







目录
注:北大刘宏志老师的《推荐系统》课程学习,图片来源于课程PPT和参考书籍
1、基于关键词的模型缺点
只关注词形,忽略语义,无法准确计算词义相似但是词形不同的相似度,例如“西红柿”和“番茄”。
2、基于语义的文本相似度
-
依赖额外的语义知识
-
基于知识库 ---- 基于语料库
-
基于显式语义的模型-----基于隐式语义的模型
3、基于本体的相似度模型
3.1 基本思想和数据源

图3.1 基于本体的相似度模型思想
3.2 词之间相似度度量方法
3.2.1 基于最短路径
思想:本体库(语义信息网络)中两个概念词越相近,语义越相似。LCS考虑词的level,因为词的level越高,那么抽象程度越高,相同距离下的相似度就比level低的高。

图3.2 两种最短路径计算方法
4、基于网络知识的文本相似度模型
基于本体(语义信息网络的模型)实体不全、更新速度慢的问题。而网络知识更新速度快、覆盖的范围更广。
4.1、显式语义分析ESA模型
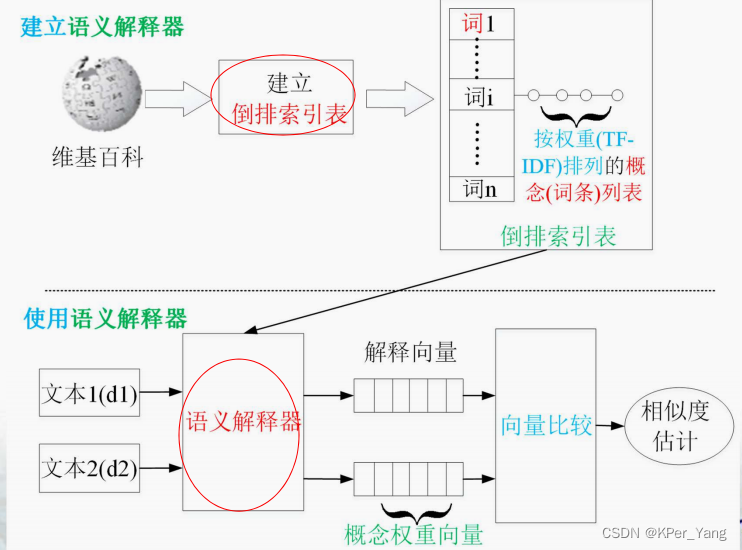
图4.1 ESA模型
4.2 ESA模型的示例:
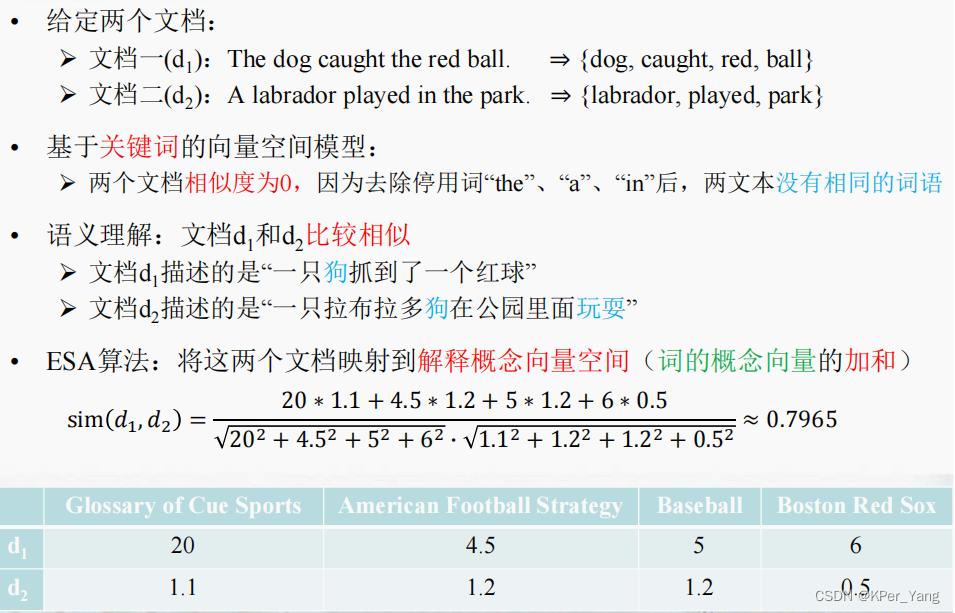
图4.2 ESA模型示例
5、基于语料库的文本相似度模型
相比于网络知识库(如百度百科),语料库更容易获取,且覆盖面更全面。
分成基于点式互信息PMI和词嵌入两种模型

图 5.1 基于语料库的两种文本相似度度量方法
















 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











