



HunyuanVideo-I2V是腾讯混元系列模型中一个新型的图像到视频转换模型。用户只需要提供一张图片,简要描述要生成的视频内容,例如动作描述,镜头位置等等,HunyuanVideo-I2V就可以让图片动起来,生成高清连贯的视频,最高支持720P 5s。
昇思MindSpore团队现已完成对HunyuanVideo-I2V的适配,并将其开源至MindSpore ONE仓库,本文将要给大家详细介绍,如何基于昇思MindSpore和Atlas 800T A2,完整实现HunyuanVideo-I2V从图像到视频生成的部署流程。
-
MindSpore ONE开源代码仓链接:https://github.com/mindspore-lab/mindone/tree/master/examples/hunyuanvideo-i2v
-
魔乐社区代码仓链接:https://modelers.cn/models/MindSpore-Lab/hyvideo
模型介绍
HunyuanVideo-I2V和HunyuanVideo的模型结构相似,都采取了双文本编码器(Llava和CLIP)和单双流DiT Block,以实现对文本和图像多模态信息的融合。HunyuanVideo的模型结构如下图所示:
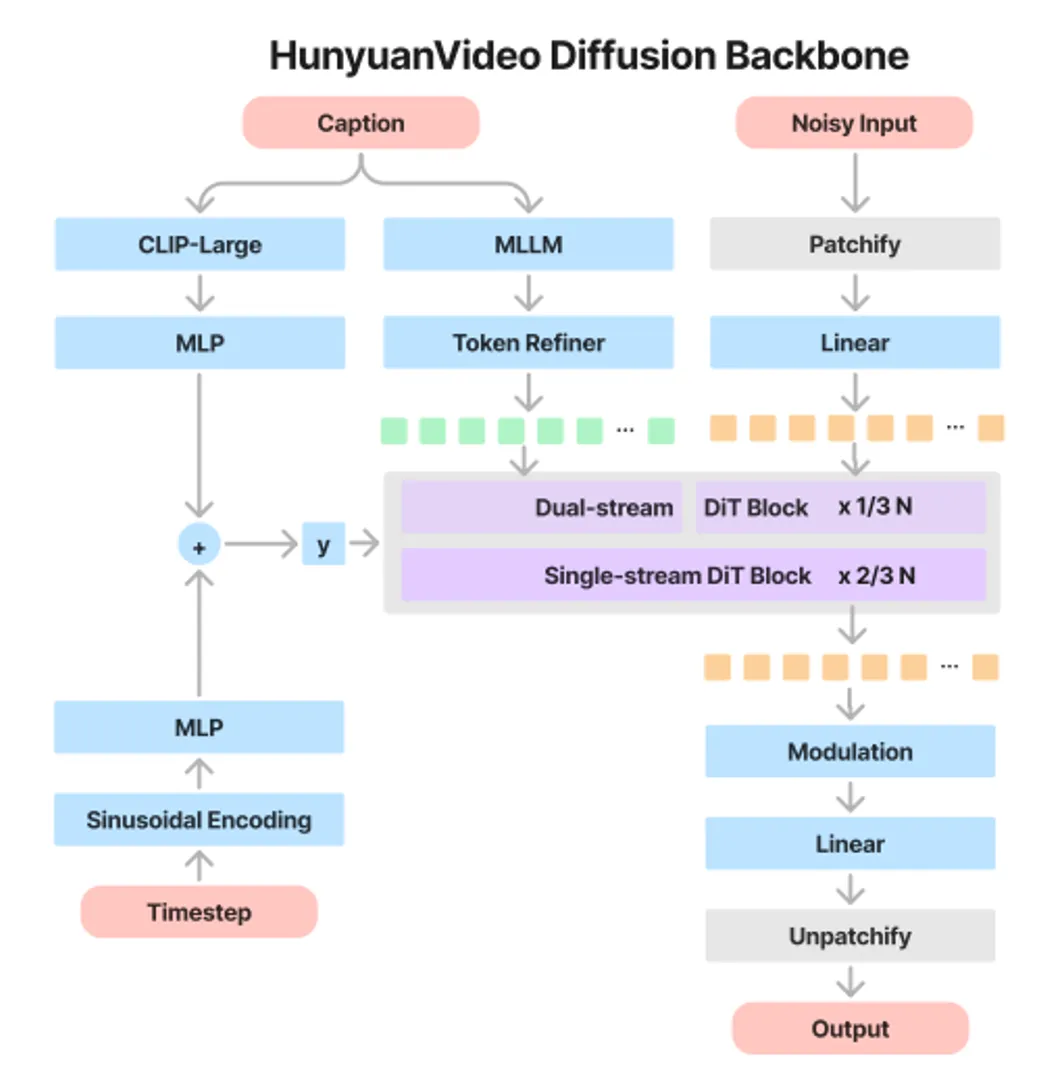
HunyuanVideo-I2V的总blocks数量是60,其中单流block数量为40, 双流block数量为20,模型的参数量更是达到了130亿。因此,使用HunyuanVideo-I2V生成720P视频的峰值NPU内存比较高,达到了62GB。推荐使用昇腾Atlas 800T A2机器(64GB),以获得更好的性能。
HunyuanVideo-I2V在HunyuanVideo (T2V)的基础上,将参考图像的潜在特征和高斯噪声进行拼接和融合,作为DiT模型的输入,在每一步去噪的前后进行首帧图像潜在特征的替换。这样不仅实现了对参考图像的一致性保持,同时也丰富了生成视频的视觉效果。
在代码实现上,关键的处理包括对于image latent和输入噪声的融合,如下:
def prepare_latents:
...
if i2v_mode and i2v_stability:
if img_latents.shape[2] == 1: # img_latents是参考图像的潜在特征
img_latents = mint.tile(img_latents, (1, 1, video_length, 1, 1))
x0 = randn_tensor(shape, generator=generator, dtype=dtype) # 高斯随机噪声
x1 = img_latents
t = ms.tensor([0.999])
latents = x0 * t + x1 * (1 - t) # 对参考图像的潜在特征和高斯随机噪声进行混合
latents = latents.to(dtype=dtype)
if latents is None:
latents = randn_tensor(shape, generator=generator, dtype=dtype)可以看出,i2v_stability 为True时,会进行参考图像和随机噪声的潜在混合,以保持对参考图像的一致性。理论上, 当i2v_stability为False时,生成视频会包含更加丰富的动态信息。
其次,在去噪的前后,对首帧图像的潜在特征进行替换:
def __call__:
...
if i2v_mode and i2v_condition_type == "token_replace":
latents = mint.concat([img_latents.to(latents.dtype), latents[:, :, 1:, :, :]], dim=2) # 在去噪前进行首帧图像潜在特征的替换
...
noise_pred = self.transformer(xxx)
...
if i2v_mode and i2v_condition_type == "token_replace":
latents = self.scheduler.step(
noise_pred[:, :, 1:, :, :], t, latents[:, :, 1:, :, :], **extra_step_kwargs, return_dict=False
)[0]
latents = mint.concat([img_latents.to(latents.dtype), latents], dim=2) # 在去噪后进行首帧图像潜在特征的替换在每一步去噪的前后进行首帧图像潜在特征的替换,有利于对参考图像的一致性保持。
模型介绍
1、环境准备

- CANN下载:https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.0.RC3.beta1
- MindSpore下载:https://www.mindspore.cn/install
2、安装依赖
git clone https://github.com/mindspore-lab/mindone
cd mindone/examples/hunyuanvideo-i2v
pip install -r requirements.txt3、模型下载
| 模型 | 下载链接 | 说明 |
| hyvideo-i2v-13b | https://huggingface.co/tencent/HunyuanVideo-I2V/tree/main | Transformer (LoRA) 及 VAE权重 |
| llava-llama-3-8b | https://huggingface.co/xtuner/llava-llama-3-8b-v1_1-transformers | 多模态模型权重 |
| clip-vit-large-patch14 | https://huggingface.co/openai/clip-vit-large-patch14 | CLIP模型权重 |
FILE_PATH="/path/to/your/image.jpg"
python3 sample_image2video.py \
--prompt "An Asian man with short hair in black tactical uniform and white clothes waves a firework stick." \
--i2v-image-path $FILE_PATH \
--model HYVideo-T/2 \
--i2v-mode \
--i2v-resolution 720p \
--i2v-stability \
--infer-steps 50 \
--video-length 129 \
--flow-reverse \
--flow-shift 7.0 \
--seed 0 \
--embedded-cfg-scale 6.0 \
--save-path ./results \从 Hugging Face 下载所需的模型,可以参考如下命令:
huggingface-cli download tencent/HunyuanVideo-I2V --local-dir ./ckpts4、运行推理
进行图生视频推理也非常简单,运行下面的命令即可:
如果想要自定义视频生成的内容,只需要修改--prompt,输入你脑海中的创意描述即可。另外,你还可以通过修改--i2v-resolution来控制输出的视频分辨率。目前可选择的分辨率有"720p", "540p"和"360p"。
如果你想要尝试LoRA权重来实现更加丰富的视觉效果,只需要在上述的命令行中增加以下的参数即可:
python3 sample_image2video.py \
--prompt $PROMPT \
--i2v-image-path $FILE_PATH \
--lora-path ./ckpts/hunyuan-video-i2v-720p/lora/embrace_kohaya_weights.safetensors \
--model HYVideo-T/2 \
--i2v-mode \
--i2v-resolution 720p \
--i2v-stability \
--infer-steps 50 \
--video-length 129 \
--flow-reverse \
--flow-shift 5.0 \
--embedded-cfg-scale 6.0 \
--seed 0 \
--save-path ./results \
--use-lora \
--lora-scale 1.0 \性能实测
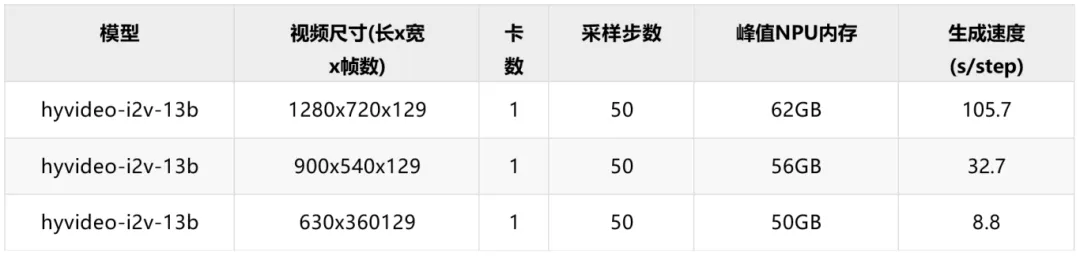
基于Atlas 800T A2和MindSpore2.5.0的性能测试结果如下:
马上体验
我们在魔乐社区上完成了Hunyuanvideo-i2v的部署!
欢迎体验:https://modelers.cn/spaces/MindSpore-lab/hyvideo-i2v

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









