







面试中经常会被问到,hashMap、treeMap、linkedHashMap有什么区别,内部实现逻辑如何?今天我就来深度剖析下这三个东西
先总体说下这三个东西的区别,然后再深入一个一个解剖他们:
hashMap是以哈希表结构(数组+链表)实现的以键值对存储的高性能存取集合,数据的存取都是无序的,非线程安全的数据结构
LinkedHashMap是继承于HashMap,基于HashMap和双向链表来实现的。有序存取,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。默认遍历的时候按照插入顺序读取,也就是说你插入的是什么顺序,读出来的就是什么顺序
TreeMap是实现SortMap的接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
hashMap
1.HashMap的数据结构?
哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点。当链表长度超过8时,链表转换为红黑树。
2.HashMap的工作原理?
java8之后,HashMap底层是hash数组+单向链表+红黑树实现,数组中的每个元素都是链表,由Node内部类(实现Map.Entry<K,V>接口)实现,HashMap通过put&get方法存储和获取。
put方法实现原理:
1. 调用key的hashCode方法计算Key的hash值
2. 通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上
3. 如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾,如果链表长度超过8,转换成红黑树存储。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
get方法实现原理:
1. 先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
2. 通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表或者红黑树,那么它就会拿着K和单向链表上的每一个节点的K进行equals,或者通过红黑树进行二分搜索。如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
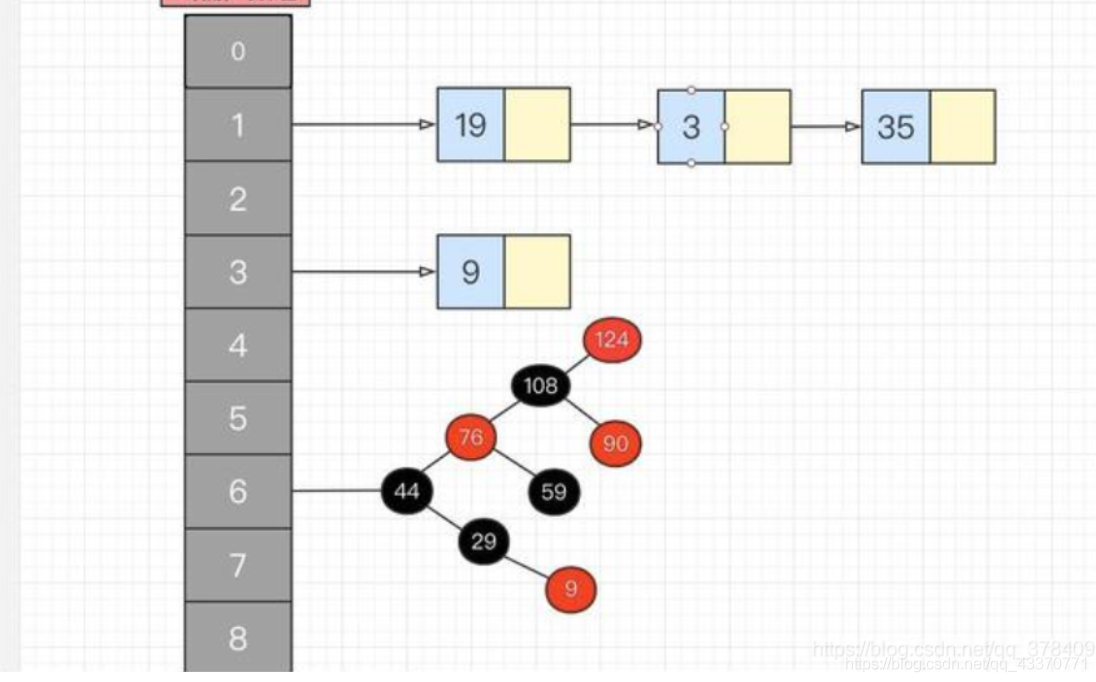
为什么放在hashMap集合key部分的元素需要重写equals方法?
因为equals方法默认比较的是两个对象的内存地址
二:HashMap红黑树原理分析
相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,当hash表的单一链表长度超过 8 个的时候,链表结构就会转为红黑树结构。
为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。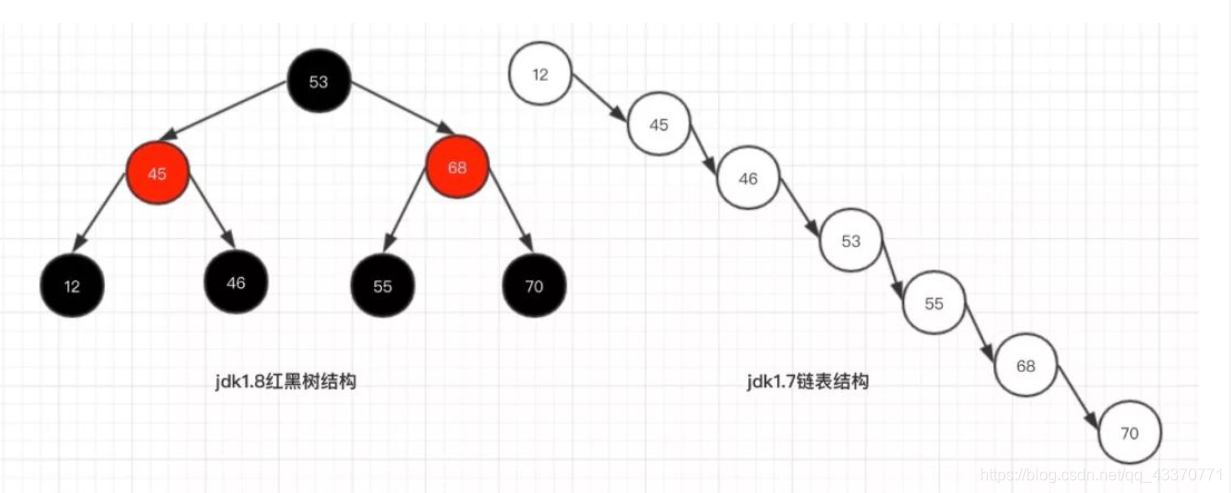
- 红黑树查询:其访问性能近似于折半查找,时间复杂度 O(logn);
- 链表查询:这种情况下,需要遍历全部元素才行,时间复杂度 O(n);
红黑树是一种近似平衡的二叉查找树,注意,红黑树一定是二叉查找树,还兼有一个重要的优点就是“平衡“,即左右子树高度几乎一致,以此来防止树退化为链表,通过这种方式来保障查找的时间复杂度为 log(n)。
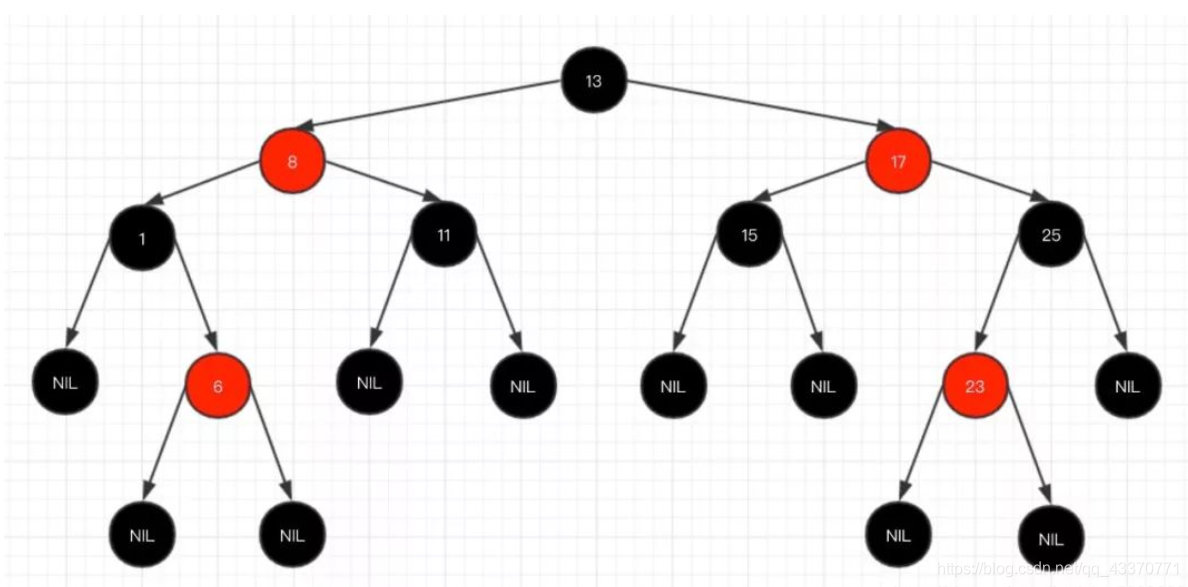
关于红黑树的内容,面试的时候问的非常多,一定要了解其特点,主要有以下几个特性:
1、每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
2、每个红色节点的两个子节点一定都是黑色;
3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
4、从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
5、所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件 3 或条件 4,需要通过调整使得查找树重新满足红黑树的条件。
如何重新调整HashMap的大小
“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
HashMap的扩容阈值,就是通过它和size进行比较来判断是否需要扩容。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,将会创建原来HashMap大小的两倍的bucket数组(jdk1.6,但不超过最大容量),来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。这是一个比较耗性能的过程,所以如果能够提前预判的需要put进去key的个数,可以先指定hashMap的大小
hashMap和hashTable
相同点
HashMap 和 HashTable 都是基于哈希表实现的,其内部每个元素都是 key-value 键值对,HashMap 和 HashTable 都实现了 Map、Cloneable、Serializable 接口。
不同点
父类不同:HashMap 继承了 AbstractMap 类,而 HashTable 继承了 Dictionary 类;空值不同:HashMap 允许空的 key 和 value 值,HashTable 不允许空的 key 和 value 值。HashMap 会把 Null key 当做普通的 key 对待。不允许 null key 重复。HashMap 不是线程安全的,而hashTable是线程安全的, put 和 get 操作都是加了 synchronized 锁的,当然,结果就是牺牲性能,效率很差。HashTable 的初始长度是11,之后每次扩充容量变为之前的 2n+1(n为上一次的长度)而 HashMap 的初始长度为16,之后每次扩充变为原来的两倍。创建时,如果给定了容量初始值,那么HashTable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小
HashMap 和 HashSet 的区别
HashSet 继承于 AbstractSet 接口,实现了 Set、Cloneable,、java.io.Serializable 接口。HashSet 不允许集合中出现重复的值。HashSet 底层其实就是 HashMap,所有对 HashSet 的操作其实就是对 HashMap 的操作。所以 HashSet 也不保证集合的顺序。














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









