










论文题目:Fast Online EM for Big Topic Modeling
论文地址:http://ieeexplore.ieee.org/document/7302081/?arnumber=7302081&tag=1
论文大体内容:
本文针对LDA算法中的EM(expectation-maximization)操作,提出FOEM(fast online EM),进行时空复杂度上的优化,使得使用大数据集跑LDA在普通一台PC上也能很快跑出结果。
1、本文定义的big topic modeling是满足以下条件的:
①文档数目N过大,超过10^7;
②LDA过程中的参数(中间变量等)过大,超过10^9;
③topic的数目K过大,超过10^5;
④词典M的数目过多,超过10^5;
2、解决big topic modeling一般有2个方向:online,并行。并行往往需要更多的硬件,花费较大,而online则是更廉价的方法,所以本文是往online方向走的。
3、LDA原始的BEM(Batch EM)算法如下图,现在主要有2种online EM算法,包括IEM(incremental EM,逐步式EM),SEM(stepwise EM,阶梯式EM),算法如下图。其中:
①BEM:对于先对每个非0元素全部进行E操作,再进行M操作;
②IEM:对于每个非0元素,E操作(使用其它值更新当前值)之后进行M操作,M操作不需要等待所有非0元素的E操作结束后才进行,能够并行处理;
③SEM:对于数据,分成多个小的数据集,然后流式地对每个小数据集进行BEM操作,使得算法能够适应无穷无尽的大数据;



4、本文提出FOEM算法,从以下2个方面降低时空复杂度:
①dynamic scheduling(动态调度):为了降低时间复杂度,提出一个残差动态调整方法,选择出部分重要的主题相关内容进行更新,这样能够提升收敛速度;
②parameter streaming(流式参数):为了降低空间复杂度,提出流式加载参数(如中间矩阵,U(M*K)跟V(K*N))而非一次性全部load到内存中,建立一个确定大小的Buffer空间,将需要用到的内容以及不需要用到的内容,不断地在Buffer空间中与硬盘空间中交换,从而节省内存空间,但是这样操作肯定会降低运行效率;

5、各个算法的时空复杂度分析如下图:
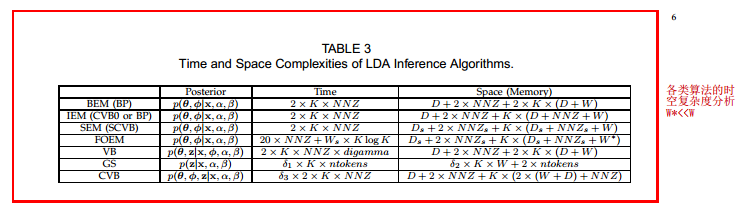
6、使用到的dataset:
①ENRON[1]:公司的邮件文本;
②WIKI:Wikipedia;
③NYTIMES[2]:纽约时报的文章;
④PUBMED[3]:生物医学搜寻引擎的文章摘要;
7、baseline:OGS,OVB,RVB,SOI,SCVB;
8、参数设定: α = β = 0.01
9、评测标准:
Predictive perplexity:衡量topic model得到的topic效果好坏的方法,但现已不常用,常用topic coherence衡量;
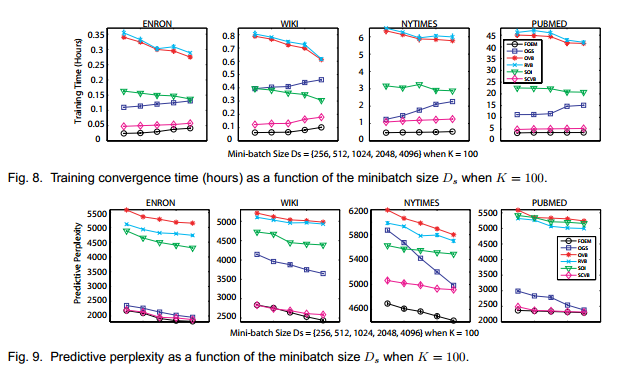
10、实验结果:
无论是时间效率,还是Predictive perplexity,都比baseline好。
参考资料:
[1]、www.cs.cmu.edu/~enron/
[2]、www.ldc.upenn.edu
[3]、www.pubmed.gov
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!














 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









