







Pi-GAN
2022,02,11 lemon
项目地址:https://marcoamonteiro.github.io/pi-GAN-website/
摘要
本文首先提出了目前3D视觉领域已有的两大问题:
- 没有底层的3D表示,或者依赖于“视图不一致”的表示,因此合成的图片在各个视角上不一致;
- 网络结构不够好,得到的图片质量不高。
因此,作者提出了周期性隐式生成的对抗性网络*(Periodic Implicit Generative Adversarial Networks)*,简称为pi-GAN. pi-GAN利用具有周期激活函数和体积渲染的神经表示,将场景表示为与视图一致的辐射场,能够得到SOTA的效果。
网络结构
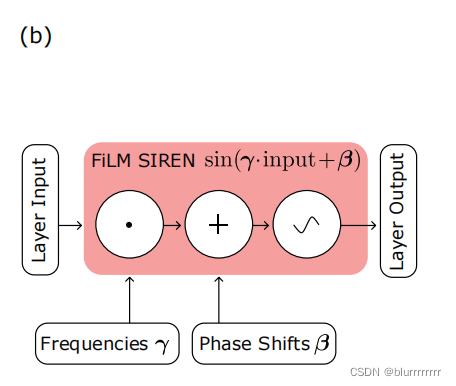
3.1 SIREN周期激活函数
同Relu,tanh,softplus等类似,SIREN也是一个激活函数,可表示为:

即权重矩阵W与X相乘,加上偏置B,再进行sin计算。SIREN的一个特性就在于,sin函数求导后是cos,而cos函数可以看作是sin函数的相移(Π/2)。因此sin函数的导数继承了sin函数的特性,使其能够监督复杂信号下的任意一个sin导数。
而本文的表征为:
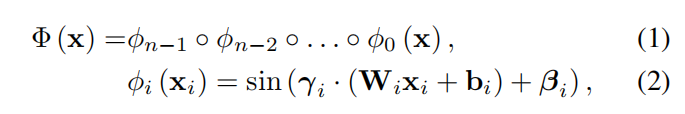
相较于基础的SIREN函数,还使用了一种名叫FiLM(Feature-wise Linear Modulation)的条件网络层。简单来说,FiLM是一个对输入同时采取乘法和加法操作的调制层,公式表示为:
F
i
,
c
=
γ
i
,
c
∗
F
i
,
c
+
β
i
,
c
F_{i,c} = \gamma_{i,c}*F_{i,c}+\beta_{i,c}
Fi,c=γi,c∗Fi,c+βi,c
其中,
γ
\gamma
γ和
β
\beta
β都是由FiLM generator算出的,其流程如下:
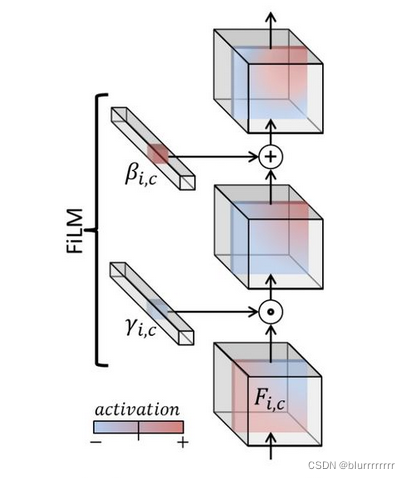
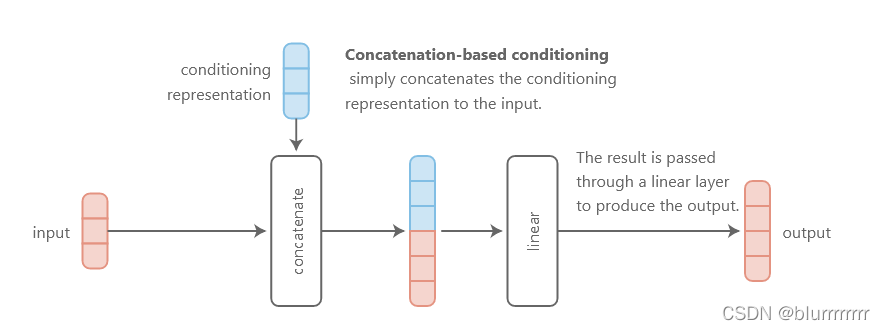
对于加法交互而言,在不太强烈依赖于两个输入的联合值的应用场景,如特征聚合或特征检测(即,检查两个输入中是否存在特征),加性交互更为自然。而对于乘法交互,它们有助于学习输入之间的关系,因为这些交互自然会识别“匹配”:将符号一致的元素相乘会产生比不一致的元素相乘更大的值。使用点积来确定两个向量的相似程度也是这个原理。相较于传统只含有加法运算的concatenation-based conditioning(见下图),FiLM在此处的效果更好。
因此,最后的表征(公式(1)(2))可以表示为:
此处假设读者已经了解了隐式神经辐射场的基本原理(反之可以去看看GRAF那篇论文),输入位置向量 x ( x , y , z ) x(x,y,z) x(x,y,z)和视角向量 d d d,就可以得到体密度 σ ( x ) : R 3 → R \sigma(x):\mathbb{R}^3\rightarrow \mathbb{R} σ(x):R3→R和颜色 r g b = c ( x , d ) : R 5 → R 3 rgb=c(x,d):\mathbb{R}^5\rightarrow \mathbb{R}^3 rgb=c(x,d):R5→R3,公式为:
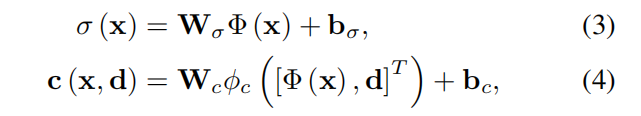
W σ / c W_{\sigma/c} Wσ/c是额外权重, b σ / c b_{\sigma/c} bσ/c是偏差参数。
整体的网络架构为:
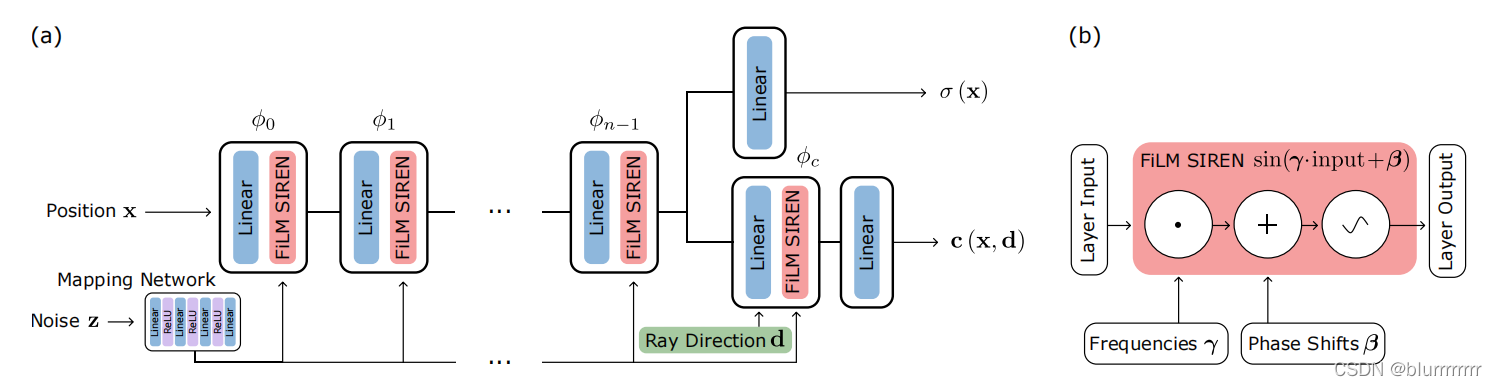
3.2 神经渲染
本文使用神经体积渲染来渲染一个来自任意相机姿态 ξ \xi ξ的神经辐射场。为此,采用“针孔相机模型”和从相机原点 O O O的投射射线来计算沿每条射线通过体积的积分。在每个样本中,生成器预测了体积密度 σ \sigma σ和颜色 c c c,然后利用体积渲染方程计算相机射线上的颜色(其中 t n t_n tn和 t f t_f tf分别是近远端点),公式为:

这种渲染方式和GRAF相同。
3.3 判别器
最开始,生成器在低分辨率的条件下进行大批量训练,并专注于生产粗糙的形状。随着训练的进行,我们提高了图像的分辨率,并在鉴别器中添加了新的层,以处理更高的分辨率和区分细节。对于大多数实验,我们从32×32的图像开始训练,在训练期间将分辨率提高两次,达到128×128。在实践中,我们发现这种渐进的增长策略允许在训练开始时进行更大的批处理规模,这有助于稳定和加速训练。最终的结果通过采样512×512像素来呈现。与ProgressiveGAN不同,我们的生成器架构没有增长;相反,我们通过从相同的隐式表示中更密集地采样射线来提高生成器的分辨率。
3.4 训练细节
略
实验效果
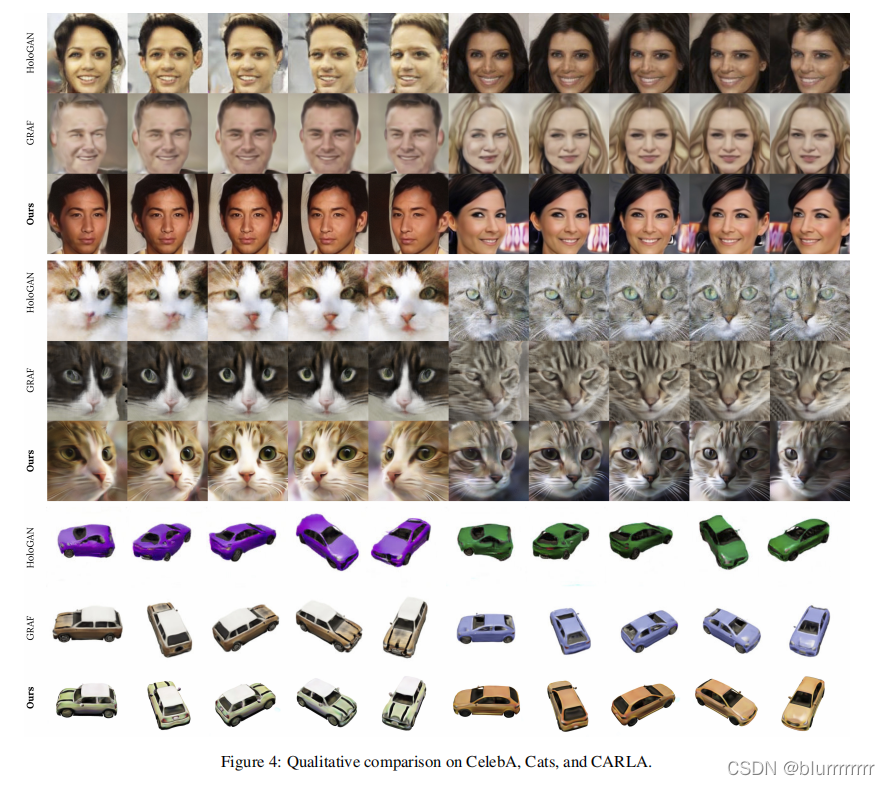
可以看到和其他一些生成网络相比,piGAN的生成效果不错。

当然,网络中也存在一些瑕疵,如上图中展示的:可能生成具有翻转部分的对象。
总结
总的来说,本文和GRAF的架构较为相似,但相较于GRAF效果有较好的提升。
本文中的trick主要体现在:
- 使用了SIREN作为激活函数,得到了很好的效果;
- 使用了FiLM作为条件网络层和逐步增长的判别器,得到了很好的效果;















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









