








目录
1.数据预处理
1.1 中心化
每个特征维度都减去相应的均值实现中心化,这样可以使得数据变成0均值,尤其是对于图像数据,为了方便,将所有的数据都减去一个相同的值。
1.2 标准化
在使得数据都变成0均值后,还需要使用标准化的做法让数据不同的特征维度都有着相同的规模。有两种常见的用法:一种是除以标准差,这样可以使得新数据的分布接近标准高斯分布;还有一种做法是让每个特征维度的最大值和最小值按比例缩放到 -1 ~ 1 之间。
如果数据的输入特征有着不同的规模,那就需要使用标准化的做法让它们处于同一规模中。

1.3 PCA
PCA是另一种处理数据的方法,在进行这一步之前,首先要将数据中心化,然后计算数据的协方差矩阵。比方说,假设输入是 X = N x D ,那么通过

能够得到协方差矩阵,可以验证一下这个结果的正确性,而且这个协方差矩阵是对称半正定的,可以通过这个协方差矩阵来进行奇异值分解(SVD),然后对数据进行去相关性,将其投影到一个特征空间,我们能够取一些较大的、主要的特征向量来降低数据的维度,去掉一些没有方差的维度,这也叫做主成分分析(PCA)。
这对于一些线性模型和神经网络,都能取得良好的效果。
1.4 白噪声
白噪声也是一种处理数据的方式,首先会跟PCA一样将数据投影到一个特征空间,然后每个维度除以特征值来标准化这些数据,直观上就是一个多元高斯分布转化到了一个0均值,协方差矩阵为1的多元高斯分布。

白噪声的处理会增强数据中的噪声,因为其增强了数据中的所有维度,包括一些很小的不相关的维度。
2. 权重初始化
2.1 全0初始化
该策略效果并不是很好,因为如果神经网络中每个权重都被初始化成相同的值,那么每个神经元就会计算出相同的结果,在反向传播的时候也会计算出相同的梯度,最后导致所有权重都会有相同的结果。也就是说,如果权重结果相同的话,那么权重之间失去了不对称性。
2.2 随机初始化
初始化权重为一些靠近0的随机数,通过这个方式打破对称性。
一般的随机化策略有高斯随机化、均匀随机化。但并不是越小的随机化产生的结果越好,因为权重初始化越小,反向传播中关于权重的梯度也越小,因为梯度与参数的大小是成比例的,所以这会极大地减弱梯度流的信号,成为神经网络训练的一个隐患。
这个初始化策略还存在一个问题就是网络输出分布的方差会随着输入维度的增加而增大。
2.3 稀疏初始化
将权重全部初始化为0,然后为了打破对称性,在里面随机挑选一些参数附上一些随机值。这种方法的好处是参数占用的内存较少,因为里面有较多的0,但实际中使用较少。
2.4 初始化偏置
对于偏置,通常是初始化为0,因为权重已经打破了对称性,所以使用0来初始化是最简单的。
2.5 批标准化
它的核心是标准化这个过程是可微的,减少了很多不合理初始化的问题,所以我们可以将标准化过程应用到神经网络的每个层中做前向传播和反向传播,通常批标准化应用到全连接层后面、非线性层前面。
批标准化成为了神经网络的一个标准技术,特别是在卷积神经网络中,它对于很坏的初始化有很强的鲁棒性,同时还可以加快网络的收敛速度。另外,批标准化可以理解为在网络的每一层前面都会做数据的预处理。
3. 防止过拟合
3.1 正则化
L2正则化是正则化中比较常用的形式,它的想法是对于权重过大的部分进行惩罚,也就是在损失函数中增加权重二范数量级,也就是

,其中是正则化强度,通常使用0.5.L2正则化可以看成是权重更新在原来的基础上再 -![]() ,这样可以使得参数更新之后更加靠近0.
,这样可以使得参数更新之后更加靠近0.
L1正则化,其在损失函数中增加权重的1的范数,也就是

,
也可以把L1正则化和L2正则化结合起来。L1正则化相对于L2正则化的优势是在优化的过程中可以让权重变得更加稀疏,也就是说在优化结束的时候,权重智慧取一些与最重要输入有关的权重,这使得与噪声相关的权重被尽可能降为0.
3.2 Dropout
Dropout是最为广泛的防止过拟合的方法。其核心思想是在训练网络的时候依概率P保留每个神经元,也就是说每次训练的时候有些神经元会被设置为0.
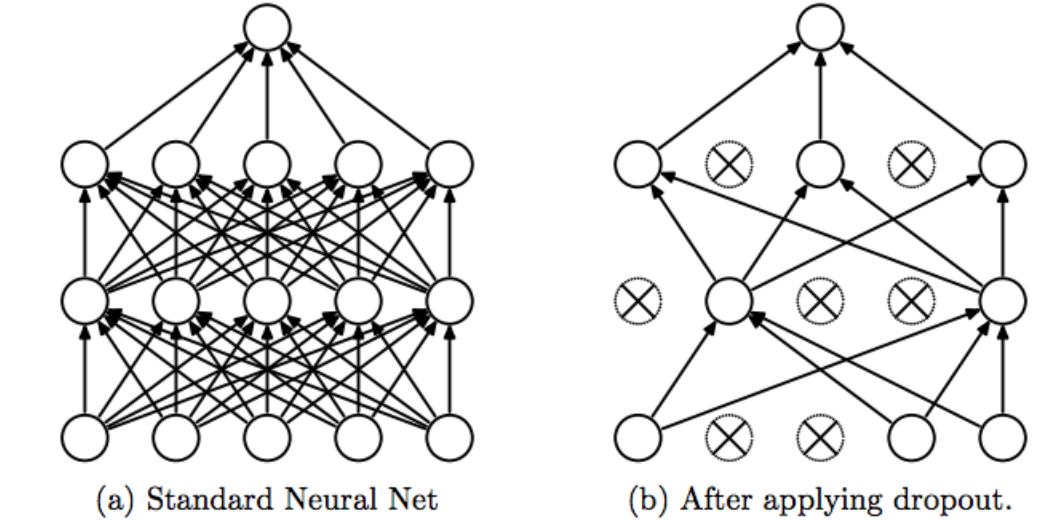
在实际应用中,一般采用全局权重的L2正则化搭配Dropout来防止过拟合。















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









