






前言
先前聊到强化学习的部分理论以及其简单的DEMO,那么我们不能只是空中楼阁,现在应该考虑如何将其投入物理环境中,以便能够sim2real。下面就来介绍一下Nivdia推出的Isaac gym–一种能够并行训练的RL环境。
Isaac Gym
之所以选择Isaac Gym的原因是因为其高效的训练速度,由于其能够仅使用GPU就能进行模拟和网络训练,通过这种并行训练的技术,能够在短时间内快速采集大量的数据,以便于后续进行训练。
我的硬件设备信息如下
CPU: i5-12400f
GPU: RTX-2080Ti
具体的安装环境教程可以参考:
https://blog.csdn.net/m0_37802038/article/details/134629194
https://zhuanlan.zhihu.com/p/685981407
在安装好了环境以后我们可以来看看一些简单的操作,具体详细的API使用可以参考
/home/cc/isaacgym/docs/index.html
我们可以在命令行窗口中输入
cd /home/cc/isaacgym/IsaacGymEnvs
python train.py task=BallBlance
运行后的结果见下图,可以看到训练初期,有很多小球都会从盘子上掉落下来
![![[Peek 2024-04-27 15-49.gif]]](https://img-blog.csdnimg.cn/direct/3fe5293d908d4e30ae4dc0bf13d1329a.png)
训练了250个回合之后,我们可以在home/cc/isaacgym/IsaacGymEnvs/isaacgymenvs/runs/BallBalance_27-15-31-40/nn中找到对应的模型权重文件,可以看到目录下有4个文件
![![[1.png]]](https://img-blog.csdnimg.cn/direct/c1c94c2ddbb6410a9e8604ca4b3764f8.png)
前面几个文件代表在第几个回合结束后生成一个checkpoint,我们接下来就来测试一下训练后的效果如何,在命令行中输入
python train.py task=BallBalance checkpoint=runs/BallBalance_27-15-31-40/nn/BallBalance.pth test=True
![[Peek 2024-04-27 15-47.gif]]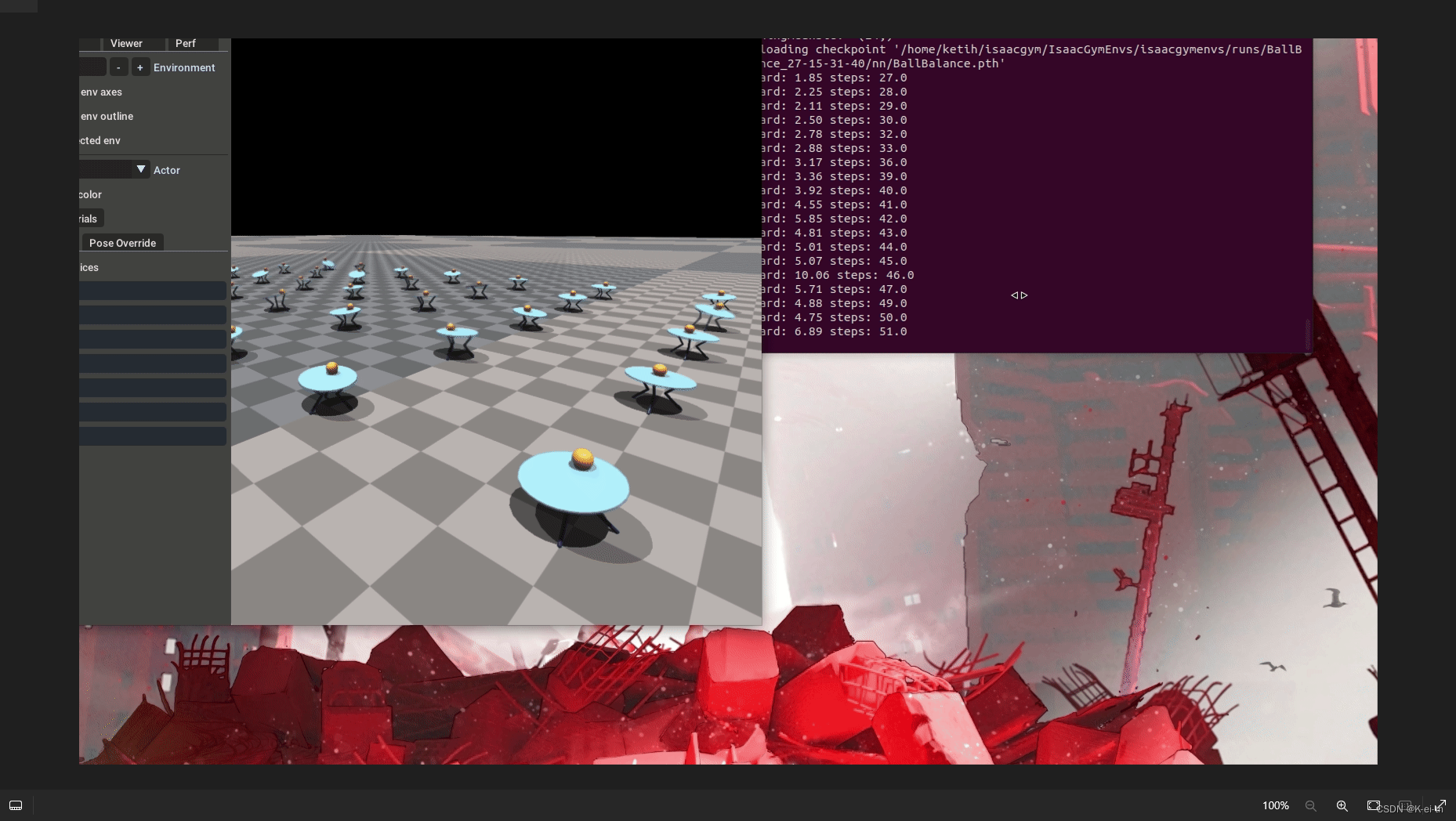
可以看到小球不再落下,而且也不会发生‘done‘,这说明模型已经收敛了,最值得兴奋的一点是–这仅仅用了5min不到的时间!
这个小DEMO的状态空间和动作空间的具体信息如下:
# Observations:
# 0:3 - activated DOF positions
# 3:6 - activated DOF velocities
# 6:9 - ball position
# 9:12 - ball linear velocity
# 12:15 - sensor force (same for each sensor)
# 15:18 - sensor torque 1
# 18:21 - sensor torque 2
# 21:24 - sensor torque 3
self.cfg["env"]["numObservations"] = 24
# Actions: target velocities for the 3 actuated DOFs
self.cfg["env"]["numActions"] = 3
其物理环境较为简单,代码如下:
def create_sim(self):
self.dt = self.sim_params.dt
self.sim_params.up_axis = gymapi.UP_AXIS_Z
self.sim_params.gravity.x = 0
self.sim_params.gravity.y = 0
self.sim_params.gravity.z = -9.81
self.sim = super().create_sim(self.device_id, self.graphics_device_id, self.physics_engine, self.sim_params)
self._create_balance_bot_asset()
self._create_ground_plane()
self._create_envs(self.num_envs, self.cfg["env"]['envSpacing'], int(np.sqrt(self.num_envs)))
相关参数
这里记录一下调用API过程中的相关参数,具体可以参考这篇文章,我在这里复制过来仅仅为了记录,文章链接为:
https://www.zhihu.com/people/yuewanggg
关于train.py相关的参数:
task=:指定要学习的任务train=:指定用于学习的神经网络模型和参数等设置的文件。可指定的文件位于IsaacGymEnvs/isaacgymenvs/cfg/中。以AllegroHand为例,存在trainAllegroHandPPO.yaml和AllegroHandLSTMPPO.yaml两个文件,这两个文件的明显区别是使用的神经网络模型不同。num_envs=:并行执行模拟的环境数量。此处的环境指的是强化学习中的环境(Environment)。增加环境数量可以提高学习效率和缩短学习时间。但增加过多可能会导致GPU内存不足错误。默认值在各任务的yaml文件中指定。
一些config参数:
seed=:设置用于控制学习中随机性的值(随机化的目标:代理的初始位置和姿态等)。设置值可以保证学习的可重复性[1]。默认值设置为seed=42。关于可重复性的更多详细信息,请参考IsaacGymEnvs/docs/reproducibility.md。sim_device=: 指定用于模拟物理的设备。 如果你使用GPU则设置cuda:0。 假设它是一个CPU则设置为cpu 。 默认为 (GPU) 即 sim_device=cuda:0rl_device=:指定用于学习的设备。默认为 (GPU)rl_device=cuda:0graphics_device_id=:指定用于绘制模拟的 Vulkan 图形设备 ID。 默认值是graphics_device_id=0。 基本上,默认设置没有问题,但如果您使用多个 GPU 或者想要检查 ID,可以通过运行 vulkaninfo来检查每个 ID 可以使用的 GPU。
尾言
至此,我们就大致了解了Isaac Gym的简单使用,接下来我将继续总结该环境的一些使用方法,文章内引用的部分侵删。















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









