






「双塔各种改造方法概览:」
「写在前面:」
本系列文章主要介绍双塔结构在工业界的落地及改造升级方案,本系列相关文章汇总如下:
4. 基于Learning to Rank的双塔召回
4.1 双塔召回为什么要从Pointwise升级到Pairwise?
Learning to Rank根据损失函数、输入空间、输出空间、优化方法的不同,可以分为三大类方法:Pointwise、Pairwise、Listwise。
Pairwise Rank顾名思义,即为“逐对”的排序方法。相比于之前的Pointwise Rank,它更关注的是item与item之间的相对顺序关系,而不是去学得一个具体的相关程度的打分。
双塔召回根据学习目标的不同,可以分为回归目标和分类目标。回归目标采用的损失函数是MSE,分类目标采用的损失函数是交叉商。从LTR(Learning to Ranking,LTR)的角度来说,这两个损失函数都是Pointwise loss。这种以单点精度为优化目标的Pointwise方法也存在很多问题:
Pointwise只考虑单个item与user的相关性,没有考虑item间的关系,然而排序追求的是排序结果,并不要求精确打分,只要有相对打分即可;
通过分类只是把不同的item做了一个简单的区分,同一个类别里的item则无法深入区别,虽然我们可以根据预测的概率来区别,但实际上,这个概率只是准确度概率,并不是真正的排序靠前的预测概率,Pointwise的单点精度和顺序的不一致性;
Pointwise方法并没有考虑同一个user对应的item间的内部依赖性。一方面,导致输入空间内的样本不是"独立同分布"的,违反了机器学习的基本假设;另一方面,没有充分利用这种样本间的结构性。其次,当不同user对应不同数量的item时,整体loss将容易被对应item数量大的user组所支配,应该每组user都是等价的才合理。
解释这一条,单从PointWise的机制来看,它只是非常简单粗暴地将user与item间的相关度作为排序的评判标准,但是用户跳过查询或推荐结果的第一条去点击第二条的原因可能并不是第一条内容不相关,而是因为第二条的标题或者配图更加符合用户的心理预期,这个时候来看,其实真实场景下的排序并不是简单只看user与item的相关度的,它会受到user对应item间的相互影响,也就是说PointWise所应用的真实场景并不是 "IID" 的,这里的Pointwise只是简化问题假设IID的,但也会带来不小的误差,不过大部分情况下,这种误差是我们能够接受的。
很多时候,排序结果的Top N条的顺序重要性远比剩下全部顺序重要性要高。因为Pointwise损失函数没有建模items间相对排序位置信息,这样会使损失函数可能无意的过多强调那些不重要的item,即那些排序在后面对用户体验影响小的item,所以对于位置靠前但是排序错误的item应该加大惩罚。
这里留两个小问题:
Pointwise、Pairwise、Listwise的区别和联系?
在推荐的召回/粗排/精排中怎么建模Pairwise和Listwise?
4.2 Pairwise的双塔召回建模细节
(1)样本构造
Pointwise双塔召回经常遵循"CTR预估"的方式:
样本上,<user,item+,1>和<user,item−,0>是两条样本;
loss上使用binary cross-entropy这样的Pointwise loss;
能够这么做的前提是,其中的<user,item−,0>是“曝光未点击”的“真负”样本,Label的准确性允许我们使用Pointwise loss追求“绝对准确性”。但是在召回场景下,以上前提并不成立。以常见的u2i召回为例,绝大多数item从未给user曝光过,我们再从中随机采样一部分作为负样本,这个negative label是存在噪声的。在这种情况下,再照搬排序使用binary cross-entropy loss追求“预估值”与“label”之间的“绝对准确性”,就有点强人所难了。所以,双塔召回算法可以升级采用Pairwise Learning to Rank(LTR),建模“「排序的相对准确性」”:
样本往往是<user,, >的三元组形式;
模型的优化目标是,「针对同一个user,与他的匹配程度,要远远高于,与他的匹配程度」。所以Loss中没有label,而存在“<user,>的匹配分”与“<user,>的匹配分”相互比较的形式。
(2)模型结构
我们首先从Pairwise模型结构来看一下:如下图,对于Pairwise模型来说,训练时基于pair对来进行输入,需要注意的是,虽然训练时为双塔结构,但Item塔可以理解为share的,实际上就是一个item塔,只不过对和分别forward了两次。
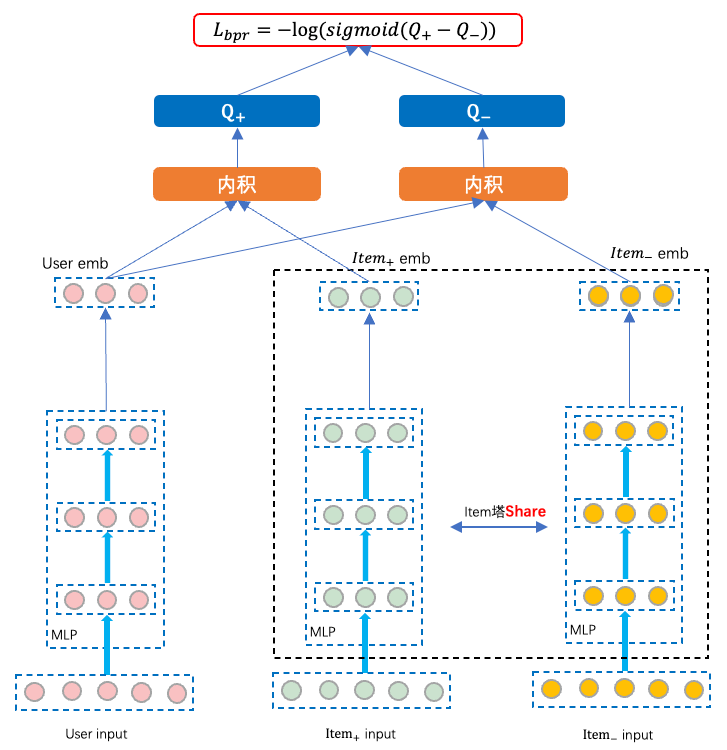
在真实的召回业务场景中,训练样本的Pair对构造相对会复杂一些。由于召回需要负采样,一般会采出N个Easy负样本加M个Hard负样本,那么构成的一条Pairwise的训练样本为:
有了训练样本后,我们来看看双塔模型是怎么训练的。Pairwise与Pointwise的区别在Item塔侧,由于我们有()个item样本,在特征处理阶段直接把每个item的tensor向量增加一个维度,即记录item的索引。然后对item塔进行一次前向传播,最终得到的item的Embedding向量维度为。这里有一个问题,就是User塔的输出为,而item塔的输出为,维度不同,怎么进行最终的loss计算呢?
这里在代码实现的时候有一个技巧。就是把Item塔的输出tf.transpose一下,变成,然后与user塔的输出计算DSSM模型中使用的(Sampled) Softmax loss。这里由于使用了Softmax loss,只取user embedding与的embedding计算余弦相似度,然后计算Softmax。这里考虑的点是,让user选中的概率尽可能高,那么就可以使得user与除之外的其它所有item的匹配度之和尽可能小。
线上Serving的时候,就和pointwise一样了。对于item侧,拿全库的item用基于Pairwise训练的item塔进行刷库,离线得到item embedding,然后把item embedding灌入faiss中。对于在线serving召回,实时得到user embedding,然后拿user embedding去faiss中检索Top K item。
(3)Pairwise损失函数的设计
召回中经常使用的Pair-wise loss总结:
「1)DSSM模型中使用(Sampled) Softmax」
这种loss将召回看成一个超大规模的多分类问题,优化的目标是使,user选中的概率最高。user选中的概率为:
其中是user embedding,代表item embedding,代表整个item候选集。为使以上概率达到最大,要求分子,即user与的匹配度,尽可能大;而分母,即user与除之外的所有item的匹配度之和,尽可能小。体现出pairwise的「“不与label比较,而是匹配得分相互比较”」 的特点。但是,由于计算分配牵扯到整个候选item集合,计算量大到不现实。所以实际优化的是sampled softmax loss,即从中随机采样若干,近似代替计算完整的分母。
「【推荐阅读】」
一文搞懂Approximate Softmax:从公式到代码 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/528862933
召回算法有哪些? - 石塔西的回答 - 知乎 https://www.zhihu.com/question/423384620/answer/1687201890
「2)Facebook EBR模型使用了margin Hinge Loss」
2020年Facebook的论文《Embedding-based Retrieval in Facebook Search》(EBR)使用的是margin hinge loss。优化目标是:user与正样本item的匹配程度,要比,user与负样本item的匹配程度,高出一定的阈值。即:
因为margin hinge loss多出一个超参margin需要调节,论文中也说了margin对于模型效果影响巨大。而BPR loss少了一个需要调整的超参,且根据经验及网上资料显示BPR loss效果要比margin hinge loss好,因此我常用BPR Loss。
「3)BPR loss」
其思想是计算"给user召回时,将排在前面的概率",即:
因为的ground-truth label永远是1,所以将喂入binary cross-entropy loss的公式,就有:
(4)Pairwise位置权重的优化
在做Pairwise损失函数的时候,有经验的算法工程师通常会为Pairwise损失函数加入位置权重。
我们从下图中考察RankNet学习过程中,列表的排序变化。
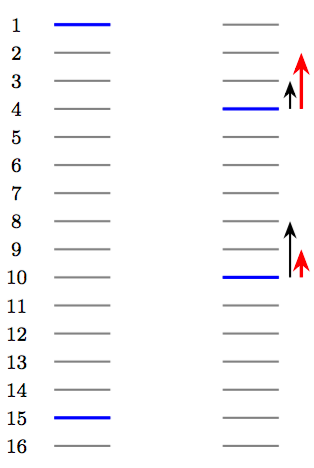
这里每条横线代表一个物品,其中蓝色的表示相关的物品,灰色的则表示不相关的物品。在某次迭代中,RankNet将物品的顺序从左边变成了右边。于是我们可以看到:
RankNet的梯度下降表现在结果的整体变化中是逆序对的下降。左图中,2~14不相关物品都排在了15号相关物品之前,这些不相关物品和15号物品构成的逆序对共13个,因此损失等价于为13;而右图中,将1号相关物品降到了4号,15号相关物品上升到了10号,此时逆序对的数量为3+8=11个,因此损失等价于11。
对于一些强调最靠前的TopN个物品的排序指标(NDCG、ERR等)而言,上述优化不是理想的。例如,右图下一次迭代,在RankNet中梯度优化方向如黑色箭头所示,此时损失可以下降到8;然而对于NDCG指标而言,我们更愿意看到红色箭头所示的优化方向(此时RankNet同样是8,但是NDCG指标相比前一种情况上升了)。
第一轮的时候逆序对数为13,第二轮为3+8=11,逆序对数从13优化到11,损失确实是减小了,如果用AUC作为评价指标,也可以获得指标的提升。但实际上,我们不难发现,优化逆序对数并没有考虑位置的权重,这与我们实际希望的排序目标不一致。下一轮迭代,RankNet为了获得更大的逆序对数的减小,会按照黑色箭头那样的趋势,排名靠前的文档优化力度会减弱,更多的重心是把后一个文档往前排,这与我们搜索排序目标是不一致的,我们更希望出现红色箭头的趋势,优化的重点放在排名靠前的文档,尽可能地先让它排在最优位置。所以我们需要一个能够考虑位置权重的优化指标。
「RankNet以优化逆序对数为目标,并没有考虑位置的权重,这种优化方式对AUC这类评价指标比较友好,但实际的排序结果与现实的排序需求不一致,现实中的排序需求更加注重头部的相关度,排序评价指标选用NDCG这一类的指标才更加符合实际需求。而RankNet这种以优化逆序对数为目的的交叉熵损失,并不能直接或者间接优化NDCG这样的指标。」
我们知道NDCG是一个不连续的函数,无法直接优化,那LambdaRank又是如何解决这个问题的呢?
我们必须先有这样一个洞察,对于绝大多数的优化过程来说,目标函数很多时候仅仅是为了推导梯度而存在的。而如果我们直接就得到了梯度,那自然就不需要目标函数了。
于是,微软学者经过分析,就直接把RankNet最后得到的Lambda梯度拿来作为LambdaRank的梯度来用了,这也是LambdaRank中Lambda的含义。这样我们便知道了LambdaRank其实是一个经验算法,它不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的梯度的物理意义,直接定义梯度,即Lambda梯度,只希望对的梯度可以按照理想NDCG指标的方向走。有了梯度,就不用关心损失函数是否连续、是否可微了,所以,微软学者直接把NDCG这个更完善的评价指标与Lambda梯度结合了起来,就形成了LambdaRank。
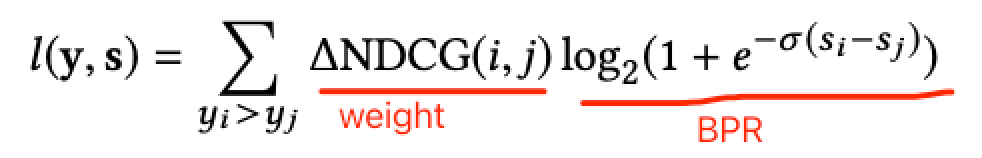
其中是文档与文档交换排序位置得到的NDCG差值。NDCG倾向于将排名高并且相关性高的文档更快地向上推动,而排名低而且相关性较低的文档较慢地向上推动,这样通过引入IR评价指标(Information Retrieval的评价指标包括:MRR,MAP,ERR,NDCG等)就实现了类似上面图中红色箭头的优化趋势。可以证明,通过此种方式构造出来的梯度经过迭代更新,最终可以达到优化NDCG的目的。
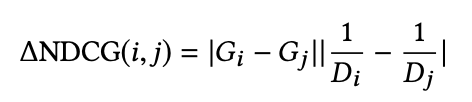
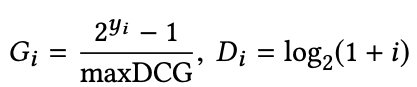
另外还可以将替换成其他的IR评价指标,比如ERR等(其实AUC也可,但不会这样用)。
「Reference:」
Wang X, Li C, Golbandi N, et al. The lambdaloss framework for ranking metric optimization[C]//Proceedings of the 27th ACM international conference on information and knowledge management. 2018: 1313-1322.
推荐系统中的排序学习 - 卢明冬的博客 ,地址:https://lumingdong.cn/learning-to-rank-in-recommendation-system.html#LambdaMART
排序学习调研 ,地址:http://xtf615.com/2018/12/25/learning-to-rank/
4.3 基于Listwise的双塔召回
Listwise方法中一个比较经典的工作是《Learning to Rank: From Pairwise Approach to Listwise Approach》。我们在这里可以省略各种数学推导,因为各种Listwise的loss都很好理解。比如下面这个:
其中就是这个List中每一个项的输出。前面的是一个标识物,在列表中越靠前,就越大。「当所有的项的得分由Softmax拉住之后,某一个项的变大会意味着别的项的减小。那么第一个项最大的“幅度”也最大,后面的项优化的幅度减小,就可以达到第一项排序靠前的目的」。的取值也可以多种多样,无具体语义的取法有按照List长度反过来取,比如长度为10,那么可以按照10,9,8……这样的顺序取。有具体语义的取法可以按照实际业务数据来,比如可以令等于一段时间累计的实际点击数。关于这个Loss本身也可以灵活处理,比如List有9项,我们可以最大化前三项,中间三项不作处理,最小化后三项。
另一种常见的Loss是把每一项都分开:
啥意思呢,就是先归一化1到N的分数,然后令最大(「所以说Listwise生效的方式是间接的,这两点组合起来才是1比其他的大的含义」);同样归一化2到N的分数,令在其中的打分最大,就是2比剩下的都大。以此类推就表现了1比2大,2比3大这样下去的目标。具体实现是可以用Log包住,这样就变成求和的形式。
还可以用hinge loss来添加别的目标,比如可以用:
表示“第一项只要大于第二项就可以”,以此类推用一系列hinge loss的叠加作为Listwise Loss。当然里面的0可以换成一个系数来表示“第一项必须大过第二项的幅度才可以”。
所以总结下来看,「Listwise的Loss没有什么固定的形式,根据实际业务把我们需要表达的东西表达到位就好」。
将Listwise应用在召回学精排的过程中是非常自然的,因为精排的输出本身就是一个List。不过不论是Pairwise还是Listwise,选取样本都应该有区分度。比如精排输出队列是100个,我们选取第1、20、50、100来组建List就比较有区分度,选择11、12这种相邻的不太好,因为这样的差距可能仅仅是噪声造成的。
注意,虽然从算法上讲Pairwise和Listwise的学习目标很好实现,但是在工程上是要费一番功夫的,如果我们选择Pair是精排的top1和精排最后的5个任意组合,那Pair就有至少5倍于原来Pointwise的训练开销(要训练5个Pair对)。
(1)Pairwise和Listwise的区别和联系?
样本构造上,Pairwise是构造正负样本Pair对,Listwise是构造一个有序的List列表。
训练Loss上,Pairwise和Listwise有属于各自的损失函数。
Pairwise表达的东西比较清晰,A比B大,写出来就是最大化A-B的得分。而Listwise的Loss表达的过程是有点间接的,需要借助归一化或者有界化等等才能表示出具体的含义。
Pairwise的收敛相对于List是要慢一些,「有拉扯的问题」:A大于B,可以是0.9大于0.8,也可以是0.2大于0.1,因此A和B的位置飘忽不定,必须得在大量的样本中反复震荡才能得到最终的位置。而Listwise一上来就给了大致范围:ABCDEF一个比一个大,那么大概可以说他们分别在1、0.8、0.6、0.4、0.2和0附近,省去了很多收敛的时间。不过Listwise想要看到全局,List的长度会比较长,一般在实现的时候这个List的长度都会和Batch Size那一维复用起来。比如Pointwise的Batch Size=100,List长度是10的话,就只能用10个List。太长的List长度会导致Batch Size变小,这一点也要注意。
「【推荐阅读】」
推荐系统粗排之柔:双塔 to NN,Learning to Rank - 水哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/426679177
召回06:双塔模型——模型结构、训练方法_哔哩哔哩_bilibili,地址:https://www.bilibili.com/video/BV1YA4y1D75Q/?spm_id_from=333.999.0.0&vd_source=c5f6fbcc32cf4d400919b743bb49fcd4
https://github.com/wangshusen/RecommenderSystem/blob/main/Slides/02_Retrieval_06.pdf
4.4 Pointwise+Pairwise联合学习
Pointwise只关注对单个item打分的准确性,提高对目标的拟合程度,而没有考虑这种单点精度的建模方式与任意两个item之间的相关性排序的不一致性。其实就是Pointwise不能学习某两个item的相对顺序。Pairwise方法以序为优化目标,且Pairwise方法一般不依赖于特定的模型结构,我们可以通过双塔结构联合学习Pointwise loss和Pairwise loss,使模型同时学习到单点精度与两点偏序,兼顾保距和保序,从而提升模型的预测精度。
Pairwise loss一般使用BPR Loss,但BPR Loss没有考虑偏序间位置的偏离程度,比如<位置-1,位置-2>组成的pair对的区分度要小于<位置-1,位置-6>组成的pair对,因此可以考虑引入lambda weight来衡量不同pair的价值。其次,Pairwise loss更关心item间序的关系,对于打分的稳定性没有Pointwise loss好,因此在Pairwise学习的基础上加入Pointwise来约束打分使模型预测的打分更加稳定。
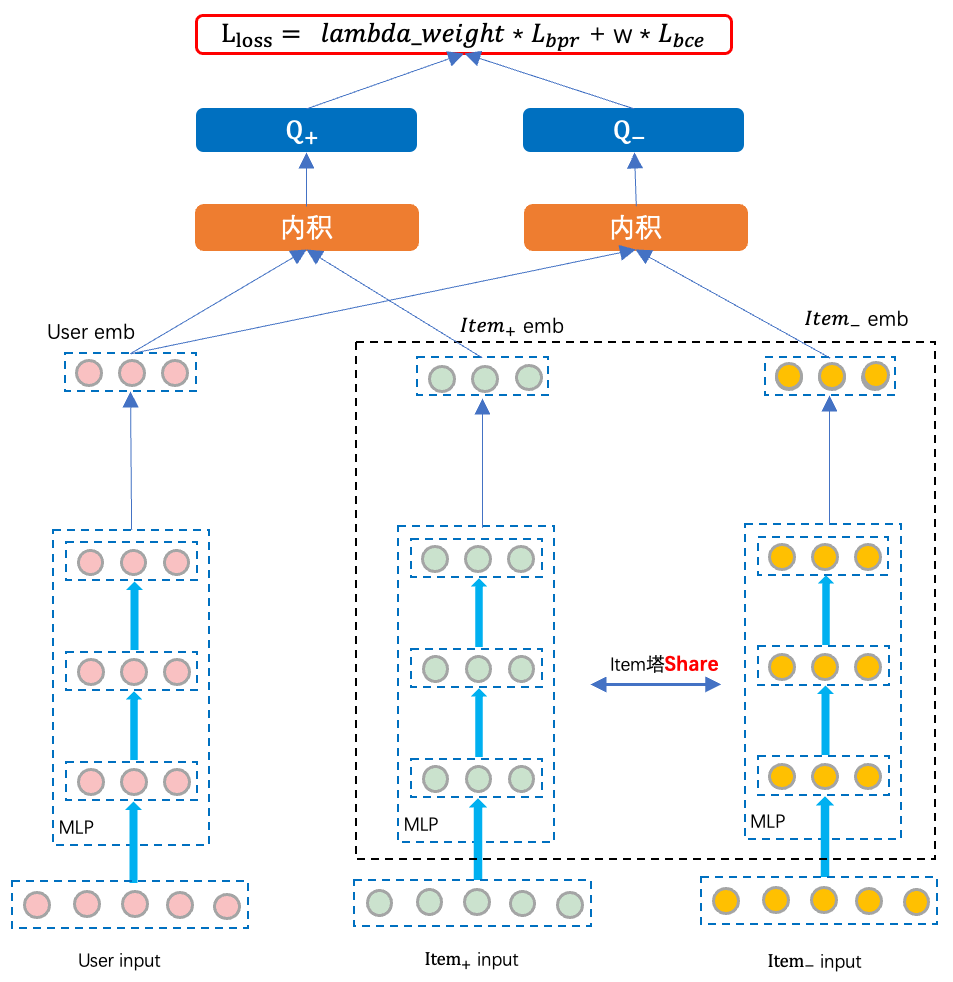
其中,,上文详细介绍过,这里就不再赘述了。就是BPR loss。是超参系数,用来控制两种loss之间的比重。为交叉熵损失函数。
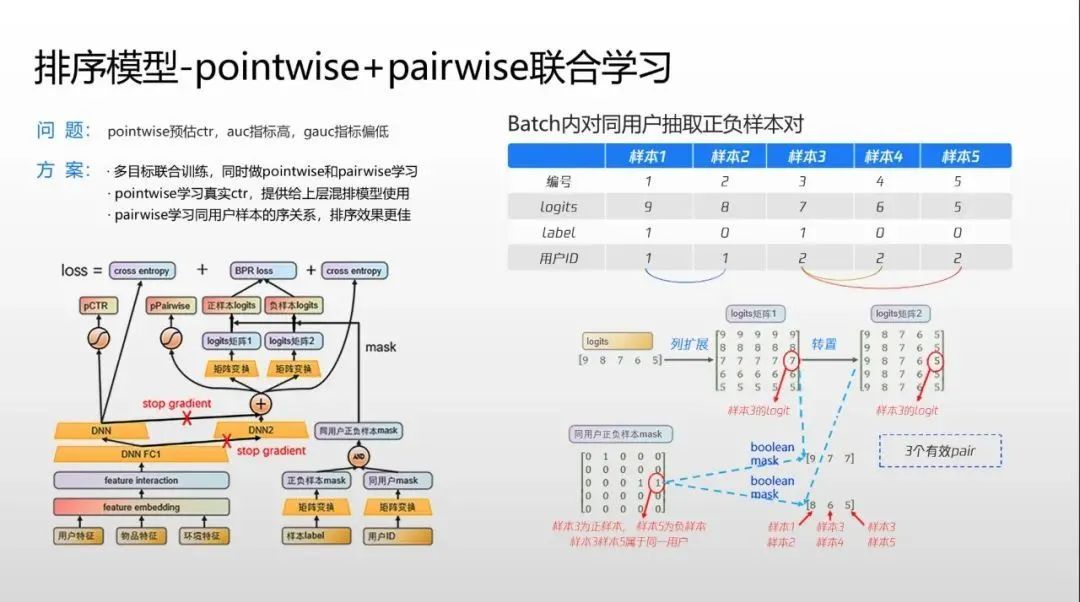
当然QQ浏览器团队在精排上还打造了特色的 pointwise+pairwise 联合学习。其中pointwise一般用来预估CTR做pCTR输出,但用户序列学习效果不佳,所以往往AUC计算较好,但GAUC偏低。而pairwise的一般排序比pointwise更好,但pairwise无法生成pCTR,亦即CTR用户值,但混排在上面的载控各层需要该值。如果pointwise、pairwise分别部署,两套模型需要两倍机器。为此团队提出改进,在输入时通过一些矩阵转制同时生成pointwise和pairwise样本,两者共享一些共同的输入特征、共享部分网络模型。上层pointwise和pairwise有各自独立的模型和计算,这样无需增加任何服务器成本就可以在一次样本流里同时输出两个结果,最后pointwise 输出的pCTR用在其他场景,而pairwise排序结果作为精排结果输出。
「【推荐阅读】」
Lei Y, Li W, Lu Z, et al. Alternating pointwise-pairwise learning for personalized item ranking[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 2017: 2155-2158.
Al与推荐技术在腾讯QQ浏览器的应用,https://mp.weixin.qq.com/s/EnMT4xVY3LRCyVqqNqr5WQ
「Reference」
万变不离其宗:用统一框架理解向量化召回 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/345378441
负样本为王:评Facebook的向量化召回算法 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/165064102
二手双塔召回串讲 - 新一的文章 - 知乎 https://zhuanlan.zhihu.com/p/506770389
pairwise建模入门--排序算法 - 淀海幽蓝的文章 - 知乎 https://zhuanlan.zhihu.com/p/318300682
机器学习在推荐系统的中使用(排序篇) - 王建周的文章 - 知乎 https://zhuanlan.zhihu.com/p/362371596
推荐系统中的排序学习,地址:https://lumingdong.cn/learning-to-rank-in-recommendation-system.html
推荐- Point wise、pairwise及list wise的比较 - 袁从德的文章 - 知乎 https://zhuanlan.zhihu.com/p/337478373
Learning to Rank: pointwise 、 pairwise 、 listwise - 一小撮人的文章 - 知乎 https://zhuanlan.zhihu.com/p/111636490
一文搞懂Approximate Softmax:从公式到代码 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/528862933
【PyTorch基础教程30】DSSM双塔模型、召回的3种训练方式_wx62cea850b9e28的技术博客_51CTO博客
推荐系统粗排之柔:双塔 to NN,Learning to Rank - 水哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/426679177
5. 基于多目标的用户分群双塔召回
5.1 算法侧建模时,为什么要考虑将用户分群?
我们一般建模推荐算法时,用到的样本都是不区分用户群体的,这会导致在推荐系统中,贡献训练样本多的用户群体的行为样本主导了模型的整个训练过程,训练出来的模型很容易按照样本多的这个群体的特点去给所有用户进行推荐。
在大多数推荐系统中,新浅和低活用户贡献样本一般较少,模型训练的绝大部分样本是高活用户贡献的,如果不对训练样本做特殊处理,直接用所有样本训练模型,模型推荐的方向会偏向于高活用户的喜好,使低活用户的体验不佳。
为了解决由于新浅用户和高活用户贡献样本数差异大导致模型对不同用户群体推荐有偏差的问题,我们需要将用户分群,对不同人群用户分开建模。
「问:如何将用户划分为不同人群呢?」
有经验的算法工程师,一般会通过用户的“有效观看session”长度或“用户画像”长度来将用户区分为低活人群、中活人群和高活人群。
通过“有效观看session”长度划分用户群一般手段为:
长度<=5为低活人群,5<长度<=100为中活人群,长度>=100为高活人群。
通过“用户画像”Tag个数划分用户群一般手段为:
个数<=3为低活人群,3<个数<=20为中活人群,个数>=20为高活人群。
当然“长度”和“个数”的具体数值范围,要通过业务数据的分析才能准确得到。
5.2 特征分群方法
特征分群就是通过特征的手段在样本中区分低活人群、中活人群和高活人群。具体做法就是在训练样本中加入一个“用户活跃度”特征,用该特征表示该用户的人群状态。当然“用户的活跃度”特征,既可以定义成Dense特征,又可以定义为稀疏的Sparse特征。如果是Dense特征的话,注意要做Min-max归一化等连续特征处理。如果是离散特征的话,一般通过one-hot的方法定义,比如,低活人群用表示,中活人群用表示,高活人群用表示。
这种方法的优势就是实现简单,但是缺点也很明显,就是低活人群样本较少,中高活人群样本较多,模型在整个训练过程中反向传播的梯度都由样本较多的中高活用户所主导,训练出来的模型对中高活用户比较友好,同样对于新用户推荐不准确。当划分的用户群体产生的样本差异较大时,此方法就没有显著效果了。
5.3 基于多目标的用户分群双塔召回
我们把上文提到的“多塔多目标召回模型”做一下改变,将多目标改为多个用户群体,即每一个用户群体就是一个目标,每一个目标学习对应群体的用户向量。模型离线训练的时候,高活人群的样本反向梯度更新所有专家、Gate1和对应的Tower1网络,低活人群的样本反向梯度更新所有专家、Gate3和对应的Tower3网络。这就是一个用户群体的一条样本,更新对应的任务Tower和Gate,并且更新和共享所有的专家及特征Embedding。这里特征Embedding和专家共享,可以实现不同用户群体的知识共享和不同群体间的信息迁移能力。Item侧,只有一个Item塔,产出Item的Embedding,所有群体用户共享一个Item任务塔。在线Serving的时候,根据用户的群体划分,过对应的网络前向计算,得到对应人群的user embedding。
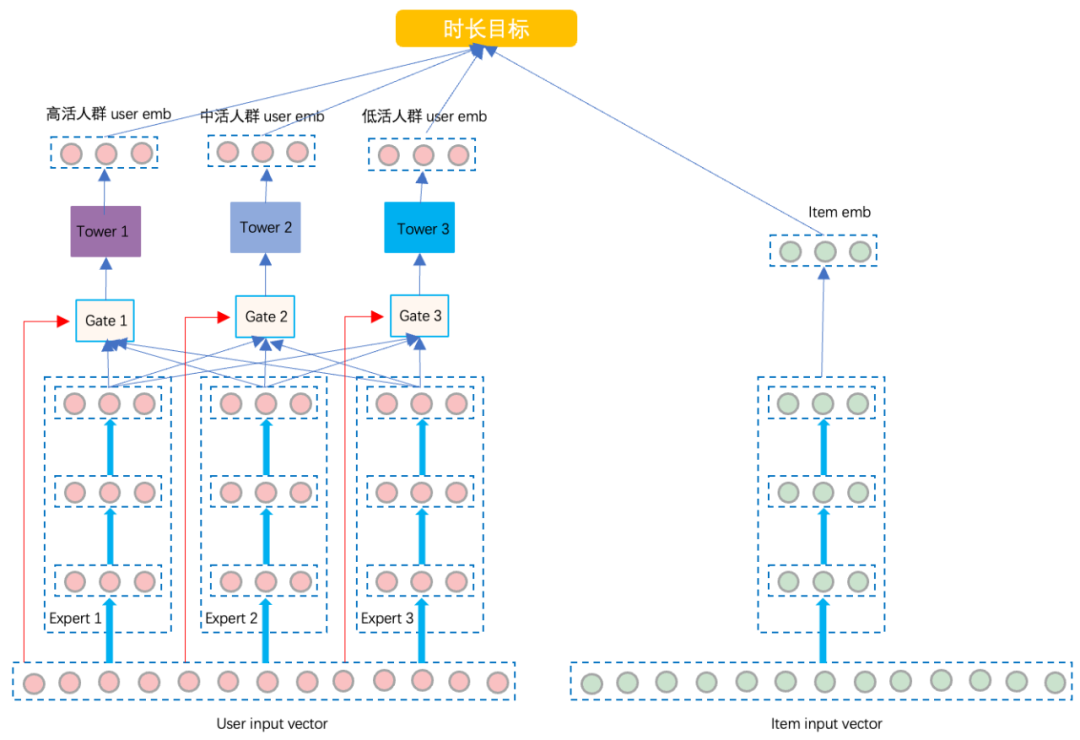
这种方法的优势是:特征Embedding Table表共享,可以很好的解决在底层特征表达的能力上由于低活人群样本较少,特征训练不充分的问题。由于多专家的网络结构能够处理更加复杂的数据分布,专家共享,可以实现不同用户群体的知识共享和信息迁移能力。不同的目标群体,有自己独有的任务Tower,来拟合自己群体独有的信息。这样的网络模型结构设计,不仅在共享方面照顾了低活人群样本较少,兴趣学习不充分的缺点,而且还对不同人群的差异,训练单独的Tower网络,以学习人群的差异化,同时也缓解了贡献训练样本多的高活用户群体的行为样本主导了模型的整个训练过程的问题。
5.4 百度分人群MMoE
多目标建模从最开始基础的shared-bottom的DNN建模发展到MMOE,最后采用分人群MMOE,将N个推荐系统目标建模出来,在真正实现的时候,低、中、高三种活跃度专家分别训练,联合决策防止高活人群样本主导整个模型,从而保证系统的准确性。
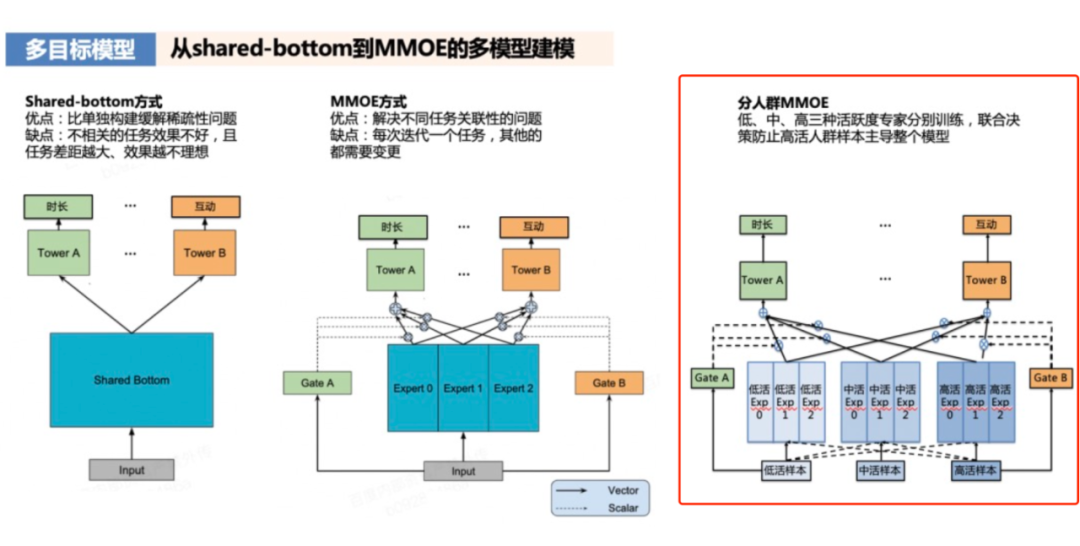
图来源于:https://mp.weixin.qq.com/s/D7LnGuT_Nm4-ftDcgLBb9w
「【推荐阅读】」
百度短视频推荐系统的目标设计 ,地址:https://mp.weixin.qq.com/s/D7LnGuT_Nm4-ftDcgLBb9w
6. 面向后链路的一致性建模
6.1 双塔召回模型蒸馏精排
(1)腾讯-召回蒸馏召回
这篇论文《Distillation based Multi-task Learning: A Candidate Generation Model for Improving Reading Duration》是我们隔壁团队的工作,算是我看过比较早在召回侧做蒸馏的方案。论文首先提出,如何在多任务学习的场景下建模阅读时长。为了在信息流场景下建模阅读时长,作者使用论文ESSM的方法,把阅读时长也建模为先预估点击率+再预估阅读时长两部分更有效。
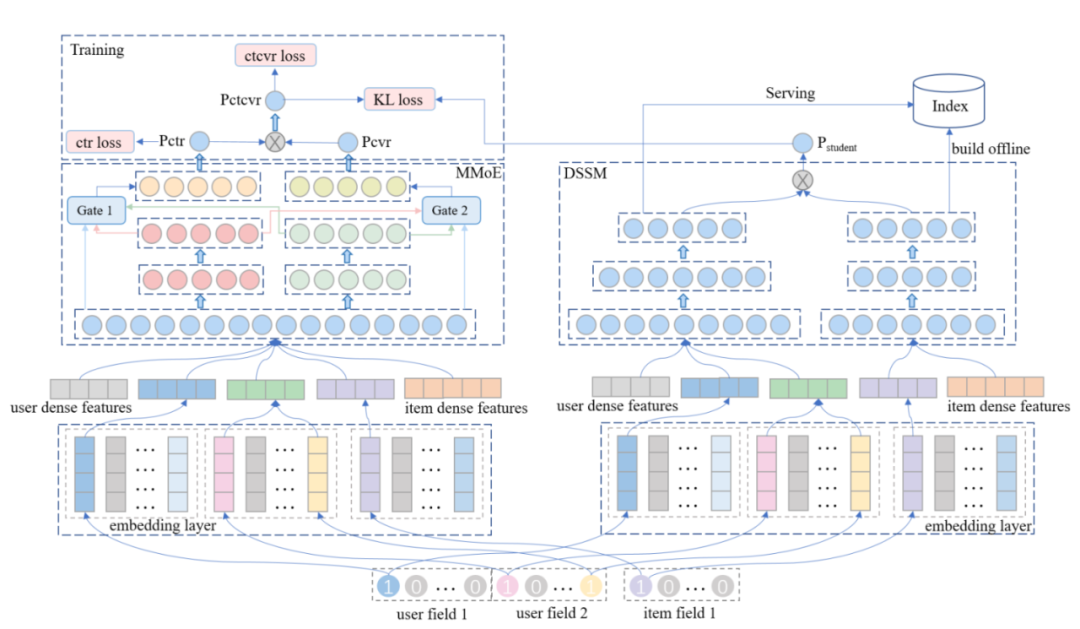
这里可以把Teacher模型也看成是一个召回模型,只不过这个召回模型用的是ESSM论文中提出的多目标排序模型。如果物品库中的item比较少或不考虑推荐系统的耗时,那我们完全可以用类似粗精排的打分方式做召回,只不过在实际的工业场景中,面对的是海量的商品库,以及极其严苛的耗时限制,这就要求我们把推荐系统做成召回、粗排、精排、重排等分漏斗的设计,且召回的神经网络模型一般都通过ANN方式做检索。
把Teacher模型看成复杂的多目标召回模型,那论文中提出的样本负采样就可以理解了,毕竟召回模型都是要负采样的。对于点击任务,正样本是被点击的样本,负样本是根据被点击概率从整个商品库中随机选择的。并且,Teacher模型和双塔Student模型,共用同一套训练样本。
Teacher模型的Label有两个:点击CTR和阅读时长CTCVR。Student模型只使用样本中的特征部分,不使用样本中的Label,因为双塔召回是建模ctr条件下的阅读时长,没有真实label可学,只能跟老师学,所以Student模型没有student loss只有蒸馏的KL loss。Student模型只学习Teacher模型预估的pCTCVR。
论文的结构让我觉得是一种召回蒸馏学习多目标融合公式的通用版,左边Teacher可以做各种目标及公式的融合,最后用双塔召回去拟合最终融合的结果。
总之,这篇论文Teacher是高精度召回,Student是蒸馏Teacher的高精度结果。本质就是复杂模型+多目标的能力,蒸馏到双塔召回上。
「Reference:」
Zhao Z, Fu Y, Liang H, et al. Distillation based Multi-task Learning: A Candidate Generation Model for Improving Reading Duration[J]. arXiv preprint arXiv:2102.07142, 2021.
双塔召回模型的前世今生(下篇) - iwtbs的文章 - 知乎 https://zhuanlan.zhihu.com/p/441597009
《Distillation based Multi-task Learning: A Candidate GenerationModel for Improving Reading Duration》,地址:https://blog.csdn.net/qq_xuanshuang/article/details/127173837
蒸馏技术在推荐模型中的应用 - iwtbs的文章 - 知乎 https://zhuanlan.zhihu.com/p/386584493
(2)召回精排一致性-召回蒸馏精排
推荐系统中精排模型决定了最终要展示给用户的物品列表,其结果最贴合用户的兴趣。召回模型能否用蒸馏的方法提高推荐链路中召回和精排的一致性呢?如果召回和精排能保持高度一致性,那这路召回在召回的评价指标(曝光占比、有效播放占比等)中应该能取得较好的收益。
如果是双塔粗排蒸馏精排,由于粗精排训练样本一致,我们可以做到粗精排联合训练与粗排蒸馏精排。但是召回蒸馏精排,有一个难点是:召回负采样的问题。召回的负样本面向的是全库的物品,精排的负样本是曝光未点击,召回直接用精排的样本训练,会带来样本选择偏差的问题。那么,有没有一种好的方法,即可以使用精排的样本,又做到召回的负采样呢?
比较直接的做法是“Batch Negative Sampling”,即在Batch内执行召回的负采样逻辑,以这种方式缓解精排样本产生的选择偏差问题。当然,具体的负采样逻辑就比较灵活了,可以是过滤掉精排的负样本直接在batch中的正样本中负采样,也可以保留原精排中的正负样本再在batch中的正样本中采样召回负样本,以此作为Hard Negative Sampling。
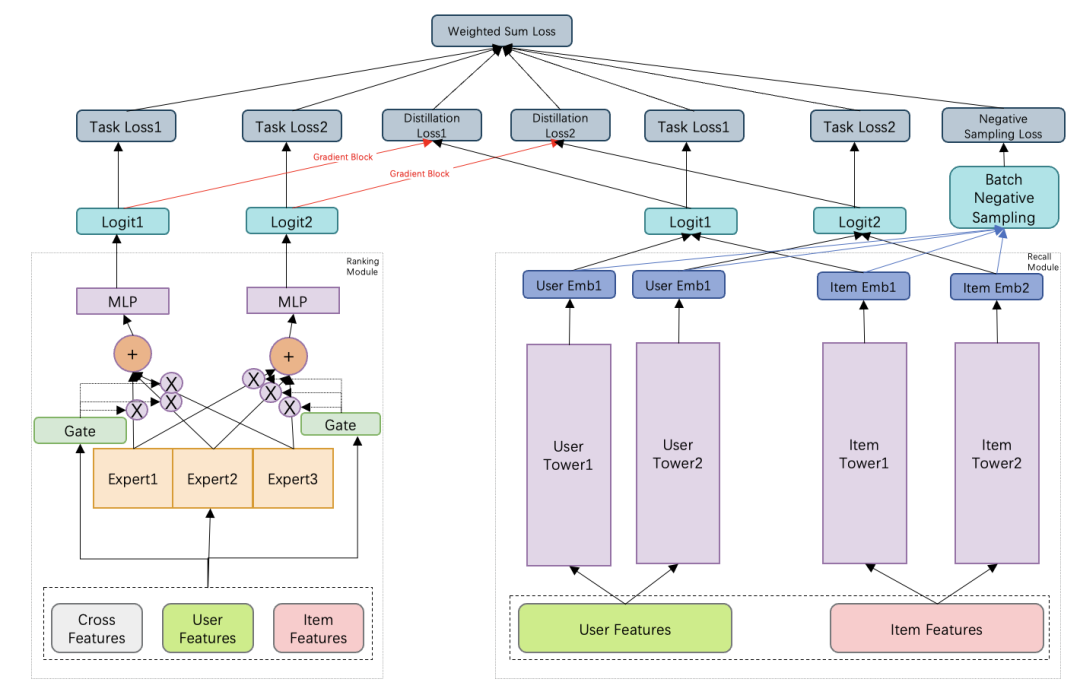
如果样本精排和召回都用到,就走召回蒸馏精排的目标打分,这样的样本,会参与召回和精排的训练。如果是负采样的样本,就没有蒸馏的逻辑了,负采样的样本只参与召回模型的训练。
「Reference:」
阿里广告技术最新突破:全链路联动-面向最终目标的全链路一致性建模 - 萧瑟的文章 - 知乎 https://zhuanlan.zhihu.com/p/413240790
(3)召回蒸馏精排多目标融合分
以上召回蒸馏精排方法存在两个问题:
精排往往存在秒滑率、跳出率等这样的负目标,召回得到的各个目标的user embedding和item embedding不能像精排打分一样可以融合各种形式的公式,尤其是存在负目标的时候。
精排的目标、打分公式及各个目标的超参随时可以变化,精排每变化一次,召回蒸馏精排就要做适配,保持召回、精排一致性。
如何一劳永逸的做到召回精排一致性?那当然是召回直接蒸馏精排多目标通过公式融合后的最终分数。模型结构如下:
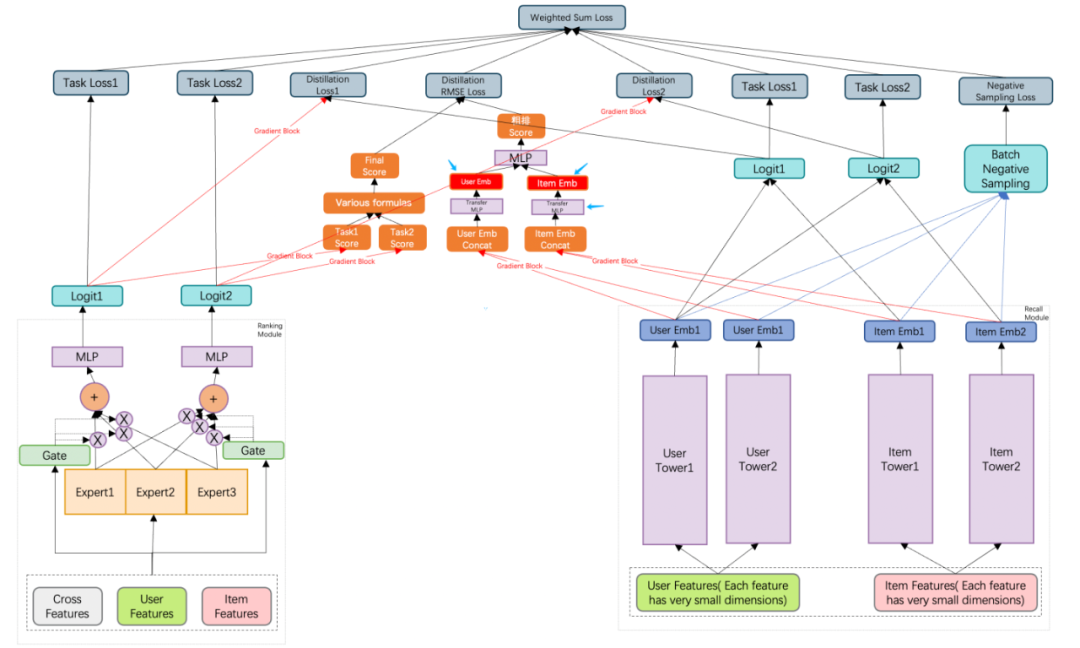
增加一个学习精排融合分的网络,该网络的学习目标是衡量精排融合分与粗排融合分的差距,用RMSE Loss。
解释Transfer MLP的作用:这里的思考是如何把User侧的多目标Embedding变成一个Embedding。直接将各个目标学到的user embedding拼接在一起,作为一个长的user embedding,输入到最上层MLP学习精排打分,这里可能存在拼接起来的embedding与最上层MLP参数不在一个空间学习,导致MLP期望的输入向量与拼接起来的embedding向量空间不一致问题,因此这里加入了Transfer MLP进行空间上的迁移。
最终,Transfer MLP输出的User/Item Emb作为最终线上的serving embedding。
这里可以认为最上层MLP是用来拟合精排的打分公式。
6.2 蒸馏Loss的设计
在推荐中使用召回知识蒸馏精排,召回模型不仅有和精排一样的任务数及一样的多任务Loss,还会为每个任务增加知识蒸馏的Loss。这些知识蒸馏的Loss可以把精排学到的知识迁移给召回,以希望召回模型能够学到精排模型的排序信息。知识蒸馏损失函数目前有两方面的工作,一是损失函数的形式选取,二是设计蒸馏Loss的权重。
(1)损失函数的形式
知识蒸馏损失函数的形式主要有交叉熵损失和MSE损失。
「MSE损失公式如下:」
这里直接使用精排网络最后一层的输出logits作为soft targets,需要最小化的目标函数是教师精排网络和学生召回网络的logits之间的平方差。
「交叉熵损失函数如下:」
其中,是温度系数,它用来平滑教师模型的输出概率。由于推荐中,排序的Label是或,结合交叉熵损失函数来看,one-hot标签会导致过拟合,one-hot标签监督性太强,因为其增大预测正确标签的概率,而不关注减少预测错误标签的概率。如何克服ont-hot标签的缺点,就是对one-hot标签进行平滑处理。也就是设定一个平滑参数(即温度系数),让标签的每个位置都有值,正好老师网络的输出概率分布就是一个soft label。温度大于1时,会对网络的输出起到一个平滑作用,当标签越趋于平滑,其分布的熵越大(包含的信息量就越大),负标签所携带的信息会被相对地放大。相对传统训练过程来说,模型训练会更加关注负标签。这样就会使得网络不只学习正确标签的信息,也会学习负标签的信息。是教师精排模型的输出概率,是学生召回模型的输出概率,都是经过Sigmoid之后的概率。
「Reference:」
深度学习中的知识蒸馏技术(上),地址:https://mp.weixin.qq.com/s/E7-MF18Y-UeKx694kGFHzA
知识蒸馏 - Github届的卡卡西的文章 - 知乎 https://zhuanlan.zhihu.com/p/363376356
(2)蒸馏Loss的权重
召回蒸馏精排,召回侧的损失函数如下:
学生模型具体损失如下:
其中,是数据的label,是学生模型的logit值,是item在教师模型中的logit值。是学生模型在有标签数据下的损失函数。而是蒸馏损失函数,计算教师模型和学生模型针对item预估差异的损失函数。
然后关键就来了,如何计算呢。具体计算损失如下:
其中是一个batch中每个item的权重。这个权重也是比较重要的,一般有两种直接计算权重的方法,第一种是,代表item在教师模型中排序的位置,位置越靠前的影响即越大。还有一种就是,为batch size的大小,这样所有item的权重都一样。但是这两种效果都不是很好,论文《Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System》提出了以下几种计算权重的方法。
「1) Weighting by Position Importance 即根据排序的位置来决定权重」
, 权重和位置成反比。
这个是论文《Improving Pairwise Learning for Item Recommendation from Implicit Feedback》提出一种计算权重的方法。
这篇文章提出用于加权位置重要性的参数化几何分布。 and 。 是超参数。这种蒸馏损失函数的权重方式只考虑样本在教师模型中的排序,教师模型排序靠前的样本更重要,在知识蒸馏时需要分配更大的权重。
「2)Weighting by Ranking Discrepancy」
根据位置得到的权重是静态的,在训练中固定不变。这个方法提出一种动态权重,可以随着模型训练来更新。在训练的一个batch的Top k个items中,教师模型对其排序的位置我们是知道的,是在所有无标签items中的Top K,但是学生模型仅仅知道这Top K items与users的相似分数而不知其在所有items中的排序位置。为了得到学生模型预测其在所有batch中的排序,采用采样估计来进行计算,具体算法如下,有兴趣的可以去看看原文。

在得到学生估计文档的排序后,权重计算如下,其中是在教师模型中的排序位置。这是一个动态权重,当学生预测的item位置越接近教师模型,就认为该item经过了良好的学习排序,因此损失接近。针对每个item,其权重都是不同的。
就是计算教师模型与学生模型排序的差异。这种权重设置方法考虑了样本在教师和学生模型中的排序差异,两个模型中排序差异比较大的样本才需要重点关注。
「3)混合权重,将上边两种权重混合应用」
,论文实验证明,混合权重是效果最好的。
「【推荐阅读】」
Tang J, Wang K. Ranking distillation: Learning compact ranking models with high performance for recommender system[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 2289-2298.
Ranking Distillation 知识蒸馏应用在推荐系统中分享 - 积极废人的文章 - 知乎 https://zhuanlan.zhihu.com/p/362945179
6.3 学习后链路的序
(1)精排结果列表蒸馏
这个方案是美团在粗排上对样本的优化,我认为放在召回上仍然是一个比较好的优化思路。这里把美团应用到粗排的方案列出来,大家根据自己的业务适配到召回上即可。
粗排作为精排的前置模块,它的目标是初步筛选出质量比较好的候选集合进入精排,从训练样本选取来看,除了常规的用户发生行为(点击、下单、支付)的 item 作为正样本,曝光未发生行为的 item 作为负样本外,还可以引入一些通过精排模型排序结果构造的正负样本,这样既能一定程度缓解粗排模型的样本选择偏置,也能将精排的排序能力迁移到粗排。下面会介绍在美团搜索场景下,使用精排排序结果蒸馏粗排模型的实践经验。
「策略1:」 在用户反馈的正负样本基础上,随机选取少量精排排序靠后的未曝光样本作为粗排负样本的补充,如下图所示。该项改动离线 Recall@150+5PP,线上 CTR+0.1%。

图:补充排序结果靠后负例
「策略2:」 直接在精排排序后的集合里面进行随机采样得到训练样本,精排排序的位置作为 label 构造 pair 对进行训练,如下图所示。离线效果相比策略1 Recall@150 +2PP,线上 CTR +0.06%。
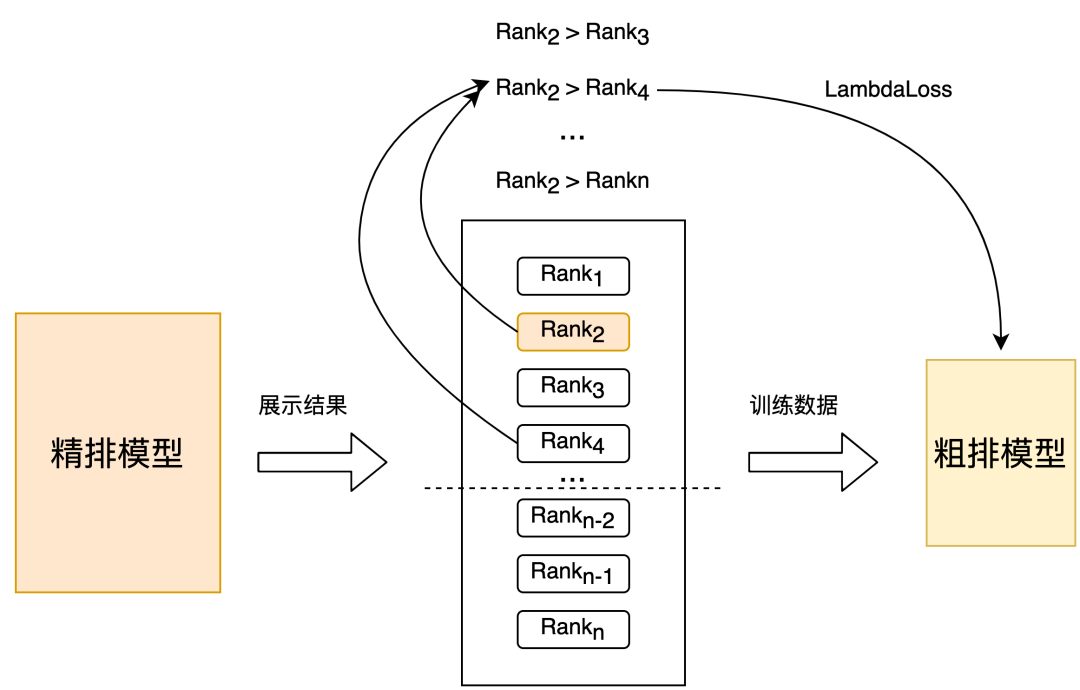
图:排序靠前靠后构成 pair 对样本
「策略3:」 基于策略2的样本集选取,采用对精排排序位置进行分档构造 label,然后根据分档label构造pair对进行训练。离线效果相比策略2 Recall@150 +3PP,线上CTR +0.1%。
(2)以学习后链路的序为目标的端到端召回技术LDM
首先引入同一次请求内,精排阶段的参竞日志,在构造样本pair的时候把展现样本做为正样本,参竞未展现样本作为负样本,让模型学习将展现集合排在最前面,通过交叉熵loss进行学习。
这里仍然存在SSB问题,为了保证模型对简单样本的区分能力,同样引入了随机负采样loss,以展现作为正样本,batch内随机采的作为负样本。同样额外构建了另外一个双塔网络,和原双塔网络前几层参数共享,新网络以交叉熵loss的方式进行学习。
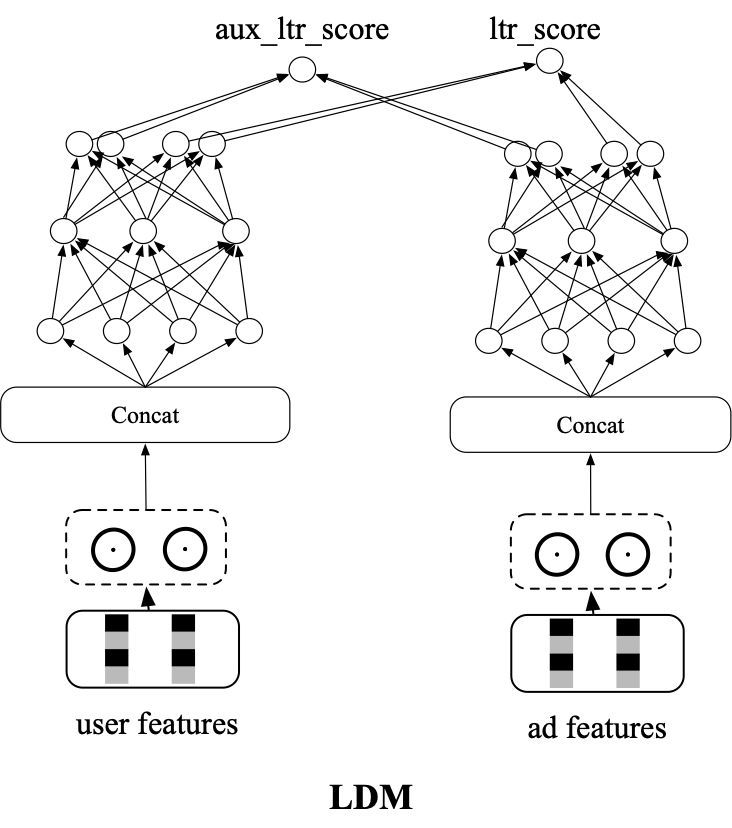
图来源:阿里广告技术最新突破:全链路联动-面向最终目标的全链路一致性建模 - 萧瑟的文章 - 知乎https://zhuanlan.zhihu.com/p/413240790
后面进一步尝试了,将同一个session内的样本,按最终系统目标排序后,进行分段,段间组pair并通过pairwise loss进行学习,但是没有取得进一步的效果提升。推测原因是因为召回阶段的精度需求没有那么高。
召回LDM技术有如下优点:
通过端到端LTR的方式隐式地学习了后链路多目标打分和调价模型的信息,兼顾了平台,广告主及用户诉求。
后链路升级后,通过精排参竞日志样本回流即可实现自行升级,维护成本较低。
线上效果:CTR+3% , RPM+4%。
「【推荐阅读】」
美团搜索粗排优化的探索与实践,地址:https://mp.weixin.qq.com/s/u3sw_PatpwkFC0AtkssmPA
阿里广告技术最新突破:全链路联动-面向最终目标的全链路一致性建模 - 萧瑟的文章 - 知乎 https://zhuanlan.zhihu.com/p/413240790
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









