






#!pip install pandas
#pip install --upgrade pandas
import pandas as pd
from sklearn.tree import DecisionTreeClassifier#D为S库中的一个分类器,基于决策树算法实现
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as pltdata = pd.read_csv("taitanic_data.csv",index_col = 0)
# 头信息,部分数据信息
data.head()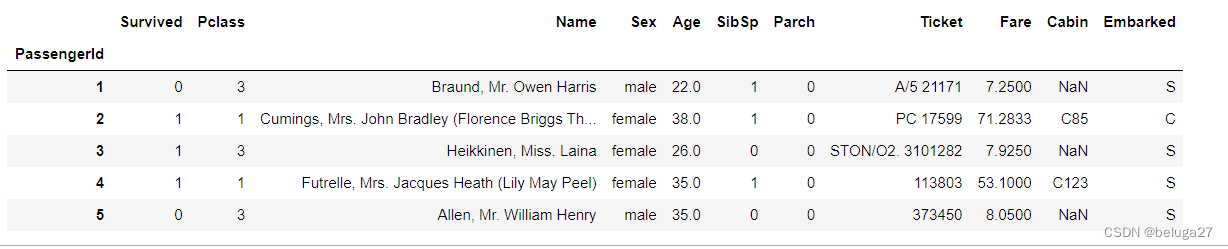
# 信息汇总
data.info()
# 删除缺失值过多的列 inplace=True覆盖原表; axis=1 删除列
data.drop(["Cabin"],inplace=True,axis=1)
# 删除和观察判断来说和预测的y没有关系的列
data.drop(["Name","Ticket"],inplace=True,axis=1)
# 处理缺失值,填充均值
data["Age"] = data["Age"].fillna(data["Age"].mean())
# 删除含有缺失值的行
data = data.dropna()
data.info()
#将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
#性别转换,astype可以将文本类转换为数字,将二分类特征转换为0、1
data["Sex"] = (data["Sex"]== "male").astype("int")
data.head()
X = data.iloc[:,data.columns != "Survived"]
X[:10]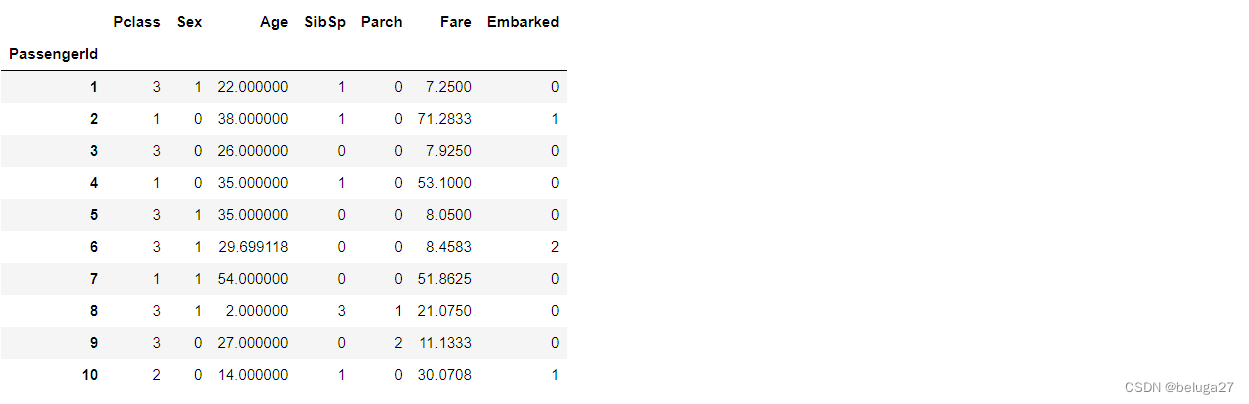
# iloc函数:通过行号来取行数据
y = data.iloc[:,data.columns == "Survived"]
y[:10] 
from sklearn.model_selection import train_test_split
#划分训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#修正测试集和训练集的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
#查看分好的训练集和测试集
Xtrain.head()
Xtest.head()
# 创建实例
clf = DecisionTreeClassifier(random_state=25)
# 训练模型
clf = clf.fit(Xtrain, Ytrain)
#模型评分
score_ = clf.score(Xtest, Ytest)
score_![]()
# 10折交叉验证
score = cross_val_score(clf,X,y,cv=10).mean()
score![]()
# 选择决策树的深度
tr = []
te = []
#遍历10次,每次修改树的深度
# 在每次分支时,不用全部特征,而是随机选取一部分特征,从中选取不纯度相关指标最优的作为分支用的结点 random_state
for i in range(10):
clf = DecisionTreeClassifier(random_state=20
,max_depth=i+1
,criterion="entropy"
)
clf = clf.fit(X, y)
#
score_tr = clf.score(Xtrain,Ytrain)
#10折交叉验证
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(tr)
print(max(tr))
print(max(te))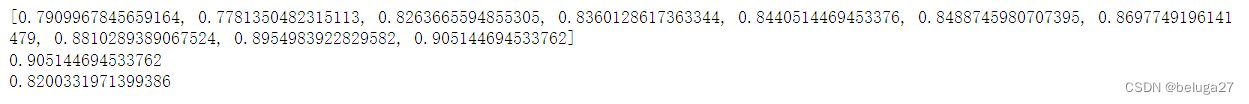
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
# 坐标轴的单位
plt.xticks(range(1,11))
plt.legend()
plt.show()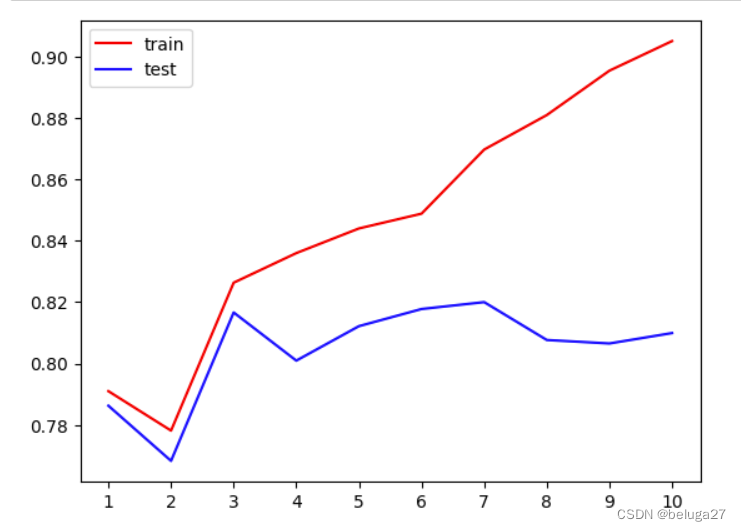
# 网格搜索,耗时操作
import numpy as np
# 0到0.5之间 20个顺序的随机数
gini_thresholds = np.linspace(0,0.5,20)
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
# 分类器
clf = DecisionTreeClassifier(random_state=25)
# 网格搜索
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
# 最优参数
GS.best_params_
#这段代码的作用是使用网格搜索(GridSearchCV)方法来
#找到决策树分类器(DecisionTreeClassifier)在指定参数范围内的最优参数组合

GS.best_score_![]()
逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 划分特征和标签
X = data[["Age", "Sex", "Fare", "Pclass"]].values
y = data["Survived"]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
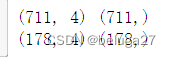
# 创建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 输出模型在测试集上的准确率
accuracy = model.score(X_test, y_test)
print("Accuracy:", accuracy)
![]()
支持向量机
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 划分特征和标签
X = data[["Pclass", "Sex", "Age", "Fare"]]
y = data["Survived"]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 SVM 分类器对象
svm = SVC(kernel='linear', C=1, random_state=42)
# 拟合数据集
svm.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
![]()
随机森林
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 划分特征和标签
X = data[['Pclass', 'Sex', 'Age', 'Fare']]
y = data['Survived']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器对象
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 拟合数据集
rf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = rf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
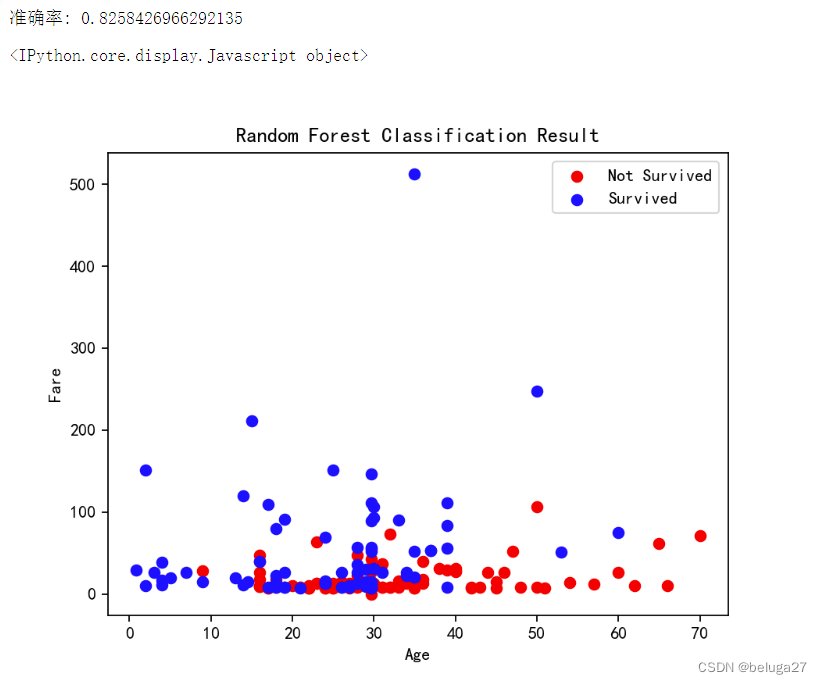
print("准确率:", accuracy)
# 可视化分类结果
x1 = X_test[y_pred == 0]['Age']
y1 = X_test[y_pred == 0]['Fare']
x2 = X_test[y_pred == 1]['Age']
y2 = X_test[y_pred == 1]['Fare']
plt.scatter(x1, y1, c='red', label='Not Survived')
plt.scatter(x2, y2, c='blue', label='Survived')
plt.xlabel('Age')
plt.ylabel('Fare')
plt.legend()
plt.title('Random Forest Classification Result')
plt.show()
KNN
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 划分特征和标签
X = data[["Pclass", "Sex", "Age", "Fare"]]
y = data["Survived"]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN分类器对象
knn = KNeighborsClassifier(n_neighbors=5)
# 拟合数据集
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
![]()
















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











