z
(
2
)
=
W
(
1
)
a
(
1
)
+
b
(
1
)
a
(
2
)
=
f
(
z
(
2
)
)
z
(
3
)
=
W
(
2
)
a
(
2
)
+
b
(
2
)
a
(
3
)
=
f
(
z
(
3
)
)
\begin{align} a^{(1)} &= x\\ z^{(2)} &= W^{(1)}a^{(1)}+b^{(1)}\\ a^{(2)} &= f(z^{(2)})\\ z^{(3)} &= W^{(2)}a^{(2)}+b^{(2)}\\ a^{(3)} &= f(z^{(3)})\\ \end{align}
a(1)z(2)a(2)z(3)a(3)=x=W(1)a(1)+b(1)=f(z(2))=W(2)a(2)+b(2)=f(z(3))
其中,x为输入特征,
a
(
1
)
a^{(1)}
a(1)为输入层。
W
(
1
)
W^{(1)}
W(1)和
b
(
1
)
b^{(1)}
b(1)为输入层到隐层映射时的参数。
z
(
2
)
z^{(2)}
z(2)是未被激活的隐层节点。
a
(
2
)
a^{(2)}
a(2)为激活了的隐层节点。
W
(
2
)
W^{(2)}
W(2)和
b
(
2
)
b^{(2)}
b(2)为隐含层到输出层映射的参数。
z
(
3
)
z^{(3)}
z(3)是未被激活的输出层节点。
a
(
3
)
a^{(3)}
a(3)为激活了的输出层节点。
如果不使用矩阵形式,那么可以写为:
a
i
(
1
)
=
x
i
z
j
(
2
)
=
∑
i
W
j
i
(
1
)
a
i
(
1
)
+
b
j
(
1
)
a
j
(
2
)
=
f
(
z
j
(
2
)
)
z
k
(
3
)
=
∑
j
W
k
j
(
2
)
a
j
(
2
)
+
b
k
(
2
)
a
k
(
3
)
=
f
(
z
k
(
3
)
)
\begin{align} a_i^{(1)} &= x_i\\ z_j^{(2)} &= \sum_{i}{W_{ji}^{(1)}}a_i^{(1)}+b_j^{(1)}\\ a_j^{(2)} &= f(z_j^{(2)})\\ z_k^{(3)} &= \sum_{j}{W_{kj}^{(2)}}a_j^{(2)}+b_k^{(2)}\\ a_k^{(3)} &= f(z_k^{(3)})\\ \end{align}
ai(1)zj(2)aj(2)zk(3)ak(3)=xi=i∑Wji(1)ai(1)+bj(1)=f(zj(2))=j∑Wkj(2)aj(2)+bk(2)=f(zk(3))
其中, i = 1 , 2 , . . . , N i i=1,2,...,N_i i=1,2,...,Ni, j = 1 , 2 , . . . , N h j=1,2,...,N_h j=1,2,...,Nh, k = 1 , 2 , . . . , N o k=1,2,...,N_o k=1,2,...,No。 N i N_i Ni, N h N_h Nh, N o N_o No分别表示输入层的节点数、隐含层层的节点数以及输出层的节点数。
代价函数
最为简单,也非常容易理解的单个样本的代价函数为:
J
(
W
,
b
;
x
,
y
)
=
1
2
∥
h
W
,
b
(
x
)
−
y
∥
2
J(W,b;x,y)=\frac{1}{2}\Vert h_{W,b}(x)-y \Vert^2
J(W,b;x,y)=21∥hW,b(x)−y∥2
相应的全局代价函数为:
J
(
W
,
b
)
=
[
1
m
∑
i
=
1
m
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
]
+
λ
2
∑
l
=
1
n
l
−
1
∑
i
=
1
S
l
∑
j
=
1
S
l
+
1
(
W
j
i
l
)
2
J(W,b)=\left[\frac{1}{m}\sum_{i=1}^mJ(W,b;x^{(i)},y^{(i)})\right]+\frac{\lambda}{2}\sum_{l=1}^{n_l-1}\sum_{i=1}^{S_l}\sum_{j=1}^{S_{l+1}}(W_{ji}^{l})^2
J(W,b)=[m1i=1∑mJ(W,b;x(i),y(i))]+2λl=1∑nl−1i=1∑Slj=1∑Sl+1(Wjil)2
反向传播
为了优化全局函数,可以求梯度并进行迭代:
W
i
j
(
l
)
=
W
i
j
(
l
)
−
α
∂
∂
W
i
j
(
l
)
J
(
W
,
b
)
b
i
(
l
)
=
b
i
(
l
)
−
α
∂
∂
b
i
(
l
)
J
(
W
,
b
)
\begin{align} W_{ij}^{(l)} &= W_{ij}^{(l)} - \alpha\frac{\partial}{\partial W_{ij}^{(l)}}J(W,b)\\ b_{i}^{(l)} &= b_{i}^{(l)} - \alpha\frac{\partial}{\partial b_{i}^{(l)}}J(W,b)\\ \end{align}
Wij(l)bi(l)=Wij(l)−α∂Wij(l)∂J(W,b)=bi(l)−α∂bi(l)∂J(W,b)
也就是说,我们只要把注意力集中在求
J
(
W
,
b
)
J(W,b)
J(W,b)对
W
i
j
(
l
)
W_{ij}^{(l)}
Wij(l)和
b
i
(
l
)
b_{i}^{(l)}
bi(l)的导数就可以了。
求导可得:
∂
∂
W
i
j
(
l
)
J
(
W
,
b
)
=
[
1
m
∑
i
=
1
m
∂
∂
W
i
j
(
l
)
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
]
+
λ
W
i
j
(
l
)
∂
∂
b
i
(
l
)
J
(
W
,
b
)
=
1
m
∑
i
=
1
m
∂
∂
b
i
(
l
)
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
\begin{align} \frac{\partial}{\partial W_{ij}^{(l)}}J(W,b) &= \left[\frac{1}{m}\sum_{i=1}^m\frac{\partial}{\partial W_{ij}^{(l)}}J(W,b;x^{(i)},y^{(i)})\right]+\lambda W_{ij}^{(l)}\\ \frac{\partial}{\partial b_{i}^{(l)}}J(W,b) &= \frac{1}{m}\sum_{i=1}^m\frac{\partial}{\partial b_{i}^{(l)}}J(W,b;x^{(i)},y^{(i)})\\ \end{align}
∂Wij(l)∂J(W,b)∂bi(l)∂J(W,b)=[m1i=1∑m∂Wij(l)∂J(W,b;x(i),y(i))]+λWij(l)=m1i=1∑m∂bi(l)∂J(W,b;x(i),y(i))
OK。那么现在的问题全部集中在求解
∂
∂
W
i
j
(
l
)
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
\frac{\partial}{\partial W_{ij}^{(l)}}J(W,b;x^{(i)},y^{(i)})
∂Wij(l)∂J(W,b;x(i),y(i))和
∂
∂
b
i
(
l
)
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
\frac{\partial}{\partial b_{i}^{(l)}}J(W,b;x^{(i)},y^{(i)})
∂bi(l)∂J(W,b;x(i),y(i))上。
首先计算解
∂
∂
W
i
j
(
l
)
J
(
W
,
b
;
x
(
i
)
,
y
(
i
)
)
\frac{\partial}{\partial W_{ij}^{(l)}}J(W,b;x^{(i)},y^{(i)})
∂Wij(l)∂J(W,b;x(i),y(i))。我们现在有:
J
(
W
,
b
;
x
,
y
)
=
1
2
∥
h
W
,
b
(
x
)
−
y
∥
2
=
1
2
∑
k
=
1
N
o
(
a
k
(
3
)
−
y
k
)
2
\begin{align} J(W,b;x,y) &= \frac{1}{2}\Vert h_{W,b}(x)-y \Vert^2\\ &= \frac{1}{2}\sum_{k=1}^{N_o}(a_k^{(3)}-y_k)^2\\ \end{align}
J(W,b;x,y)=21∥hW,b(x)−y∥2=21k=1∑No(ak(3)−yk)2
从这个式子中我们知道:
∂
J
∂
a
i
(
3
)
=
a
i
(
3
)
−
y
i
\frac{\partial J}{\partial a_i^{(3)}}=a_i^{(3)}-y_i
∂ai(3)∂J=ai(3)−yi
又,
a
i
(
3
)
=
f
(
z
i
(
3
)
)
a_i^{(3)}=f(z_i^{(3)})
ai(3)=f(zi(3))
所以,
∂
a
i
(
3
)
∂
z
i
(
3
)
=
f
′
(
z
i
(
3
)
)
\frac{\partial a_i^{(3)}}{\partial z_i^{(3)}} = f'(z_i^{(3)})
∂zi(3)∂ai(3)=f′(zi(3))
又,
z
i
(
3
)
=
∑
j
W
i
j
(
2
)
a
j
(
2
)
+
b
k
(
2
)
z_i^{(3)} = \sum_{j}{W_{ij}^{(2)}}a_j^{(2)}+b_k^{(2)}
zi(3)=j∑Wij(2)aj(2)+bk(2)
所以,
∂
z
i
(
3
)
∂
W
i
j
(
2
)
=
a
j
(
2
)
\frac{\partial z_i^{(3)}}{\partial W_{ij}^{(2)}} = a_j^{(2)}
∂Wij(2)∂zi(3)=aj(2)
综合起来,就有:
∂
J
∂
W
i
j
(
2
)
=
∂
J
∂
a
i
(
3
)
∂
a
i
(
3
)
∂
z
i
(
3
)
∂
z
i
(
3
)
∂
W
i
j
(
2
)
=
(
a
i
(
3
)
−
y
i
)
f
′
(
z
i
(
3
)
)
a
j
(
2
)
\frac{\partial J}{\partial W_{ij}^{(2)}}=\frac{\partial J}{\partial a_i^{(3)}}\frac{\partial a_i^{(3)}}{\partial z_i^{(3)}}\frac{\partial z_i^{(3)}}{\partial W_{ij}^{(2)}} = (a_i^{(3)}-y_i)f'(z_i^{(3)})a_j^{(2)}
∂Wij(2)∂J=∂ai(3)∂J∂zi(3)∂ai(3)∂Wij(2)∂zi(3)=(ai(3)−yi)f′(zi(3))aj(2)
下面再来推导
∂
J
/
∂
W
i
j
(
1
)
{\partial J}/{\partial W_{ij}^{(1)}}
∂J/∂Wij(1)。我们已知
J
(
W
,
b
;
x
,
y
)
=
1
2
∑
k
=
1
N
o
(
a
k
(
3
)
−
y
k
)
2
J(W,b;x,y) = \frac{1}{2}\sum_{k=1}^{N_o}(a_k^{(3)}-y_k)^2\\
J(W,b;x,y)=21k=1∑No(ak(3)−yk)2
在这里,
∂
J
∂
a
k
(
3
)
=
∑
k
=
1
N
o
(
a
k
(
3
)
−
y
k
)
\frac{\partial J}{\partial a_k^{(3)}}=\sum_{k=1}^{N_o}(a_k^{(3)}-y_k)
∂ak(3)∂J=k=1∑No(ak(3)−yk)
这是因为每一个
a
k
(
3
)
,
k
=
1
,
.
.
.
,
N
o
a_k^{(3)},k=1,...,N_o
ak(3),k=1,...,No都是
W
i
j
(
1
)
W_{ij}^{(1)}
Wij(1)的函数。
∂
J
∂
W
i
j
(
1
)
=
∂
J
∂
a
k
(
3
)
∂
a
k
(
3
)
∂
z
k
(
3
)
∂
z
k
(
3
)
∂
a
i
(
2
)
∂
a
i
(
2
)
∂
z
i
(
2
)
∂
z
i
(
2
)
∂
W
i
j
(
1
)
\frac{\partial J}{\partial W_{ij}^{(1)}}=\frac{\partial J}{\partial a_k^{(3)}}\frac{\partial a_k^{(3)}}{\partial z_k^{(3)}}\frac{\partial z_k^{(3)}}{\partial a_i^{(2)}}\frac{\partial a_i^{(2)}}{\partial z_i^{(2)}}\frac{\partial z_i^{(2)}}{\partial W_{ij}^{(1)}}
∂Wij(1)∂J=∂ak(3)∂J∂zk(3)∂ak(3)∂ai(2)∂zk(3)∂zi(2)∂ai(2)∂Wij(1)∂zi(2)
其中,
KaTeX parse error: No such environment: eqnarray* at position 8: \begin{̲e̲q̲n̲a̲r̲r̲a̲y̲*̲}̲ \frac{\partial…
归纳总结
推广一下,可以首先设定一个变量
δ
i
(
l
)
\delta_i^{(l)}
δi(l),其中
i
i
i表示第单元的序号,
l
l
l表示层数,它被定义为:
δ
i
(
l
)
=
∂
∂
z
i
(
l
)
J
(
W
,
b
;
x
,
y
)
\delta_i^{(l)}=\frac{\partial}{\partial z_i^{(l)}}J(W,b;x,y)
δi(l)=∂zi(l)∂J(W,b;x,y)
比如刚才的例子中,
δ
i
(
3
)
=
∂
∂
z
i
(
3
)
J
(
W
,
b
;
x
,
y
)
δ
i
(
2
)
=
∂
∂
z
i
(
2
)
J
(
W
,
b
;
x
,
y
)
=
∂
J
∂
a
k
(
3
)
∂
a
k
(
3
)
∂
z
k
(
3
)
∂
z
k
(
3
)
∂
a
i
(
2
)
∂
a
i
(
2
)
∂
z
i
(
2
)
\begin{align} \delta_i^{(3)} &= \frac{\partial}{\partial z_i^{(3)}}J(W,b;x,y)\\ \delta_i^{(2)} &= \frac{\partial}{\partial z_i^{(2)}}J(W,b;x,y)\\ &= \frac{\partial J}{\partial a_k^{(3)}}\frac{\partial a_k^{(3)}}{\partial z_k^{(3)}}\frac{\partial z_k^{(3)}}{\partial a_i^{(2)}}\frac{\partial a_i^{(2)}}{\partial z_i^{(2)}} \end{align}
δi(3)δi(2)=∂zi(3)∂J(W,b;x,y)=∂zi(2)∂J(W,b;x,y)=∂ak(3)∂J∂zk(3)∂ak(3)∂ai(2)∂zk(3)∂zi(2)∂ai(2)
定义了
δ
i
(
l
)
\delta_i^{(l)}
δi(l)后,就有:
∂
∂
W
i
j
(
l
)
J
(
W
,
b
;
x
,
y
)
=
a
j
(
l
)
δ
i
(
l
+
1
)
∂
∂
b
i
(
l
)
J
(
W
,
b
;
x
,
y
)
=
δ
i
(
l
+
1
)
\begin{align} \frac{\partial}{\partial W_{ij}^{(l)}}J(W,b;x,y) &= a_j^{(l)}\delta_i^{(l+1)}\\ \frac{\partial}{\partial b_{i}^{(l)}}J(W,b;x,y) &= \delta_i^{(l+1)}\\ \end{align}
∂Wij(l)∂J(W,b;x,y)∂bi(l)∂J(W,b;x,y)=aj(l)δi(l+1)=δi(l+1)
上式的证明是这样:
∂
∂
W
i
j
(
l
)
J
(
W
,
b
;
x
,
y
)
=
∂
J
∂
z
i
(
l
+
1
)
∂
z
i
(
l
+
1
)
∂
W
i
j
(
l
)
∂
∂
b
i
(
l
)
J
(
W
,
b
;
x
,
y
)
=
∂
J
∂
z
i
(
l
+
1
)
∂
z
i
(
l
+
1
)
∂
b
i
(
l
)
\begin{align} \frac{\partial}{\partial W_{ij}^{(l)}}J(W,b;x,y) &= \frac{\partial J}{\partial z_i^{(l+1)}}\frac{\partial z_i^{(l+1)}}{\partial W_{ij}^{(l)}}\\ \frac{\partial}{\partial b_{i}^{(l)}}J(W,b;x,y) &= \frac{\partial J}{\partial z_i^{(l+1)}}\frac{\partial z_i^{(l+1)}}{\partial b_{i}^{(l)}}\\ \end{align}
∂Wij(l)∂J(W,b;x,y)∂bi(l)∂J(W,b;x,y)=∂zi(l+1)∂J∂Wij(l)∂zi(l+1)=∂zi(l+1)∂J∂bi(l)∂zi(l+1)
由于
z
i
(
l
+
1
)
=
∑
k
W
i
k
(
l
)
a
k
(
l
)
+
b
i
(
l
)
z_i^{(l+1)} = \sum_{k}{W_{ik}^{(l)}}a_k^{(l)}+b_i^{(l)}
zi(l+1)=k∑Wik(l)ak(l)+bi(l)
所以
∂
z
i
(
l
+
1
)
∂
W
i
j
(
l
)
=
a
j
(
l
)
∂
z
i
(
l
+
1
)
∂
b
i
(
l
)
=
1
\begin{align} \frac{\partial z_i^{(l+1)}}{\partial W_{ij}^{(l)}} &= a_j^{(l)}\\ \frac{\partial z_i^{(l+1)}}{\partial b_{i}^{(l)}} &= 1\\ \end{align}
∂Wij(l)∂zi(l+1)∂bi(l)∂zi(l+1)=aj(l)=1
向量化
刚刚的都是针对单个标量的公式求导。真正实现的时候,可以转换为向量形式:
δ
(
n
l
)
=
−
(
y
−
a
(
n
l
)
)
∙
f
′
(
z
(
n
l
)
)
δ
(
l
)
=
(
(
W
(
l
)
)
T
δ
(
l
+
1
)
)
∙
f
′
(
z
(
l
)
)
\begin{align} \boldsymbol{\delta}^{(n_l)} &= -(\boldsymbol{y}-\boldsymbol{a}^{(n_l)})\bullet f'(\boldsymbol{z}^{(n_l)})\\ \boldsymbol{\delta}^{(l)} &= \left( (W^{(l)})^T \boldsymbol{\delta}^{(l+1)}\right) \bullet f'(\boldsymbol{z^{(l)}})\\ \end{align}
δ(nl)δ(l)=−(y−a(nl))∙f′(z(nl))=((W(l))Tδ(l+1))∙f′(z(l))
则
∇
W
(
l
)
J
(
W
,
b
;
x
,
y
)
=
δ
(
l
+
1
)
(
a
(
l
)
)
T
∇
b
(
l
)
J
(
W
,
b
;
x
,
y
)
=
δ
(
l
+
1
)
\begin{align} \nabla_{W^{(l)}}J(W,b;x,y) &= \boldsymbol{\delta}^{(l+1)}\left( \boldsymbol{a^{(l)}} \right)^T\\ \nabla_{b^{(l)}}J(W,b;x,y) &= \boldsymbol{\delta}^{(l+1)}\\ \end{align}
∇W(l)J(W,b;x,y)∇b(l)J(W,b;x,y)=δ(l+1)(a(l))T=δ(l+1)
另外,我们还可以使用下式来简化计算
f
′
(
z
i
(
l
)
)
=
f
(
z
i
(
l
)
)
(
1
−
f
(
z
i
(
l
)
)
)
=
a
i
(
l
)
(
1
−
a
i
(
l
)
)
f'(z_i^{(l)})=f(z_i^{(l)})(1-f(z_i^{(l)}))=a_i^{(l)}(1-a_i^{(l)})
f′(zi(l))=f(zi(l))(1−f(zi(l)))=ai(l)(1−ai(l))
整体梳理
- 令 Δ W ( l ) : = 0 \Delta W^{(l)}:=0 ΔW(l):=0, Δ b ( l ) : = 0 \Delta \boldsymbol{b}^{(l)}:=0 Δb(l):=0。
- For i i i=1 to m m m
- 计算 ∇ W ( l ) J ( W , b ; x , y ) \nabla_{W^{(l)}}J(W,b;x,y) ∇W(l)J(W,b;x,y)和 ∇ b ( l ) J ( W , b ; x , y ) \nabla_{b^{(l)}}J(W,b;x,y) ∇b(l)J(W,b;x,y)
- 令 Δ W ( l ) : = Δ W ( l ) + ∇ W ( l ) J ( W , b ; x , y ) \Delta W^{(l)}:=\Delta W^{(l)}+\nabla_{W^{(l)}}J(W,b;x,y) ΔW(l):=ΔW(l)+∇W(l)J(W,b;x,y)
- 令 Δ b ( l ) : = Δ b ( l ) + ∇ b ( l ) J ( W , b ; x , y ) \Delta \boldsymbol{b^{(l)}}:=\Delta \boldsymbol{b}^{(l)}+\nabla_{b^{(l)}}J(W,b;x,y) Δb(l):=Δb(l)+∇b(l)J(W,b;x,y)
- 更新参数:
W ( l ) = W ( l ) − α [ ( 1 m Δ W ( l ) ) + λ W ( l ) ] b ( l ) = b ( l ) − α [ ( 1 m Δ b ( l ) ) ] \begin{align} W^{(l)} &= W^{(l)} - \alpha\left[ (\frac{1}{m}\Delta W^{(l)})+\lambda W^{(l)} \right]\\ \boldsymbol{b}^{(l)} &= \boldsymbol{b}^{(l)} - \alpha\left[ (\frac{1}{m}\Delta \boldsymbol{b}^{(l)}) \right]\\ \end{align} W(l)b(l)=W(l)−α[(m1ΔW(l))+λW(l)]=b(l)−α[(m1Δb(l))]
最后一层变为softmax模型
如果使用softmax模型,则代价函数变为
J
(
θ
)
=
−
[
∑
n
=
1
N
∑
k
=
1
K
1
{
y
(
n
)
=
k
}
l
o
g
e
x
p
(
(
θ
(
k
)
)
T
h
W
,
b
(
x
(
n
)
)
)
∑
j
=
1
K
e
x
p
(
(
θ
(
j
)
)
T
h
W
,
b
(
x
(
n
)
)
)
]
=
−
∑
n
=
1
N
∑
k
=
1
K
t
n
k
log
S
n
k
\begin{align} J(\theta) &= -\left[ \sum_{n=1}^N\sum_{k=1}^K1\{ y^{(n)}=k \}log\frac{exp\left(\left( \theta^{(k)} \right)^T h_{W,b}\left( x^{(n)} \right) \right)}{\sum_{j=1}^Kexp\left(\left( \theta^{(j)} \right)^T h_{W,b}\left( x^{(n)} \right) \right)} \right]\\ &= - \sum_{n=1}^N\sum_{k=1}^K t_{nk} \log S_{nk}\\ \end{align}
J(θ)=−
n=1∑Nk=1∑K1{y(n)=k}log∑j=1Kexp((θ(j))ThW,b(x(n)))exp((θ(k))ThW,b(x(n)))
=−n=1∑Nk=1∑KtnklogSnk
其中,
t
n
k
=
1
{
y
(
i
)
=
k
}
S
n
k
=
exp
(
(
θ
(
k
)
)
T
h
W
,
b
(
x
(
n
)
)
)
∑
j
=
1
K
exp
(
(
θ
(
j
)
)
T
h
W
,
b
(
x
(
n
)
)
)
\begin{align} t_{nk} &= 1\{ y^{(i)}=k \}\\ S_{nk} &= \frac{\exp\left(\left( \theta^{(k)} \right)^T h_{W,b}\left( x^{(n)} \right) \right)}{\sum_{j=1}^K\exp\left(\left( \theta^{(j)} \right)^T h_{W,b}\left( x^{(n)} \right) \right)}\\ \end{align}
tnkSnk=1{y(i)=k}=∑j=1Kexp((θ(j))ThW,b(x(n)))exp((θ(k))ThW,b(x(n)))
在
S
n
k
S_{nk}
Snk中,
n
n
n表示的是样本的序列。不失一般性,去掉
n
n
n,则有
P
(
y
=
k
∣
x
;
θ
)
=
S
k
(
x
;
θ
)
=
exp
(
z
k
(
3
)
)
∑
j
exp
(
z
j
(
3
)
)
P(y=k|x;\theta)=S_k(x;\theta)=\frac{\exp(z_k^{(3)})}{\sum_j\exp(z_j^{(3)})}
P(y=k∣x;θ)=Sk(x;θ)=∑jexp(zj(3))exp(zk(3))
其中,
z
k
(
3
)
=
(
θ
(
k
)
)
T
h
W
,
b
(
x
(
n
)
)
a
(
2
)
=
h
W
,
b
(
x
(
n
)
)
\begin{align} z_k^{(3)} &= \left( \theta^{(k)} \right)^T h_{W,b}\left( x^{(n)} \right) \\ \boldsymbol{a^{(2)}} &= h_{W,b}\left( x^{(n)} \right)\\ \end{align}
zk(3)a(2)=(θ(k))ThW,b(x(n))=hW,b(x(n))
然后我们便可以根据之前所说的来求解
δ
i
(
3
)
\delta_i^{(3)}
δi(3)。
δ
i
(
3
)
=
∂
J
∂
z
i
(
3
)
=
∂
J
∂
S
n
k
∂
S
n
k
∂
z
i
(
3
)
=
−
∑
n
=
1
N
∑
k
=
1
K
t
n
k
1
S
n
k
S
n
k
(
I
k
i
−
S
n
i
)
=
−
∑
n
=
1
N
∑
k
=
1
K
t
n
k
(
I
k
i
−
S
n
i
)
=
−
∑
n
=
1
N
(
∑
k
=
1
K
t
n
k
I
k
i
−
∑
k
=
1
K
t
n
k
S
n
i
)
=
−
∑
n
=
1
N
(
t
n
i
−
S
n
i
)
\begin{align} \delta_i^{(3)} &= \frac{\partial J}{\partial z_i^{(3)}} \\ &= \frac{\partial J}{\partial S_{nk}} \frac{\partial S_{nk}}{\partial z_i^{(3)}}\\ &= -\sum_{n=1}^N\sum_{k=1}^Kt_{nk}\frac{1}{S_{nk}}S_{nk}(I_{ki}-S_{ni})\\ &= -\sum_{n=1}^N\sum_{k=1}^Kt_{nk}(I_{ki}-S_{ni})\\ &= -\sum_{n=1}^N\left( \sum_{k=1}^Kt_{nk}I_{ki}- \sum_{k=1}^Kt_{nk}S_{ni} \right)\\ &= -\sum_{n=1}^N\left( t_{ni}-S_{ni} \right) \end{align}
δi(3)=∂zi(3)∂J=∂Snk∂J∂zi(3)∂Snk=−n=1∑Nk=1∑KtnkSnk1Snk(Iki−Sni)=−n=1∑Nk=1∑Ktnk(Iki−Sni)=−n=1∑N(k=1∑KtnkIki−k=1∑KtnkSni)=−n=1∑N(tni−Sni)
在上面的推导中,我们利用了
∑
k
t
n
k
=
1
\sum_kt_{nk}=1
∑ktnk=1。
CNN(Convolutional Neural Network)
还是假设三层网络。第一层是输入层,第二层是卷积后池化的隐含层,第三层是最后的输出层。第二层和第三层之间是全连接的。则:
δ
i
(
2
)
=
∂
J
∂
z
i
(
2
)
=
∂
J
∂
z
k
(
3
)
∂
z
k
(
3
)
∂
a
j
(
2
)
∂
a
j
(
2
)
∂
z
i
(
2
)
=
∑
k
=
1
K
δ
k
(
3
)
W
k
j
(
2
)
∂
a
j
(
2
)
∂
z
i
(
2
)
\begin{align} \delta_i^{(2)} &= \frac{\partial J}{\partial z_i^{(2)}} \\ &= \frac{\partial J}{\partial z_{k}^{(3)}} \frac{\partial z_{k}^{(3)}}{\partial a_j^{(2)}}\frac{\partial a_j^{(2)}}{\partial z_i^{(2)}}\\ &= \sum_{k=1}^K\delta_k^{(3)}W_{kj}^{(2)}\frac{\partial a_j^{(2)}}{\partial z_i^{(2)}} \end{align}
δi(2)=∂zi(2)∂J=∂zk(3)∂J∂aj(2)∂zk(3)∂zi(2)∂aj(2)=k=1∑Kδk(3)Wkj(2)∂zi(2)∂aj(2)
现在的关键是
∂
a
j
(
2
)
/
∂
z
i
(
2
)
{\partial a_j^{(2)}}/{\partial z_i^{(2)}}
∂aj(2)/∂zi(2)。
下面考虑一下物理意义:
- a ( 1 ) \boldsymbol{a}^{(1)} a(1)是输入层,一般来说,是一幅二维的图像。
- 用一个kernel对这幅图像进行卷积,并加上一个偏移量后,称之为 z ( 2 ) \boldsymbol{z}^{(2)} z(2)。
- 对 z ( 2 ) \boldsymbol{z}^{(2)} z(2)激励,并池化后的结果称之为 a ( 2 ) \boldsymbol{a}^{(2)} a(2)
那么可以举一个例子:设
z
(
2
)
\boldsymbol{z}^{(2)}
z(2)为一个
8
×
8
8\times8
8×8的矩阵且池化为原尺寸的
1
2
×
1
2
\frac{1}{2}\times\frac{1}{2}
21×21。则,
a
1
(
2
)
=
1
4
(
f
(
z
1
(
2
)
)
+
f
(
z
2
(
2
)
)
+
f
(
z
9
(
2
)
)
+
f
(
z
10
(
2
)
)
)
a_1^{(2)}=\frac{1}{4}\left( f(z_1^{(2)}) + f(z_2^{(2)}) + f(z_9^{(2)}) + f(z_{10}^{(2)}) \right)
a1(2)=41(f(z1(2))+f(z2(2))+f(z9(2))+f(z10(2)))
这样,我们就知道
∂
a
1
(
2
)
∂
z
1
(
2
)
=
1
4
f
′
(
z
1
(
2
)
)
∂
a
1
(
2
)
∂
z
2
(
2
)
=
1
4
f
′
(
z
2
(
2
)
)
∂
a
1
(
2
)
∂
z
9
(
2
)
=
1
4
f
′
(
z
9
(
2
)
)
∂
a
1
(
2
)
∂
z
10
(
2
)
=
1
4
f
′
(
z
10
(
2
)
)
\begin{align} \frac{\partial a_1^{(2)}}{\partial z_1^{(2)}} &= \frac{1}{4}f'(z_1^{(2)}) \\ \frac{\partial a_1^{(2)}}{\partial z_2^{(2)}} &= \frac{1}{4}f'(z_2^{(2)}) \\ \frac{\partial a_1^{(2)}}{\partial z_9^{(2)}} &= \frac{1}{4}f'(z_9^{(2)}) \\ \frac{\partial a_1^{(2)}}{\partial z_{10}^{(2)}} &= \frac{1}{4}f'(z_{10}^{(2)}) \\ \end{align}
∂z1(2)∂a1(2)∂z2(2)∂a1(2)∂z9(2)∂a1(2)∂z10(2)∂a1(2)=41f′(z1(2))=41f′(z2(2))=41f′(z9(2))=41f′(z10(2))
而这就相当于对
a
1
(
2
)
a_1^{(2)}
a1(2)上采样为
2
×
2
2\times 2
2×2,并且将每一个值变为原来的1/4。然后再分别与对应的
z
j
(
2
)
z_j^{(2)}
zj(2)的导数相乘。由于我也不会严格推导,因此,这里就直接给出答案:
δ
k
(
2
)
=
u
p
s
a
m
p
l
e
(
(
W
k
(
2
)
)
T
δ
k
(
3
)
)
∙
f
′
(
z
k
(
2
)
)
\delta_k^{(2)}=upsample\left( \left( W_k^{(2)} \right)^T\delta_k^{(3)} \right)\bullet f'(z_k^{(2)})
δk(2)=upsample((Wk(2))Tδk(3))∙f′(zk(2))
那么,如果是max-pooling呢?还是举刚才的例子:
a
1
(
2
)
=
max
(
f
(
z
1
(
2
)
)
,
f
(
z
2
(
2
)
)
,
f
(
z
9
(
2
)
)
,
f
(
z
10
(
2
)
)
)
a_1^{(2)}=\max\left( f(z_1^{(2)}),f(z_2^{(2)}),f(z_9^{(2)}),f(z_{10}^{(2)}) \right)
a1(2)=max(f(z1(2)),f(z2(2)),f(z9(2)),f(z10(2)))
这个导数怎么求?其实也不难,如果我们知道
f
(
z
1
(
2
)
)
,
f
(
z
2
(
2
)
)
,
f
(
z
9
(
2
)
)
,
f
(
z
10
(
2
)
)
f(z_1^{(2)}),f(z_2^{(2)}),f(z_9^{(2)}),f(z_{10}^{(2)})
f(z1(2)),f(z2(2)),f(z9(2)),f(z10(2))中哪个值最大,那么对那个
z
i
(
2
)
z_i^{(2)}
zi(2)的分量求导就是
f
′
(
z
i
(
2
)
)
f'(z_i^{(2)})
f′(zi(2))而对其它的分量求导就是0。
这样的话,就相当于
δ
k
(
2
)
\delta_k^{(2)}
δk(2)的式子不用改,而只需要更改
u
p
s
a
m
p
l
e
upsample
upsample的含义就可以了。求平均的池化方法类似于把误差平分到每一个单元,而max-pooling方法的误差全部都放到某一个上采样后的单元上,其它单元全部设为0。
到现在,
δ
(
2
)
\delta^{(2)}
δ(2)已经求解成功,但还没有结束。下面还需要求解
∂
z
i
(
2
)
/
∂
W
m
n
(
1
)
{\partial z_i^{(2)}}/{\partial W_{mn}^{(1)}}
∂zi(2)/∂Wmn(1)。假设kernel是一个
3
×
3
3\times 3
3×3的矩阵。并且可以写成:
(
W
11
(
1
)
W
12
(
1
)
W
13
(
1
)
W
21
(
1
)
W
22
(
1
)
W
23
(
1
)
W
31
(
1
)
W
32
(
1
)
W
33
(
1
)
)
\left( \begin{array}{rcl} W_{11}^{(1)}&W_{12}^{(1)}&W_{13}^{(1)}\\ W_{21}^{(1)}&W_{22}^{(1)}&W_{23}^{(1)}\\ W_{31}^{(1)}&W_{32}^{(1)}&W_{33}^{(1)}\\ \end{array} \right)
W11(1)W21(1)W31(1)W12(1)W22(1)W32(1)W13(1)W23(1)W33(1)
则
z
1
(
2
)
=
∑
i
=
1
3
∑
j
=
1
3
W
i
j
(
1
)
a
i
j
(
1
)
+
b
(
1
)
z_1^{(2)}=\sum_{i=1}^3\sum_{j=1}^3W_{ij}^{(1)}a_{ij}^{(1)}+b^{(1)}
z1(2)=∑i=13∑j=13Wij(1)aij(1)+b(1)
则
∂
z
1
(
2
)
/
∂
W
11
(
1
)
=
a
11
(
1
)
\partial z_1^{(2)}/\partial W_{11}^{(1)}=a_{11}^{(1)}
∂z1(2)/∂W11(1)=a11(1),而对
W
11
(
1
)
W_{11}^{(1)}
W11(1)有贡献的
z
(
2
)
\boldsymbol{z}^{(2)}
z(2)的分量还有很多,他们的导数构成了一下的矩阵:
(
a
11
(
1
)
⋯
a
16
(
1
)
⋮
⋱
⋮
a
61
(
1
)
⋯
a
66
(
1
)
)
\left( \begin{array}{rcl} a_{11}^{(1)}&\cdots&a_{16}^{(1)}\\ \vdots&\ddots&\vdots\\ a_{61}^{(1)}&\cdots&a_{66}^{(1)}\\ \end{array} \right)
a11(1)⋮a61(1)⋯⋱⋯a16(1)⋮a66(1)
综上,可以得出
∂
J
∂
W
11
(
1
)
=
(
∑
i
=
1
6
∑
j
=
1
6
δ
i
j
(
2
)
a
i
j
)
\frac{\partial J}{\partial W_{11}^{(1)}}=\left( \sum_{i=1}^6\sum_{j=1}^6\delta_{ij}^{(2)}a_{ij} \right)
∂W11(1)∂J=(i=1∑6j=1∑6δij(2)aij)
这其实可以看成是一种相关的形式,最后,给出整体的梯度:
∇
W
k
(
1
)
J
(
W
,
b
;
x
,
y
)
=
(
a
(
1
)
)
∗
rot90
(
δ
k
(
2
)
,
2
)
,
∇
b
k
(
1
)
J
(
W
,
b
;
x
,
y
)
=
∑
r
,
c
(
δ
k
(
2
)
)
r
,
c
.
\begin{align} \nabla_{W_k^{(1)}} J(W,b;x,y) &= (a^{(1)}) \ast \text{rot90}(\delta_k^{(2)},2), \\ \nabla_{b_k^{(1)}} J(W,b;x,y) &= \sum_{r,c} (\delta_k^{(2)})_{r,c}. \end{align}
∇Wk(1)J(W,b;x,y)∇bk(1)J(W,b;x,y)=(a(1))∗rot90(δk(2),2),=r,c∑(δk(2))r,c.
CNN变种(高效版)
上面介绍的CNN,在第一层到第二层之间发生的变化依次为:卷积->激活->池化。而更加高效的做法是,把顺序调整一下,顺序依次为:卷积->池化->激活。用数学公式来示意一下,即为:
第一种:
D
(
f
(
W
x
(
r
,
c
)
+
b
)
)
D(f(Wx_{(r,c)}+b))
D(f(Wx(r,c)+b))
第二种:
f
(
D
(
W
x
(
r
,
c
)
)
+
b
)
f(D(Wx_{(r,c)})+b)
f(D(Wx(r,c))+b)
说第二种更高效的原因在于:在降采样的矩阵上做一些操作,总比在原矩阵上做同样的操作要快一些。更何况,激励函数中总是会包含指数操作。如果在DSP上运算,特别是在定点的DSP上进行运算,指数操作总是越少越好。
针对高效版的求导过程,与之前的CNN求导过程差的不多。这里就不赘述。一点提示就是,针对第一种,我的
z
(
2
)
z^{(2)}
z(2)取的是
W
x
(
r
,
c
)
+
b
Wx_{(r,c)}+b
Wx(r,c)+b,而对于高效版的第二种,我的
z
(
2
)
z^{(2)}
z(2)取的是
W
x
(
r
,
c
)
Wx_{(r,c)}
Wx(r,c)。
推导的结果是:
δ
k
(
2
)
=
u
p
s
a
m
p
l
e
(
(
W
k
(
2
)
)
T
δ
k
(
3
)
∙
f
′
(
d
k
(
2
)
)
)
\delta_k^{(2)}=upsample\left( \left( W_k^{(2)} \right)^T\delta_k^{(3)} \bullet f'(d_k^{(2)}) \right)
δk(2)=upsample((Wk(2))Tδk(3)∙f′(dk(2)))
其中,
d
k
(
2
)
d_k^{(2)}
dk(2)对应的是
D
(
W
x
(
r
,
c
)
)
+
b
D(Wx_{(r,c)})+b
D(Wx(r,c))+b部分。可以看到,在求解
δ
k
(
2
)
\delta_k^{(2)}
δk(2)的部分,第二种与第一种的区别是,第一种在前向传播的过程中是先激活,再降采样的。因此在求导的时候先上采样,再乘以激活函数的导数。而第二种在前向传播的过程中是先降采样,然后再激活的。因此在求导的时候,先乘以激活函数的导数,然后再上采样。
其它的都与第一种相同。
写在最后
在上述的推导过程中,为了更加具体地描述,我都具体地表明了采用的神经网络的结构。我采用的结构一般都为三层。但事实上,掌握了上述的方法之后,可以将层数扩展到任意层。这是因为对
W
(
l
)
W^{(l)}
W(l)和
b
(
l
)
b^{(l)}
b(l)的导数,就只与当层的
a
(
l
)
\boldsymbol{a}^{(l)}
a(l)与后一层的
δ
(
l
+
1
)
\boldsymbol{\delta}^{(l+1)}
δ(l+1)有关。通过从后往前的推导,我们总能求解出
W
(
l
)
W^{(l)}
W(l)和
b
(
l
)
b^{(l)}
b(l)的导数。这也是反向传播的含义。
另外,虽然我对我的数学没有很大的信心,但是,通过实际的验证,表明推导的都是正确的。这才有信心把推导的内容记录下来。














 1806
1806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









