







 本文介绍了LRTG,一种用于多视图子空间聚类的低秩张量图学习方法。LRTG克服了传统子空间聚类方法的局限,通过Tucker分解和l2,1-范数减少噪声和异常值,同时学习表示矩阵和亲和矩阵。实验表明,LRTG在多视图聚类任务中表现出优越的性能。"
113385027,9230207,Java @Mock与@InjectMocks及@Mock与@Spy差异解析,"['Java', '后端开发', '单元测试']
本文介绍了LRTG,一种用于多视图子空间聚类的低秩张量图学习方法。LRTG克服了传统子空间聚类方法的局限,通过Tucker分解和l2,1-范数减少噪声和异常值,同时学习表示矩阵和亲和矩阵。实验表明,LRTG在多视图聚类任务中表现出优越的性能。"
113385027,9230207,Java @Mock与@InjectMocks及@Mock与@Spy差异解析,"['Java', '后端开发', '单元测试']
@[TOC](Low-Rank Tensor Graph Learning for Multi-view Subspace Clustering(LRTG))
★论文笔记-Low-Rank Tensor Graph Learning for Multi-view Subspace Clustering(LRRG)
文章链接:https://www.researchgate.net/publication/349011448_Low-Rank_Tensor_Graph_Learning_for_Multi-view_Subspace_Clustering
作者:Yongyong Chen, Xiaolin Xiao, Chong Peng, Guangming Lu, and Yicong Zhou, Senior Member, IEEE,
摘要:图和子空间聚类方法以其良好的性能成为多视图聚类的主流。然而,(1)由于图聚类方法直接从原始数据中学习图,当原始数据被噪声和异常值扭曲时,其性能可能会严重降低;(2) 子空间聚类方法使用“两步”策略独立地学习表示矩阵和亲和矩阵,因此可能无法探索它们的高度相关性。为了解决这些问题,我们提出了一种新的多视图聚类方法,通过学习低秩张量图(LRTG)。与子空间聚类方法不同,LRTG在一步中同时学习表示矩阵和亲和矩阵,以保持它们的相关性。我们将Tucker分解和l2,1-范数应用于LRTG模型,以减少噪声和异常值,从而学习“干净”表示。LRTG然后从这个“干净”表示中学习亲和矩阵。此外,还提出了一种自适应邻域方案,以找到亲和矩阵的K个最大项,从而形成一个灵活的聚类图。
引言
子空间聚类已成为发现高维数据底层结构的重要工具[1]。它的目的是同时将数据点分组到其基本簇中,并找到低维子空间表示[1–4]。为了得到具有块对角性质的表示矩阵,许多工作考虑了不同的正则化子,如稀疏度[5]、低rankness[6]、平滑表示[7]、平滑表示[3]、平滑表示[3],和块对角表示[8],假设高维数据可以建模为从多个低维子空间并集提取的样本。
为了将现有的单视图子空间聚类方法扩展到多视图环境中,我们探索了两种常见的方案:(1)学习所有视图共享的公共潜在空间,以探索一致性;(2) 引入低秩张量约束来捕获多个视图之间的高阶相关性。
总之,在自我表达性假设下,大多数现有的MVSC方法遵循“两步”策略,即**首先探索不同的正则化器对表示矩阵施加特定的结构约束,然后通过学习的表示矩阵构建图。**因此,学习的亲和矩阵可能是次优的,并且难以捕获所有数据点之间的真实关系。
为了克服上述局限性,我们提出了一种用于多视图子空间聚类的低秩张量图(LRTG)。LRTG的主要思想是从“干净”表示张量中学习自适应亲和矩阵,而不是从受污染的原始数据中学习。通过Tucker分解,表示张量具有低秩性质。
工作总结
- 我们提出LRTG作为一个统一的模型来学习多视图子空间聚类的低秩张量图。LRTG能够在一个步骤中同时学习表示和亲和矩阵。它还对噪声和异常值具有鲁棒性
- 我们对LRTG模型使用Tucker分解和l2,1-范数,分别探索低秩特性和去除噪声和异常值。然后获得一个“干净”表示来学习亲和矩阵。
- 针对LRTG模型提出了一种自适应邻域方案,以找到亲和矩阵的K个最大项,然后获得一个灵活的聚类图。
相关工作
-
多视图图聚类
多视图图聚类方法直接利用原始数据构造亲和矩阵。例如,k-最近邻[34]使用余弦或热核距离来度量相似性。…
-
多视图子空间聚类
受高维数据通常位于几个低维子空间的并集这一事实的启发,子空间聚类是将数据点同时聚类到多个子空间中,并找到一个低维子空间来适合每个组[6,37]。表示矩阵Z通常可以从以下方面学习:
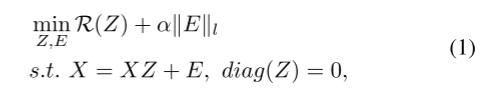
其中X是特征矩阵,E表示噪声。L-范数对于不同类型的噪声是特定的。主要区别在于不同的正则化器R。SSC[5]使用l1-范数( R ( Z ) = ∣ ∣ Z ∣ ∣ 1 R(Z)=||Z||_1 R(Z)=∣∣Z∣∣1),而LRR使用核范数( R ( Z ) = ∣ ∣ Z ∣ ∣ ∗ R(Z)=||Z||_* R(Z)=∣∣Z∣∣∗)。…
-
Tucker Decomposition 塔克分解

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









