






2024年9月19日至21日,华为全联接大会(HC2024)在上海隆重举办。来自天津大学的王鑫老师在大会期间获得“昇腾科研创新卓越贡献者奖”。作为天津大学智能与计算学部教授、博导、人工智能学院副院长,王鑫老师在古文预训练模型研究积累丰厚,自2022年开始带领团队基于MindSpore原生研发面向古汉语的预训练语言大模型,孵化了生物医学领域大模型—“海河·岐伯”。
生物医学领域大模型“海河·岐伯”
在“海河·岐伯”前期研究中,针对古文的语法语义结构特性,提出了预训练模型RAC-BERT模型,其在继承Transformer编码器结构的同时,根据古文任务需求,对模型做出相应改进,设计了新的基于部首的预训练任务,调整模型参数,优化网络结构,在大规模古籍语料基础上进行训练,在CCLUE测评基准下相比于BETR-base模型提升了5%以上。该研究成果在知名国际学术会议发表论文。
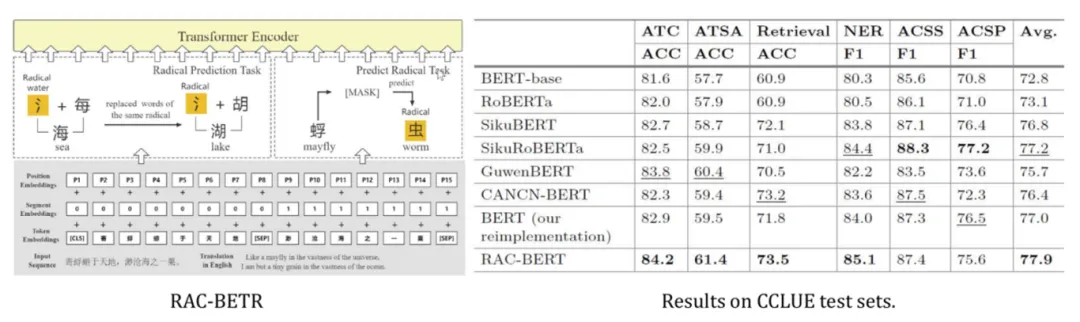
论文链接:
https://link.springer.com/chapter/10.1007/978-3-031-44696-2_59
昇思MindSpore版开源代码链接:
https://github.com/CubeHan/RAC-BERT
基于前期的研究成果,为了进一步应用大模型到生物医学领域(中医药领域),对中文基座模型进行微调使其获取识别中医药实体的能力;通过构造中医药知识图谱,处理部分中医药相关知识,设计实现了大模型结合知识图谱的问答系统,该研究成果在国内核心期刊发表论文。
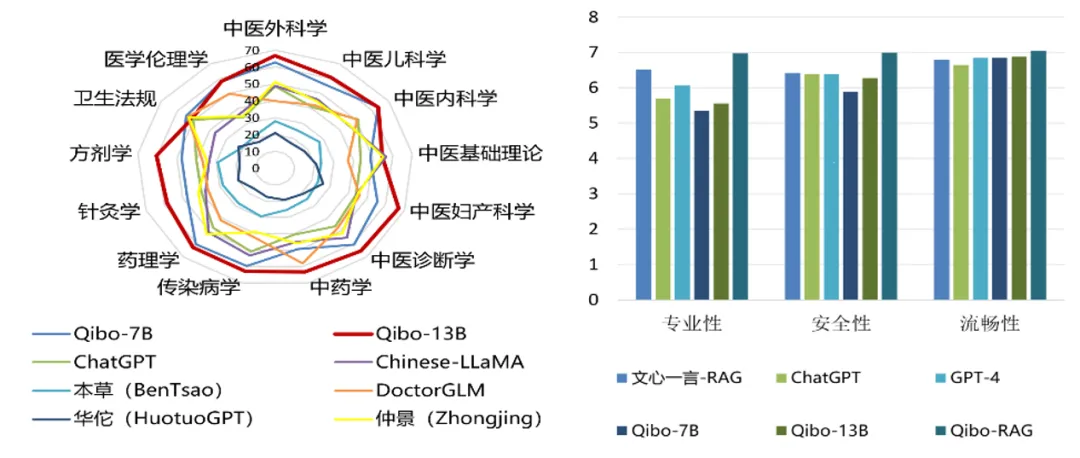
最后,为了进一步提升大语言模型在中医药领域性能,进行中医药领域的二次预训练与指令微调得到“海河·岐伯”大模型。“海河·岐伯”大模型在中医药相关的13个科目选择题共计2237道题的测试中达到最优,7位中医药专家在中医药方面进行的主观评估,“海河·岐伯”达到最优。
论文链接:
https://link.cnki.net/urlid/11.5602.TP.20230920.1152.004
MindSpore版开源代码链接:
https://github.com/zhangheyi-1/llmkgqas-tcm
昇思AI框架使能“海河·岐伯”训练提速
“海河·岐伯”在训练过程中,充分利用了昇思MindSpore框架的多种并行策略,通过流水并行、数据并行等混合并行训练模式,使得“海河岐伯”的训练效率提升了20%。同时,利用昇思MindSpore提供的混合精度的计算方式,在保持计算精度的同时,提高了计算效率和减少了内存占用。此外,针对开发过程遇到的训练调试问题,充分利用昇思MindSpore Insight可视化调试调优工具,缩短模型精度问题定位的时间。最后,在最新的训练中,采用昇思MindSpore的新特性多级编译技术,开启O1编译选项增加自动算子融合优化,以提升内存复用率,相比于动态图获取更高的性能收益。

“海河·岐伯”获得中国人工智能学会-昇思MindSpore学术基金支持,并携手天津市人工智能计算中心联合开展产业化探索,通过天大智图公司进行商用。


未来,王鑫老师团队将持续携手昇思,构建中医药领域知识图谱,整合古今中医药文献、方剂、药物、疾病等知识,并持续收集整理中医药领域相关数据,对“海河·岐伯”进行迭代训练与优化,提高模型的训练效率和精度。此外,结合中医药“望闻问切”的特性,研发中医药多模态大模型。最终,围绕模型打造落地应用,开发智能化中医诊疗系统,从而实现学术创新到产业落地的闭环,助力学术界与产业界生态繁荣。

















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









