







目录
序言
总结这段时间遇到的面试题目以及该如何解答。面试后才发现,自己对知识点的了解那么的浅显。对于细节部分完全应付不了。
深度学习部分
1.BN方面的知识方面
问题一:BN层训练和测试时的均值和方差具体是怎么得到的?
在训练的时候,均值和方差是有mini-batch样本上计算得到的。
而测试的均值和方差则是 由训练的所有批 的数据的均值和方差 取一个移动平均值得到的均值和方差。
问题二:深度学习中,偏置(bias)在有BN的时候还需要吗?
不需要。 对于BN有一个操作是减去均值。
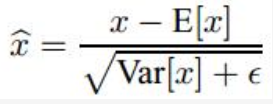
假设 x1 = x0 * wo + b0; E[x1] = E[x0w0] + b0 所以x1 - E[x1] 会把b0减去。
所以,卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占显卡内存。
问题三:BN训练的时候是对整张照片做归一化还是对通道做归一化?
对同一通道的特征图做归一化。
假设数据有四个通道[n,c,h,w] n是多少个,c是通道数量,h,w是长和宽,BN是统计 n个样本 同一通道的特征图的均值和方差,即在NWH 范围内计算均值和方差
问题四:讲讲BN的公式
先统计出同一个batch的n个样本的均值和方差(mini-batch mean , variance)
然后减去均值和除 方差的平方跟 再加上缩放和偏倚(scale + shift)
问题五:为什么BN会防止过拟合的作用?
因为BN需要计算一个batch的均值和方差,即一个样本的输出 会跟这一个batch的样本相关,这个样本和不同batch组合,输出也是不同的。所以这算是一种数据增强,提高了模型的泛化能力,防止过度拟合。
2. ResNet网络的理解
问题一:对residual block的理解,为什么需要残差块,它的意义是什么?
残差块是指在神经网络中,在单元的输出值加入单元的输入值,意义是让这一层的神经网络性能至少不会比上一层的网络性能差,即使这一层的训练参数训练的非常的差。
残差块是基本结构是 输入 – 卷积 – 卷积 --输出+输入。
问题二:stage在resnet是怎么划分的
按照输出的特征图的大小来划分
224–112 --56–28–14–7--1
除了第一个stage完成下采样是用maxpool
其他stage是通过步长为2的卷积层执行的下层样。
问题三:V1和V2的残差块有了解

V1是原来一开始提出的结构 简单来说是
输入 – 3x3卷积 – BN – ReLU激活 — 3x3卷积 --BN —跟输入相加 — ReLU激活
V2的后来改进过
输入 – BN – ReLU激活–3x3卷积 --BN --激活 – 3x3卷积 — 跟输入相加
V2的改进有什么好处?
V2是改变残差单元的BN、ReLU、Conv的位置。然后进行了大量的实验,选取效果最好的的结构,进而提出一种新的残差单元
为什么效果会这么好?
在激活前使用BN使模型更具有正则化的能力。在原始的V1残差单元中,尽管是使用了BN对特征进行了归一化,但是归一化之后结果直接加上跳跃连接(输入值),因此融合后的特征就不再具有归一化的特性。
而V2是BN之后马上卷积,这样卷积后具有BN的正则化能力。
问题四:basic block和BottleNeck Block的区别,为什么BottleNeck Block可以降低计算量?
basic block:输入 – 3x3卷积 --3x3卷积 --相加
BottleNeck:输入 – 1x1卷积 – 3x3卷积 --1x1卷积 --相加

BottleNeck一般应用在大于50层的ResNet中,而basic一般应用在少于50层的ResNet。
为什么BottleNeck会更好
(1)因为BottleBeck在参数会更加节省,同时还能发挥作用保持网络性能的提升。
这是因为BottleNeck用了两个1x1卷积核 只用了一个3x3卷积核
对于basic block 参数数量是
3 x 3 x 64 + 3 x 3 x 64 = 1152
对于BottleNeck 参数数量是
1 x 1 x 64 + 3 x 3 x 64 + 1 x 1 x 256 = 896
是吧,参数少了一点。
(2)使用了两个激活函数ReLU,引用更多的非线性映射。
问题五:能简单说一下ResNet的框架
简单来说,
输入是224 x 224 x 3
第一个stage:经过7x7x64滤波器,步长为2的卷积 输出是 112 x 112 x 64
第二个stage:经过3 x 3 池化,步长为2 输出是 56 x 56 x 64
然后经过几个残差块 输出 为 56 x 56 x n
第三个satge:经过几个残差块 输出是 28 x 28
第四个satge:经过几个残差块 输出是 14 x 14
第五个stage:经过几个残差块,输出是7 x 7
最后是一个average pooling
整个过程不会使用dropout 全部使用BN来避免梯度问题。
没有全连接层。最后是池化层,减少了大量的参数。
问题六:为什么会出现退化现象,原因?
首先,什么是退化现象,即随着网络越深的时候,网络性能急速下降。注意并不是过拟合,过拟合是训练的时候网络性能是上升的,只是验证集的时候网络性能下降。
https://cloud.tencent.com/developer/news/62986
上面文章有研究 为什么会产生退化现象,可能是跟权重矩阵的秩有关。
论文对比了 完整的64 x 64的权重矩阵 和 将每个初始权重矩阵的前半部分复制到后半部分的权重矩阵,对比效果,发现后面被fold的网络性能退化更加严重。所以猜测这网络性能可能跟权重矩阵的秩有关。【有效维数】
随着相乘矩阵的数量(即网络深度)的增加,这种矩阵的乘积变得越来越退化
问题七: 1 x 1 的卷积在这里的作用是什么?
对通道进行升维度或者降维,保持特征图大小。
降低运算的复杂度因为减少了参数的训练
3. Inception 网络方面
问题一: Inception有几个不同版本,可以讲一下吗?
有Inception V1 , V2,V3,V4和ResNet版本
其中,Inception V4 基本上是当前在 ImageNet 图像分类任务 Top-1 正确率最高的模型。
Inception的提出是因为 由于信息位置的差异,不知道如何选取合适的卷积核大小,比如,如果信息分布更加全局性的图像【比如狗狗的区域占据比较大的部分】,会偏好较大的卷积核; 信息分布比较局部的图像【比如狗狗的区域占据比较小的部分】则偏好较小的卷积核。
那么我们并不知道输入图片到底是什么类型的图片,所以Inception提出,在每一层,运行多个尺寸的滤波器。分别用1 x 1,3 x 3,5 x 5 的卷积核来对图像做卷积操作。此外,还会同时做池化层。联合起来传送到下一层,如下图所示:

同时,为了节省计算成本,作者在3x3和5x5卷基层之前还添加了1x1的卷积层 来限制输入通道的数量,比如输入是 224 x 224 x 100 用1 x 1 x 20 来降低通道数量 变成 224 x 224 x 20 极大的降低了参数数量,降低算力成本【PS:1 x 1卷积在最大池化层之后,而不是之前】
V2:
将5 x 5 卷积分解成两个3 x 3 的卷积运算 来提升速度,但一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍。所以叠加两个 3×3 卷积实际上在性能上会有所提升,如下图所示:

此外,作者将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%,

4. 目标检测方面
问题一:有了解过目标检测的方法吗
机器学习部分
1. GBDT算法方面
问题一:当你构建了五棵树,现在有一个新样本,你会怎么算这个样本的预测值?
根据新样本的特征 遍历每一棵树 得到一个输出值,然后累加得到预测值
问题二:GBDT和随机森林RF的区别 优缺点
随机森林是通过随机的方式创建多个决策树,输出的类别有多数树决定;
随机性体现在 有放回的随机抽样;和随机选择几个特征,再寻找最佳特征的最佳切分点。
而GBDT是以决策回归树为基础的,每一次新的训练是对上一次模型的残差进行拟合。
区别 优缺点
(1)RF可以是分类树或者是回归树;而GBDT只能是回归树
(2)RF可以并行生成,而GBDT只能是穿行生成
(3)输出结果来说,RF是多数树决定结果;GBDT是将所有结果累加起来。
(4)RF对异常值不敏感;GBDT对异常值敏感。
(5)RF通过减少模型的方差来提高性能,GBDT通过减少模型的偏差来提高性能。
问题三:GBDT的算法流程以及如何选择特征
采用加法模型,不断减少训练过程产生的残差的算法。
遍历每个特征的可能的切分点,寻找最优特征的最优切分点
GBDT是用负梯度来拟合残差,其实实际上训练学习都是负梯度。只不过在MSE作为损失函数中,刚好负梯度就等于残差。
问题四: GBDT哪些部分可以并行
(1) 计算每个样本的负梯度
(2) 分裂挑选最佳特征及其分割点时,对特征计算相应的误差及均值时
(3)更新每个样本的负梯度时
(4) 最后预测过程中,每个样本将之前的所有树的结果累加的时候
2. L1/L2正则化
问题一: L1和L2正则化的公式是什么?
L1是将参数的绝对值之和 加入到损失函数当中
L2是将参数的平方之和 加入到损失函数当中。
问题二:L1和L2的特点是什么以及为什么
L1使得权重稀疏,L2使得权重平滑
权重稀疏的原因是在求损失函数最优解的时候,添加了L1正则项的损失函数,一般是在,假设用二维度的参数 画图,一般是在 顶点上取得最优解。即 将会有一个参数值为0,所以某些特征将会损失,即导致权重稀疏。
L2 则是 在参数都比较小的时候,取得最优解。
问题三:为什么会有泛化能力?
过拟合是因为在训练数据误差很小,在测试数据误差却很大,模型更加贴合训练数据;添加正则化则是可以使模型复杂度降低,减少W的参数值,因为当参数比较大的时候,数据如果偏移一点,则会对结果产生比较大的影响;而如果w参数比较小的时候,当数据发生偏移,则会对结果影响没那么大。
3. SVM算法
问题一: SVM的了解
选择里平面最近的数据来 学习间隔最大化的超平面来分割。
是间隔最大的二元线性分类器【非概率得到】
当遇到线性可分的样本时,通过硬间隔最大化,学习到一个线性分类器
当遇到数据近似线性可分时,引入松弛因子,通过软间隔最大化,学习一个线性分类器
当遇到线性不可分的数据,通过使用核函数来学习非线性分类器。
问题二:SVM的损失函数
损失函数原本是1/2 |W|^2 转换为对偶形式来求解,一方面 求解更加容易,代入公式即可;另一方面是可以引入核函数。
问题三: SVM的核函数 以及解释核函数 区别 优缺点
为什么要引入核函数呢,因为当样本在原始空间线性不可分的时候,可以将样本映射到一个更高维度的特征空间中,使得在这个空间可以用平面划分,
但是这样子的话,需要计算高维度的特征内积,计算量过大,这时候引入核函数代替计算,则可以大大降低计算成本。
核函数有:
线性核函数:可解释性强,但只限于解决线性可分的数据
多项式核函数:可以解决非线性问题但需要主观来设置幂
高斯核函数:可以映射到多维度的特征空间,只需要一个参数 但解释性差,容易过拟合。
sigmoid核函数:多用在神经网络,保证样本的泛化能力
问题四:SVM和LR的区别和优缺点
(1)损失函数不同,一个是交叉熵 一个是对偶形式的函数
(2)输出结果不一样,一个是输出概率值,一个是输出分类结果 正类还是负类
(3)SVM主要是关注 跟分类最相关的那些点,即关注局部关键信息;而LR是在全局进行优化,所以SVM比LR有更好的泛化能力,防止过度拟合。
4. XGBoost算法
问题一:简单介绍一下XGBoost
是在GBDT的基础上加入了正则化,加入二阶求导的信息。
之前GBDT用的更新算法是 SGB,而这次XGBoost用的是牛顿法
xgboost中,我们则是把损失函数的二阶泰勒展开的差值作为学习目标,相当于利用牛顿法进行优化,来逼近损失函数的最小值。
问题二: XGBoost跟GBDT的区别 优缺点
(1)GBDT是用决策回归树为基础,而XGBoost还可以支持线性分类器
(2)GBDT的分类的方式是GINI系数,XGBoost的经过推导之后。
(3)传统的GBDT在优化的时候,只用到一阶导数信息,而xgboost则进行了二阶泰勒展开,同时用了一阶和二阶。xgboost的优势是二阶导数有利于梯度下降的更快更准,
(4)xgboost的代价函数中加入了正则项 有利于控制模型的复杂度 ,降低了过度拟合的可能性。
5. LR逻辑回归
问题一:LR逻辑回归的理解
首先,逻辑回归有两个假设
第一个假设是 数据服从伯努利分布,即二项式分布。
第二个假设是 假设样本为正的概率是
P
=
1
1
+
e
−
(
w
x
+
b
)
P = \frac{1}{1+e^{-(wx+b)}}
P=1+e−(wx+b)1
逻辑回归的损失函数是它的极大似然函数,推导出来的交叉熵
为什么要使用极大似然函数作为损失函数?
大似然函数取对数以后等同于对数损失函数。在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的。
对每一个样本的概率相乘,我们希望事件的总概率越大越好。
问题二: LR如何解决低维不可分
过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。 具体方法:核函数,如:高斯核,多项式核等等
6. word2vec的知识点
问题一:cbow和skip-gram的区别,计算量/训练速度
(1)在cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,使用GradientDesent方法,不断的去调整周围词的向量。要注意的是, cbow的对周围词的调整是统一的:求出的gradient的值会同样的作用到每个周围词的词向量当中去。可以看到,cbow预测行为的次数跟整个文本的词数几乎是相等的
(2)skip-gram是用中心词来预测周围的词。在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量。skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。 CBOW
问题二:讲一下skip-gram的结构以及原理
问题三:讲一下 CBOW的结构以及原理
7.评估指标
问题一: ROC和AUC
ROC由混淆矩阵得到,其中 召回是在实际正例中,预测为正例的比例,而precision是预测为正例中,实际为正例的比例。
ROC是TPR和FPR坐标组成的。TPR就是召回,FPR是实际为负例中预测为正例的比例。
AUC是曲线下面积。能表示模型的性能,尤其对样本不均衡的时候模型的性能。
AUC的实际意义是给出一个正样本,一个负样本。对正样本的预测分数大于 对负样本的预测分数的概率 这个概率值即是AUC值。
为什么说AUC能够代表 尤其对样本不均衡的时候模型的性能?
AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率。
但是如果使用AUC,假设这个模型是直接把所有的样本都预测为负值,那么这个时候TPR和FPR都是0,0 因为没有预测正例子的数,TP= FP=0 (TP是实际是正,预测为正;FP是实际是负,预测为正)
这时候把0,0和1,1连接
得出AUC仅为0.5,模型性能最差,成功规避了样本不均匀带来的问题。
问题二: MRR解释一下
第一个正确答案的排名的倒数。MRR是指多个查询语句的排名倒数的均值
8. 损失函数
问题一: 讲一下交叉熵的公式
公式如下:
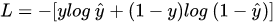
问题二:如果是多项式的话,如何写交叉熵的公式?
损失函数是
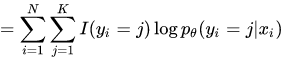
直接累加上去 就行。
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











