









论文题目:DocChat: An Information Retrieval Approach for Chatbot Engines Using Unstructured Documents
论文地址:https://www.aclweb.org/anthology/P/P16/P16-1049.pdf
论文大体内容:
现有的问答聊天系统很多都是直接从收集到的QR(utterance-response) pairs中直接找回答,所以本文提出DocChat的方法,能够从非结构化文档中寻找回答,以此来达到更好的机器问答聊天的效果。
1、现有的机器问答聊天的常用方法一般有2种:
①Retrieval-based methods:直接从现有的QR pairs中找最相近的Q’,R’,从而找出回答;
②Generation based methods:先对Q编码为向量,然后再使用该向量去解码生成回答;
但这两种方法均是使用QR pairs的。虽然随着social network的发展,QR pair越来越多,但这类型方法肯定会存在不足。
2、DocChat不直接使用QR pairs来找回答,而是使用各种文档里面的句子,找出最好的一个。这样做法的优点是能够适应更多的聊天主题和内容,回答得也更流畅、通顺。
3、DocChat总体的framework包含3个方面:
①Response retrieval:从文档中找出候选回答的句子;
②Response ranking:从候选中选择最优的;
③Response triggering:根据阈值判断是否输出②中的结果;
4、Response retrieval
基于一个直觉的假定:问题与回答是上下文关系的。所以从dataset中提取三元组<S前一个,S,S后一个>;
5、Response ranking
对于每个候选句子,排序得分Rank(S, Q)的计算方式:
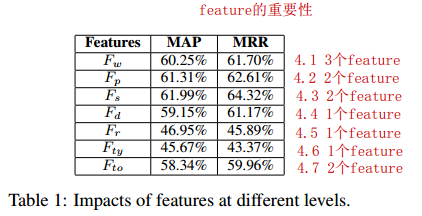
其中,本文使用了7个level的feature:(总体的方式都是用cosine之类的操作比较S与Q的相似度)
(1) Word-level Feature
①Hwm(S, Q):IDF值的向量;
②Hw2w(S, Q):使用GIZA++[6]方法训练出来的词到词关系的向量;
③Hw2v(S, Q):使用word2vec训练出来的向量;
(2) Phrase-level Feature
①Hpp(S, Q):统计机器翻译(SMT,statistical machine translation)中获得的短语与短语间的关系,计算时使用同种语言;
②Hpt(S, Q):统计机器翻译(SMT,statistical machine translation)中获得的短语与短语间的关系,计算时使用不同语言;
(3) Sentence-level Feature
①Hscr(S, Q):CNN训练出来的关系作cosine操作,使用question-answer pairs作input;
②Hsdr(S, Q):CNN训练出来的关系作cosine操作,使用sentence-next sentence pairs作input;
(4) Document-level Feature
①Hdm(S*, Q):与Hscr(S, Q)计算方式一样,只不过S换成上下文S*了;
(5) Relation-level Feature
①Hre(S, Q):CNN训练出来的关系作cosine操作,使用question-relation pairs(来自于已知的knowledge base,如Freebase[7])作input;
(6) Type-level Feature
①Hte(S, Q):CNN训练出来的关系作cosine操作,使用question-type pairs(来自于已知的knowledge base,如Freebase[7])作input;
(7) Topic-level Feature
①Hutm(S, Q):非监督式topic model训练出来的关系作cosine操作,把Document映射到主题的维度,如LDA,PLSI等;
②Hstm(S, Q):CNN训练出来的关系作cosine操作,使用sentence-topic pairs(来自于Wiki的爬取,topic是爬取时sentence所在的content name,如计算机等)作input,作者把这个称为监督式topic model;
得到feature后,本文使用了SGD(Stochastic Gradient Descent)以回归的方式来训练这个Ranking的模型。
6、Response triggering
一般来说,机器聊天问答包含两类问题,闲聊灌水类(chit-chat utterances)和信息类(informative utterances),DocChat仅用于后者。
判断方式为: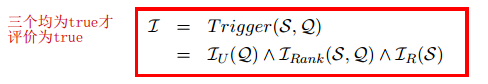
其中:
①Iu(Q)是使用训练好的分类器判断Q是闲聊灌水类还是信息类的问题;
②Irank(S, Q)是用于判断得分是否超过阈值;
③Ir(S)是用于限制句子长度小于阈值,且句子不是由递进关系词(but also,besides等)开始的;
7、Dataset
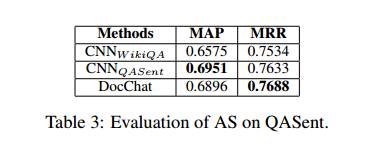
①WikiQA[1]:question-document-label格式(每一行),label是1代表回答是好的,否则是差的。training set包含2118行,development set包含296行,testing set包含633行;
②QASent[5]:question-answer式数据集,里面training set包含94个数据,development set包含80个数据,testing set包含100个数据;
8、评判标准:MAP(Mean Average Precision),MRR(Mean Reciprocal Rank);
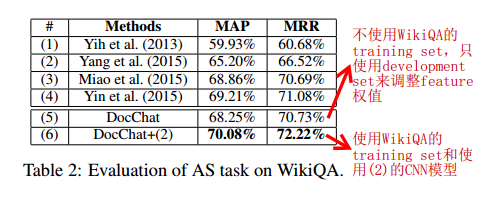
9、Baseline
①《Question Answering Using Enhanced Lexical Semantic Models》[2],使用了丰富的词汇语义特征;
②《WIKIQA: A Challenge Dataset for Open-Domain Question Answering》[1],使用了bigram CNN model with average pooling;
③《Neural Variational Inference for Text Processing》[3],使用了an enriched LSTM with a latent stochastic attention mechanism to model similarity between Q-R pairs;
④《ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs》[4],做法是adds the attention mechanism to the CNN architecture;
10、结果如下,效果表现得比state-of-the-art的好。
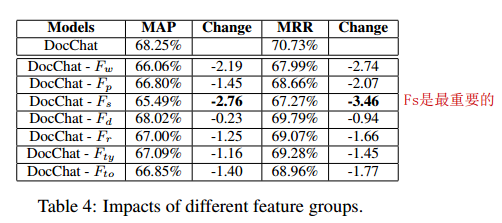
11、上面是对于英文的实验,对于中文,作者将DocChat与XiaoIce(小冰)作对比。通过人工评测两者在相同问题下的回答结果,发现DocChat略胜一筹。

12、思考
机器问答聊天方法的思路都是比较固定的,基本就是找候选回答,再进行打分排名,再输出。DocChat相比于之前的直接从QR pairs中抽取回答的方法,最大的好处就是能够使用更多的数据,从而能够找出更好的回答,而对于framework来说,找feature是最重要的一步,DocChat使用了7大类不同层面的feature,最后将他们线性加权组合。这样的模型在未来如果发现有更好的feature,往里面加也是特别容易的,所以在工程层面确实是不错的framework。不可置疑,framework思想简单,但是工作量还是非常大的,毕竟就每个feature来说,提取的工作包括从中训练CNN等模型,而且还得对于不同的数据调整CNN模型的参数等,工作量就已经上去了,何况是7大类共12个feature。当然了,我认为DocChat仅考虑了一轮问答的情况,并且是信息类的问答,这样对于科研做实验确实是比较简单,并且容易对比,但对于一个成熟的机器问答聊天系统,如XiaoIce,用户往往倾向更多的是闲聊,所以真正对做一个可用的系统,还真心不容易。
13、别人的评价
–在本次ACL中,我们的文章DocChat: An Information Retrieval Approach for Chatbot Engines Using Unstructured Documents讲述了一种基于检索与排序直接从非结构化文档中选取句子作为聊天机器人回复的方法。以往的方法无论是基于检索的还是基于生成的,都会依赖大量的对话句对作为训练数据。而在给定领域的情况下,大量的对话语料是比较难以获得的,但普通的文本就容易获取的多。我们的方法现在已经运用于新一代的微软小冰跨平台商业解决方案之中,助力小冰的自主知识学习技能。[8]
–本文解决的问题思路比较简单,但中间用到了很多复杂的DL model,个人感觉有点杀鸡用牛刀。本文的思路更加适合informative式的query,并不适合娱乐和闲聊。但用外部知识,尤其是大量的非结构化的、可能还带有噪声的资源来提供response,是一个很不错的思路,弥补了只用training data或者很有限的examples存在的局限性问题,如果可以将两者进行结合,是一个非常好的实用方案。[9]
参考资料:
[1]、http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.698.1566&rep=rep1&type=pdf
[2]、http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.386.9884
[3]、https://arxiv.org/abs/1511.06038
[4]、https://arxiv.org/abs/1512.05193
[5]、http://www.aclweb.org/old_anthology/D/D07/D07-1.pdf#page=56
[6]、http://dl.acm.org/citation.cfm?id=1073462
[7]、http://freebase.com/
[8]、http://blog.sina.com.cn/s/blog_4caedc7a0102wjz7.html
[9]、http://rsarxiv.github.io/2016/08/16/PaperWeekly-%E7%AC%AC%E4%BA%8C%E6%9C%9F/
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 1663
1663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









