






🍟项目背景
Stability.ai又又又发布了一个新的模型,这次带来的是SV3D,一款基于图像生成3D的模型。
这次发布的模型有两个变体:SV3D_u 和 SV3D_p。SV3D_u 基于单个图像输入生成轨道视频,无需相机调节。SV3D_p 通过容纳单个图像和轨道视图来扩展功能,从而允许沿着指定的相机路径创建 3D 视频。


按照stablityai的风格,人狠话不多,直接模型已经放再huggingface上供大家免费下载了,这次的模型都比较大,每一个都有9G多。
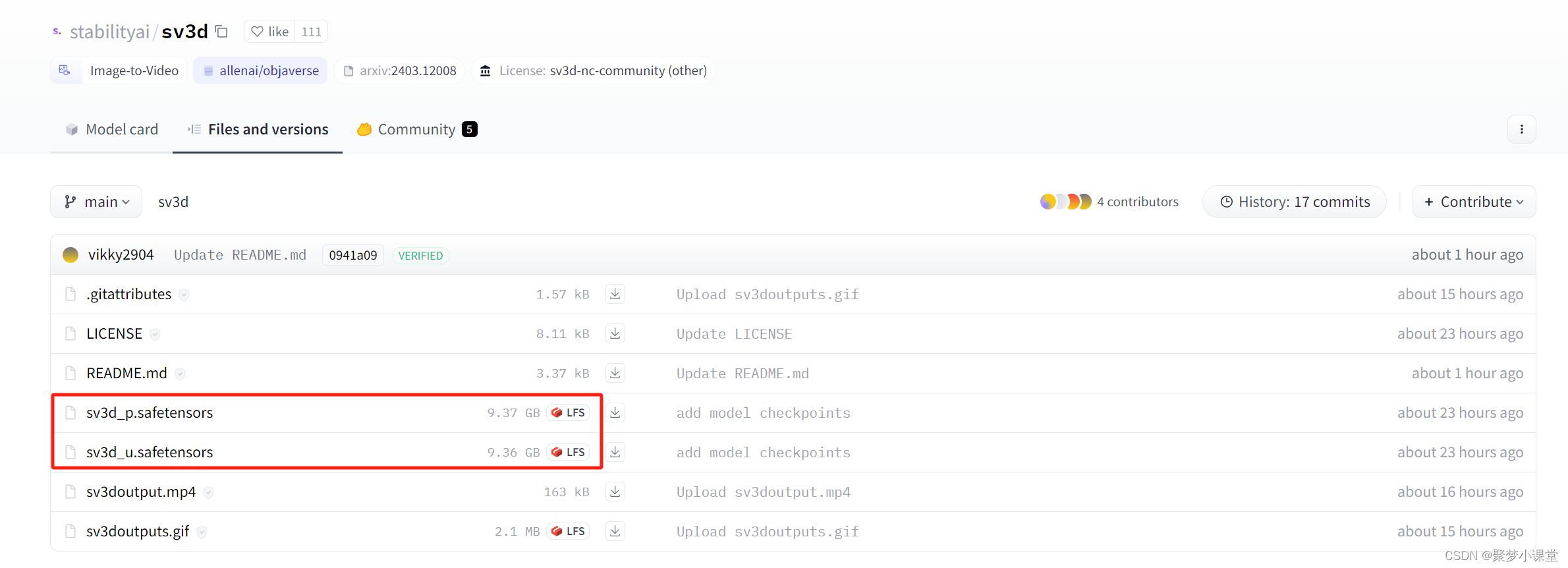
官方下载地址:https://huggingface.co/stabilityai/sv3d/tree/main
因为这个要验证才能下载,所以镜像站下载比较麻烦,这里还是提供下网盘下载地址:
https://pan.quark.cn/s/345e4d602d87
按照官方的说法,这次的模型效果比之前的各种版本和别人的都好很多,有图为证:

但实际效果如何呢?我们不妨下载实验一下。
🌭实验方法
1、下载模型,具体地址在上边已经提到;
2、下载完模型之后,需要把模型放在本地的models文件夹下就好,跟其他的大模型放一块,也可以建个二级目录;
3、升级comfyui到2023.3.19号或者更新的版本,这样才能默认支持这个节点;
4、搭建基础的工作流,这个比较简单,我这里截图一下,大家需要可以直接自己搭建即可。

如果实在懒得自己搭建,也可以到网盘地址下载,还是这个目录:https://pan.quark.cn/s/345e4d602d87

5、跑图,注意输入的图像最好是纯色,或者简单的背景,否则效果比较差,另外实验的过程中,发现透明底色也不太好用,所以可以ps中简单处理一下背景为纯黑;
效果参考:

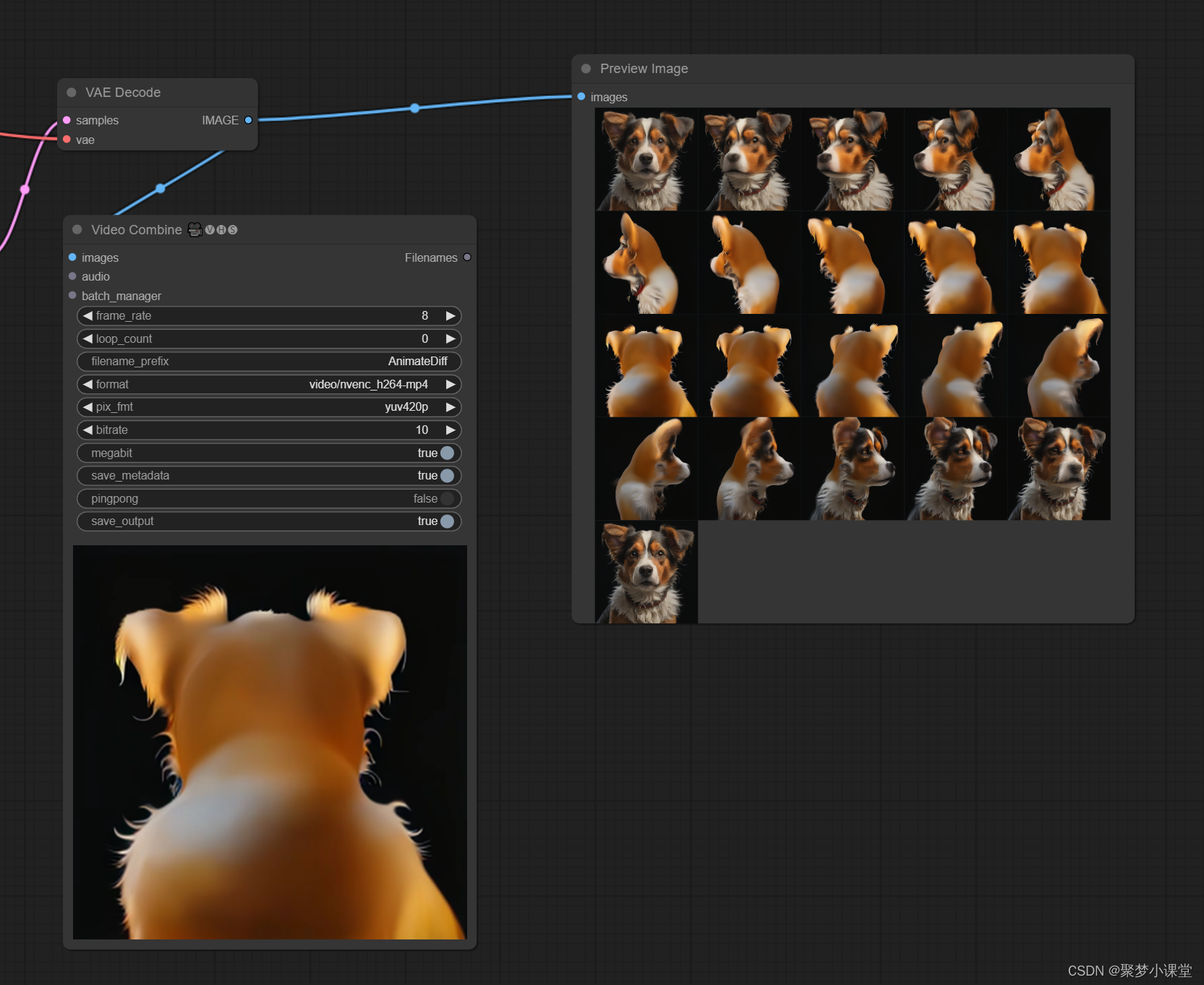
只能说,效果相当一般。
可以再等等。
🎉写在最后~
去年的时候写了两门比较基础的Stable Diffuison WebUI的基础文字课程,大家如果喜欢的话,可以按需购买,在这里首先感谢各位老板的支持和厚爱~
✨StableDiffusion系统基础课(适合啥也不会的朋友,但是得有块Nvidia显卡):
https://blog.csdn.net/jumengxiaoketang/category_12477471.html
 🎆综合案例课程(适合有一点基础的朋友):
🎆综合案例课程(适合有一点基础的朋友):
https://blog.csdn.net/jumengxiaoketang/category_12526584.html
这里是聚梦小课堂,就算不买课也没关系,点个关注,交个朋友😄

















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











