







一、项目背景
本项目基于淘宝app平台数据,通过相关指标对行为进行分析,探索消费者相关行为模式
分析方法:
用户行为分析:日pv和日uv分析,时pv和时uv分析,不同行为类型用户的pv分析
用户消费行为分析:用户购买次数情况分析,日ARPPU,日ARPU,付费率,
同一时间段用户消费次数分布
复购情况分析:所有复购时间间隔消费次数分布,不同用户平均复购时间分析
漏斗流失分析:浏览到点击,点击到加购物车,加购物车到收藏,收藏到付款
用户价值分析:RFM模型
导入库,导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
sns.set(style = 'darkgrid',font_scale = 1.5)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
os.chdir(r'F:\数据分析数据压缩包\tb_data')
ud= pd.read_csv('tbdata.csv',encoding = 'ISO-8859-1',dtype = str)
二.大致浏览数据的情况,行列数,数据类型
#有大约1200万条数据,共六个字段,
#是2014年11月18日至2014年12月18日的用户行为数据,均为object类型,分别为user_id(用户ID),
#item_id(商品ID),behavior_type(行为类型), user_geohash(用户地理位置),
# item category (商品种类) ,time(行为发生时间)
ud.info()
ud.head(20)
ud.groupby('user_id')['user_id'].size()
#数据集包括10000用户
结果:

三.数据预处理
3.1 重复值处理
# 重复值处理
#计算重复值个数
ud.duplicated().sum()
print('重复值个数为',ud.duplicated().sum())
#剔除重复值
ud.drop_duplicates(inplace = True)
#剔除重复值后的数据规模
ud.shape

剔除重复值后的数据规模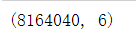
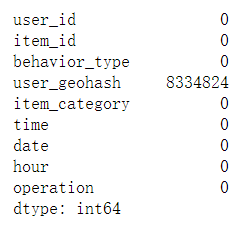
#每个字段缺失值的数量
ud.apply(lambda x:sum(x.isnull()))
#只有地理位置数据缺失
#地理位置字段的缺失率
ud['user_geohash'].isnull().sum()/len(ud['user_geohash'])
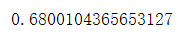
日期数据的处理(拆分和类型转化)
#由于time字段的数据包括了日期和小时,把time拆分成date和hour
ud['date'] = ud['time'].str[0:10]
ud['hour'] = ud['time'].str[11:]
ud.dtypes
# #把time,date转化成datetime类型数据,hour转化成int类型数据
ud['time'] = pd.to_datetime(ud['time'])
ud['date'] = pd.to_datetime(ud['date'])
ud['hour'] = ud['hour'].astype(int)
#查看是否数据类型是否转化成功
ud.dtypes
#将数据按照时间的发生前后按升序处理
ud.sort_values(by = 'time',ascending = True,inplace = True)
#此时列前面的索引已经乱掉,重置索引
ud.reset_index(drop = True,inplace = True)
四、用户行为分析
pv (page view):
每天访问浏览页面的点击量或次数,页面被刷新一次就计算一次,点了100次,pv = 100
uv (unique visitor):
独立访客的意思,访问网站的客户端或电脑为一个访客。由于一个客户可能会有多台电脑即
多个访客,但还是作为一个访客看待
4.1 分析日浏览及访客量变化
# 将数据按照日期分类,并计算每一天的活跃用户总数
ud1 = ud.groupby('date').count()
#将ud1的user_id字段名改为pv_daily
ud1.rename(columns = {
'user_id':'pv_daily'},inplace = True)
# 把ud1的‘pv_daily’赋值给pv_daily
pv_daily = ud1['pv_daily']
pv_daily
#统计一下按照日期分类好的,每天的日uv值
uv_daily = ud.groupby('date')['user_id'].apply(lambda x:x.drop_duplicates().count())
uv_daily
#或者直接采取先在原表中去重,再根据日期分组后选取user_id列进行计数
ud2 = ud.drop_duplicates(['date','user_id'])
ud2 = ud2.groupby('date').count()
ud2.rename(columns = {
'user_id':'uv_daily'},inplace = True)
uv_daily = ud2['uv_daily']
uv_daily
#或者这个方法也可以,三者选一即可
ud.groupby(['date'])['user_id'].unique().apply(lambda x:len(x))
将pv,uv拼接在一起,做相关系数分析
#pv_uv_daily就是根据日期统计出来的:每日访问量 以及独立访客数
pv_uv_daily = pd.concat([pv_daily,uv_daily],axis = 1)
pv_uv_daily
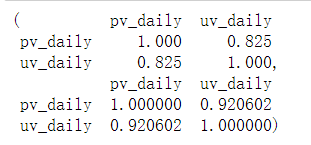
#计算pv和uv的斯皮尔曼相关系数
pv_uv_daily.corr(method = 'spearman')
#计算pv和uv的皮尔森相关系数
pv_uv_daily.corr(method = 'pearson')
输出结果:
#绘图,同一张图,不同子图
plt.f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8252
8252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









