







自动驾驶数据集多为分割任务数据集,或同时包含检测标签和分割标签,对于backbone的预训练,多使用常规的图像分类数据集和目标检测数据集,如:ImageNet、Pascal VOC、COCO等,对于常规数据集,此处不做介绍。
数据集的形式通常为原始图片/视频 + 标签文件,对于分类、目标检测任务,标签文件通常为json格式,对于分割任务,标签文件通常为掩码格式,示例如下:
ApolloScape车道线原始图片及掩码标签示例:





驾驶数据集
MIT DriveSeg
基本介绍
官网:MIT DriveSeg Dataset for Dynamic Driving Scene Segmentation | MIT AgeLab
MIT联合丰田公司在2020年6月份发布的,用于动态驾驶场景分割的MIT DriveSeg数据集,并提供完全开放的免费下载。
有两个版本:
-
MIT DriveSeg (Manual) :手动标注版本,在马萨诸塞州剑桥市繁忙的街道上白天旅行期间捕获的2分47秒的高分辨率视频,面向车前的逐帧像素级语义标记数据集
-
MIT DriveSeg (Semi-auto) :半自动标注版本,从MIT高级车辆技术(AVT)联盟数据中提取的67个视频片段,与手动版的区别在于:1)半自动标注(比手动版粗略) 2)帧数更多(20100帧vs5000帧) 3)分辨率略低(720Pvs1080P)
下载方式
官方链接:(免费下载,需注册IEEE账号)
MIT DriveSeg (Manual) Dataset | IEEE DataPort
MIT DriveSeg (Semi-auto) Dataset | IEEE DataPort
数据集内容
MIT DriveSeg (Manual) :
-
视频数据:2分47秒(5,000帧),1080P(1920x1080),30fps
-
分类类别:共12类:vehicle, pedestrian, road, sidewalk, bicycle, motorcycle, building, terrain (horizontal vegetation), vegetation (vertical vegetation), pole, traffic light, and traffic sign
MIT DriveSeg (Semi-auto) :
-
视频数据:67个片段:10秒(20,100帧),720P(1280x720),30fps
-
分类类别:共12类:vehicle, pedestrian, road, sidewalk, bicycle, motorcycle, building, terrain (horizontal vegetation), vegetation (vertical vegetation), pole, traffic light, and traffic sign
数据集解压后有两个文件夹和一个json文件(以MIT DriveSeg (Manual)为例):
-
config.json:12个类别label及其id
-
frames文件夹:5000个png图片,对应5000帧画面
-
labels文件夹:5000个png图片,每个png图片对应那一帧画面,像素点的颜色数据即label的id(1~12)(直接打开这个png文件显示效果接近纯黑图片)
KITTI
基本介绍
官网:The KITTI Vision Benchmark Suite
由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。
该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。
包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。
整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成,以10Hz的频率采样及同步。
总体上看,原始数据集被分类为’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’五类。原始数据采集于2011年的5天,共有180GB数据。
对于3D物体检测,label细分为Car, Van, Truck, Pedestrian, Person(sitting), Cyclist, Tram,Misc。
各场景下的目标对象比例如下:

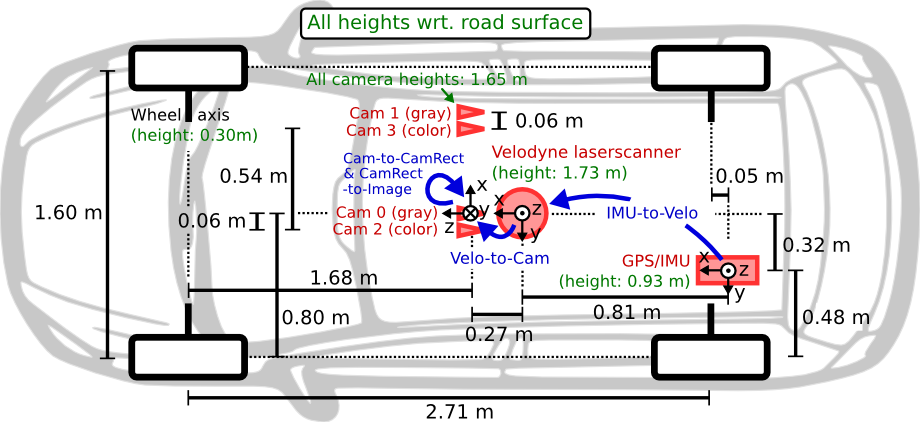
记录平台是一辆大众帕萨特B6,安装了如下传感器:
-
1个惯导系统 Inertial Navigation System (GPS/IMU): 型号OXTS RT 3003
-
1个激光雷达,型号Velodyne HDL-64E(每秒10帧,64线)
-
2个灰度相机(一组),140万像素,型号Point Grey Flea 2 (FL2-14S3M-C):1382 x 512,每秒10帧,由激光雷达触发,快门速度是动态调整的,最大快门时间为2ms
-
2个彩色相机(一组),140万像素,型号Point Grey Flea 2 (FL2-14S3C-C):1382 x 512,每秒10帧,由激光雷达触发,快门速度是动态调整的,最大快门时间为2ms
-
4个变焦镜头,焦距4-8mm,型号Edmund Optics NT59-917

下载方式
数据集分为多个分任务:如object、tracking等,在对应页面下可以下载对应的数据集;(需注册并提交下载目的描述,不少于100字符)
The KITTI Vision Benchmark Suite
The KITTI Vision Benchmark Suite
The KITTI Vision Benchmark Suite
数据集内容
object分任务下有三个数据集:
-
Object Detection Evaluation 2012 (2D):7481张训练图片 + 7518张测试图片,png格式彩色图片
-
3D Object Detection Evaluation 2017 (3D):7481张训练图片与点云数据 + 7518张测试图片与点云数据
-
Bird’s Eye View Evaluation 2017 :7481张训练图片与点云数据 + 7518张测试图片与点云数据
tracking分任务下有三个数据集:
-
Object Tracking Evaluation (2D bounding-boxes) :21个训练视频 + 29个测试视频
-
Multi-Object Tracking and Segmentation (MOTS) Evaluation :21个训练视频 + 29个测试视频
-
Segmenting and Tracking Every Pixel (STEP) Evaluation :21个训练视频 + 29个测试视频
KITTI各个子数据集都提供开发工具 development kit,使开发者能够同时使用激光雷达点云,gps数据,右边彩色摄像机数据以及灰度摄像机图像等多模态数据;
KITTI也提供了数据集格式转换工具,链接同数据集链接,可以将KITTI格式转换为Pascal VOC格式等。
KITTI-360
基本介绍
KITTI全新推出的自动驾驶数据集,包括在73.7公里的行驶距离内产生的32万张图像和10万个激光扫描文件。
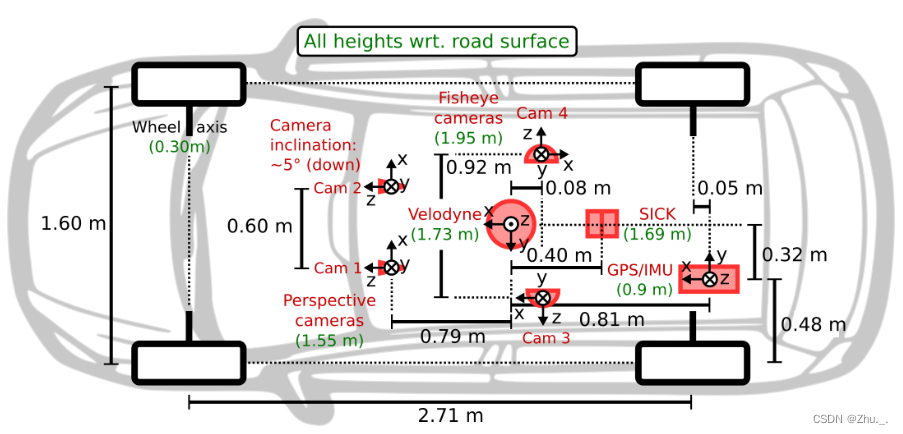
传感器:
- 1个激光雷达:Velodyne HDL-64E
- 1个激光雷达:SICK LMS 200
- 1个 90° 透视立体相机(2个镜头)
- 2个 180° 鱼眼相机
- 1个 IMU/GPS系统
下载方式
官网链接:(需使用KITTI账号登录)
数据集内容
数据集内容为:标定数据;2D数据(图片/分割标签);3D数据(激光雷达数据/分割标签/bbox)
ApolloScape
基本介绍
百度公司提供的ApolloScape数据集,包括具有高分辨率图像和每像素标注的RGB视频,具有语义分割的测量级密集3D点,立体视频和全景图像。
完整的数据集为Scene Parsing,同时提供数据集子集:
- 3D Car Instance ,不同城市的街景视频5000+帧
- Lane Segmentation ,具有高质量的像素级注释110,000+帧
- Self Localization ,有更多的场景和100倍的大数据,包括在不同光照条件下(即早上、中午和晚上)录制的视频(大数据不包含点云)
- Trajectory ,城市街道大规模轨迹数据集可用于规划、预测和模拟任务
- 3D Lidar Object Detection and Tracking ,大规模城市交通数据集,包括具有高质量注释的连续3D激光雷达点云,可以用于三维检测和跟踪任务
- Stereo ,重遮挡的城市立体图像对大规模数据集
- Inpainting ,由同步标记图像和激光雷达扫描点云组成的大规模数据集,可以用于修补和其他任务
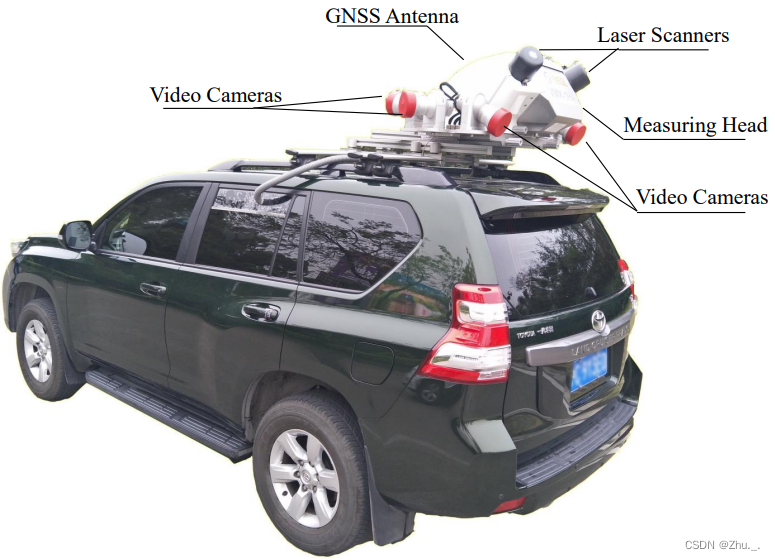
采集所用的传感器:
- RIEGL VMX-1HA双激光头移动测图系统:
- 2个VUX-1HA高精度激光雷达(比Velodyne产生点云更精确、更稠密)
- 1个VMX-CS6摄像头系统(含6个摄像头,其中两个前视摄像头精度为3384×2710)
- 1个IMU/GNSS系统
下载方式
官网有Sample Data,如需完整数据集需发邮件获取
数据集内容
以如下数据集子集为例:
3D Car Instance :
- camera:cam文件,相机内参;
- car_models:pkl文件,参与采集的车辆模型,便于python使用;
- car_poses:json文件,每一张图片对应的相机姿态(pose),含多组car_id和pose;
- images:jpg文件,相机图片;
- split:txt文件,训练集与测试集的图片列表。
Lane Segmentation :
- 数据集以道路为区分,第一层级为道路文件夹;
- 各道路文件夹下有ColorImage和Label文件夹;
- ColorImage和Label文件夹下都有多个Record文件夹;
- Record文件夹下分为两个摄像头(Camera 5 和 Camera 6);
- ColorImage的摄像头文件夹下为每一帧的图片,格式jpg;
- Label的摄像头文件夹下为对应每一帧图片的像素级可视化标签,不同标签以不同颜色显示,格式png。
3D Lidar Object Detection and Tracking :激光雷达数据集,每秒10帧拍摄,每秒2帧打标签,含53分钟的训练视频段和50分钟的测试视频段
- 激光雷达数据:PCD(Point Cloud Data)文件/bin文件;
- 标签数据:
- 每个文件为1分钟长度,2fps;
- 内容包含:frame_id, object_id, object_type, position_x, position_y, position_z, object_length, object_width, object_height, heading;
- object_id仅用来进行追踪;
- object_type:1 for small vehicles, 2 for big vehicles, 3 for pedestrian, 4 for motorcyclist and bicyclist, 5 for traffic cones and 6 for others
- position为相对坐标系结果,单位为米;
- heading为相对于object方向的转向弧度。
- 激光雷达姿态数据(lidar pose)
BDD-100k
基本介绍
包含10万段高清视频,每个视频约40秒,720p,30fps。每个视频的第10秒对关键帧进行采样,得到10万张图片(图片尺寸:1280 * 720 ),并进行标注。注释图像来自纽约和旧金山地区。
针对不同子数据集,有不同的标签类别,详见 Label Format — BDD100K documentation ,比如目标识别的分类为:
1: pedestrian 2: rider 3: car 4: truck 5: bus 6: train 7: motorcycle 8: bicycle 9: traffic light 10: traffic sign
下载方式
在 Berkeley DeepDrive 注册后,进入download标签,同意License后可点击相应子集进行下载。
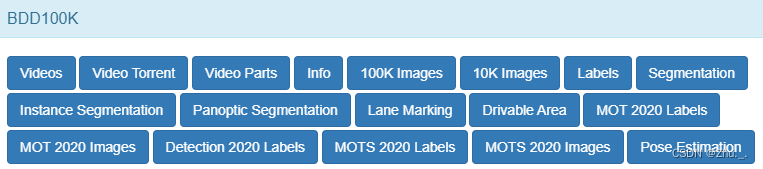
数据集内容
各子集的详细介绍见:Data Download — BDD100K documentation
Videos :100K视频片段,30Hz,mov文件
Video Torrent :100K视频的种子文件
Video Parts :100K视频片段的分段打包,便于下载
Info :GPS/IMU信息,分为train+val两个文件夹,json文件,每个文件内容包含:
- rideID
- accelerometer:x/y/z/timestamp
- gyro:x/y/z/timestamp
- timelapse
- locations:timestamp/longitude/course/latitude/speed/accuracy
- filename:对应的video文件名
- startTime
- endTime
- id
- gps:timestamp/altitude/longitude/vertical accuracy/horizontal accuracy/latitude/speed
100K Images :100K图片,取自每个视频片段的第10秒,用于目标检测、可行驶区域、车道线
10K Images :10K图片(非100K的子集但有显著重叠),jpg文件,用于语义分割、实例分割、全景分割
Labels (旧版,新版为Detection 2020 Labels):两个json文件(train+val),对应100K每张图片的weather/scene/timeofday/timestamp/labels信息,labels信息包含:
- category
- attributes
- occluded
- truncated
- trafficLightColor:如果分类不是交通灯,则为none
- manualShape
- manualAttributes
- box2d(x1y1x2y2)
- label id
Drivable Area :分3个文件夹(masks/colormaps/polygons),分别为分割标签(png文件)/分割标签可视化形式(png文件)/json文件,json文件内容:
- name:对应图片名
- labels:标签
- id
- attributes
- areaType:如direct/alternative
- category
- poly2d:vertices/types(L/C,数量对应vertices)/closed
Lane Marking :分4个文件夹(masks/colormaps/polygons),json文件内容:
- name:对应图片名
- labels
- id
- attributes:
- laneDirection:如parallel
- laneStyle:如solid/dashed
- laneTypes:如road curb/single white
- category
- poly2d:vertices/types(L/C,数量对应vertices)/closed
Semantic Segmentation :分4个文件夹(masks/colormaps/polygons/rles),polygons的json文件内容:
- name:对应图片名
- timestamp
- labels
- id
- category
- poly2d:vertices/types(L/C,数量对应vertices)/closed
Instance Segmentation :分4个文件夹(masks/colormaps/polygons/rles),与Semantic Segmentation结构相同
Panoptic Segmentation :分3个文件夹(masks/colormaps/polygons),与Semantic Segmentation结构相同
MOT 2020 Images/MOT 2020 Labels :bbox追踪,是100K视频的子集并降采样到5Hz,标签为json文件,以Scalabel Format形式存储
MOTS 2020 Images/MOTS 2020 Labels :分割追踪,视频是MOT 2020 Images的子集
Detection 2020 Labels :2020年重新发布的目标检测标签,两个json文件(train+val),对应100K每张图片的weather/scene/timeofday/timestamp/labels信息,labels信息包含:
- label id
- attributes
- occluded
- truncated
- trafficLightColor:如果分类不是交通灯,则为NA
- category
- box2d(x1y1x2y2)
Pose Estimation Labels :姿态估计训练集,标签主要内容为:category/box2d(xyxy)/graph(各nodes:location/category/visibility/id)
Cityscapes
基本介绍
官网:Cityscapes Dataset – Semantic Understanding of Urban Street Scenes
专注于城市的街景主义理解,其本质是一个计算机视觉语义分割数据集。提供的下载数据集中测试集和验证集有标注,测试集提供原图,无标注,可以把结果上传到项目主页,然后验证你算法。
采集范围:50个城市、覆盖春/夏/秋、白天阶段、优良/中等的气候条件、手动选取的图像帧(动态目标多、场景多、背景多)
数据量:5000张细粒度标注图像、20000张粗粒度标注图像
语义分割以及车辆和行人的实例分割;
共计30个类别:
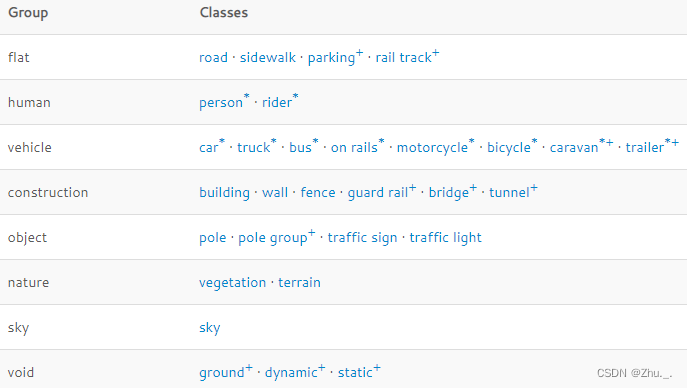
Cityscapes提供三个级别的识别效果评估:语义分割/实例分割/全景分割
下载方式
官网链接:(需用公司或学校邮箱注册)
数据集内容
数据包含:
- 连续的视频帧,1.8s,30帧,并对第20个图像进行标注
- stereo views
- GPS坐标
- 根据测距得到的车辆自运动数据
- 外部温度
- 行人的bbox(其他研究者补充)
- 雨、雾天气扩展(其他研究者补充)
数据集文件结构:
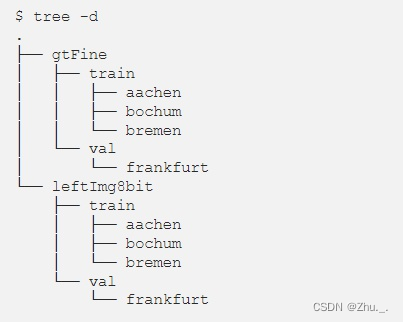
其中,gtFine为精细真值图像,leftImg8bit为左侧8位图像;
训练集/测试集下以城市名为文件夹
官方提供的辅助脚本:GitHub - mcordts/cityscapesScripts: README and scripts for the Cityscapes Dataset
nuScenes
基本介绍
由Motional(前身为nuTonomy)团队开发的用于自动驾驶的共有大型数据集。
数据集来源于波士顿和新加坡采集的1000个驾驶场景,每个场景选取了20秒长的视频,包括大约140万个图像、39万个激光雷达点云、140万个雷达扫描和4万个关键帧中的140万个对象边界框。
用于采集的车辆装备了1个旋转雷达(spinning LIDAR, Velodyne HDL32E),5个远程雷达传感器(long range RADAR sensor, Continental ARS 408-21),6个相机(camera, Basler acA1600-60gc),1套IMU&GPS系统(Advanced Navigation Spatial)。
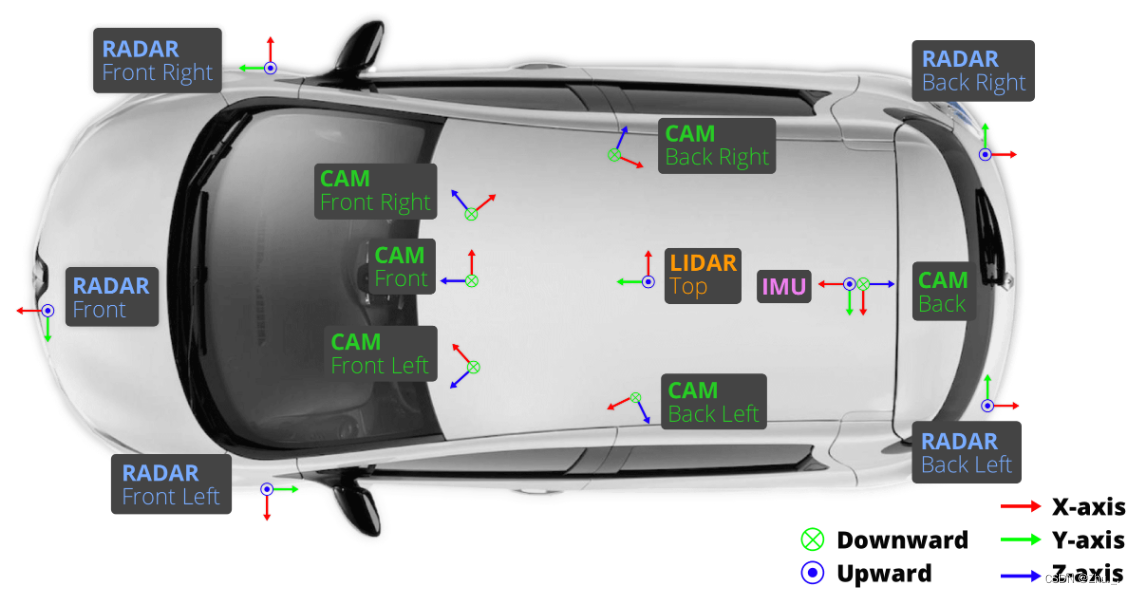 下载方式
下载方式
官网链接:(需注册)
https://www.nuscenes.org/nuscenes#download
数据集内容
数据集共1000个驾驶场景,700个作为训练集、150个作为验证集、150个作为测试集:
- Full dataset (v1.0):提供Keyframe、Lidar、Radar、Camera独立压缩包下载。解压后为以下文件夹:
- maps:地图数据,png文件
- samples:样本文件,结构与sweeps一致
- sweeps:传感器数据,含12个子文件夹
- CAM_BACK/BACK_LEFT/BACK_RIGHT/FRONT/FRONT_LEFT/FRONT_RIGHT:jpg格式图片
- LIDAR_TOP:bin格式数据
- RADAR_BACK_LEFT/BACK_RIGHT/FRONT/FRONT_LEFT/FRONT_RIGHT:pcd格式数据
- v1.0:各json文件,关系及内容如图所示:
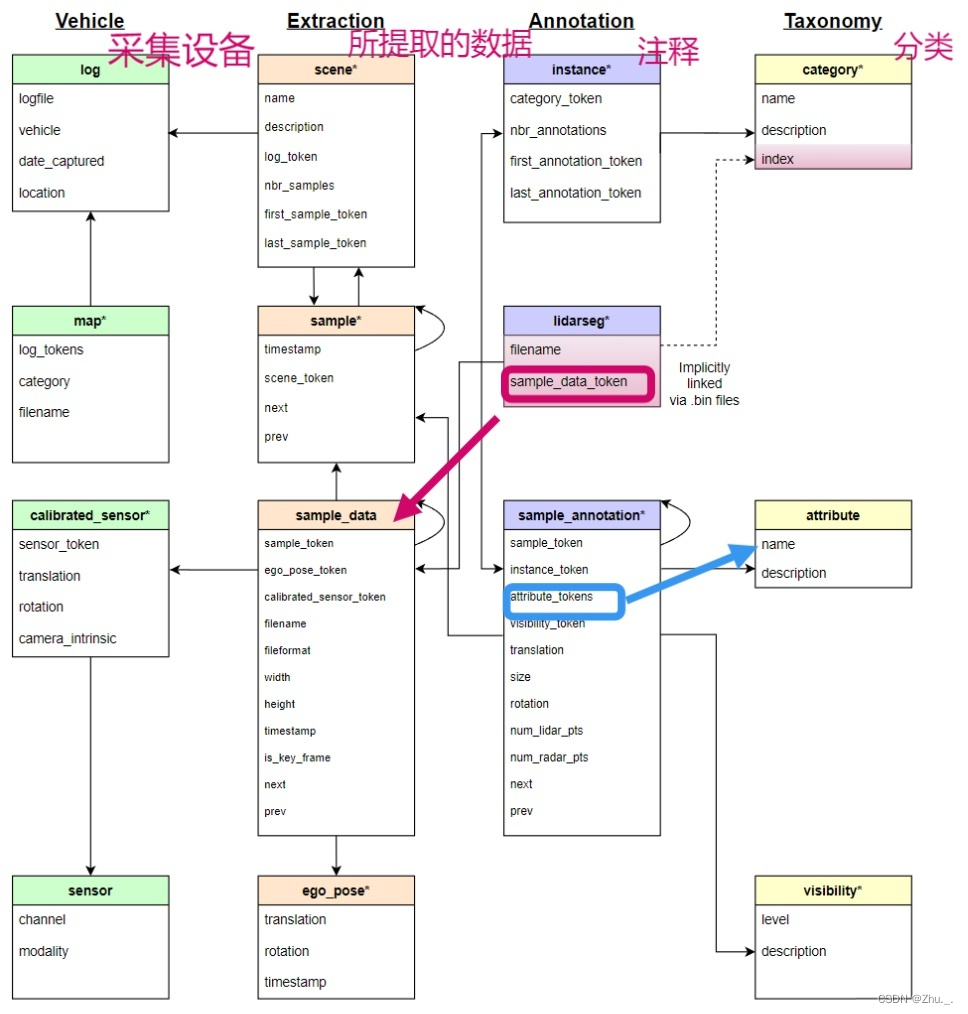
标签分为以下子集:(数据集的分割标签文件无法直接识别,需依赖官方提供的辅助脚本:https://github.com/nutonomy/nuscenes-devkit )
- nuScenes-panoptic:全景分割标签(npz文件):结合激光雷达数据来创建全景标签,每个点有一个语义标签和一个实例id
- nuScenes-lidarseg:激光雷达分割标签:对点云数据在32个语义标签下进行标注
此外还有两个扩展集:
- CAN bus expansion:CAN总线数据,含:vehicle route, IMU, pose, steering angle feedback, battery, brakes, gear position, signals, wheel speeds, throttle, torque, solar sensors, odometry and more
- Map expansion:地图数据,含11层语义信息(crosswalk, sidewalk, traffic lights, stop lines, lanes, etc.)
交通标志数据集
国外的交通标志数据集如比利时的KUL Belgium Traffic Sign Dataset、德国的German Traffic Sign(GTSDB)等,对于国内的道路交通环境不一定适用;
国内目前公开的交通标志数据集主要有两个:
- CCTSDB, CSUST Chinese Traffic Sign Detection Benchmark:长沙理工大学制作的中国交通标志检测数据集
- TT-100k, Tsinghua-Tencent 100k:由清华和腾讯联合制作的数据集
CCTSDB
基本介绍
CCTSDB数据集是由长沙理工大学综合交通运输大数据智能处理湖南省重点实验室张建明老师团队制作完成,标注了常见的指示标志、禁令标志及警告标志三大类交通标志,分为CCTSDB2017和CCTSDB2021。
CCTSDB2017数据集介绍见github:GitHub - csust7zhangjm/CCTSDB: CSUST Chinese Traffic Sign Detection Benchmark
CCTSDB2021数据集介绍见github:GitHub - csust7zhangjm/CCTSDB2021
下载方式
CCTSDB2017:
- 百度云链接:百度网盘 请输入提取码 提取码:rv4s
CCTSDB2021:
- 百度云链接:百度网盘 请输入提取码 提取码:nygx
- Google Drive:https://drive.google.com/drive/folders/14Km2W-5hbixXDfz7WSqW_Rx7O5m8ZMFn?usp=sharing
数据集内容
CCTSDB2017包含图片15734张,交通标志近40000个,仅标注了指示标志、禁止标志、警告标志三类。
CCTSDB2021共17856张图片(16356张训练集、1500张测试集),xml文件内为bbox数据(xyxy)。
Tsinghua-Tencent 100k
基本介绍
官网介绍:index
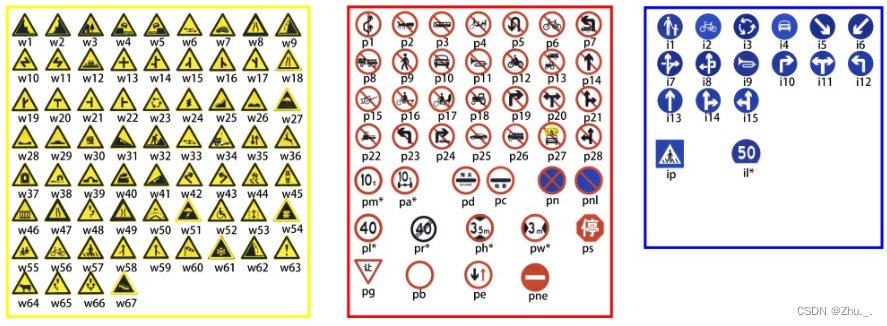
从10万张腾讯街景全景图中创建了一个大型交通标志基准,称之为清华-腾讯100K基准;
提供100,000个图像,包含30000个交通标志实例,涵盖了光照和天气条件的变化;
原始的街景全景图分辨率为8192x2048,再将全景图裁剪分为四份,最终数据集的尺寸为2048x2048;
每个交通标志都注释了类别标签、bbox、像素分割,如下所示:

下载方式
官网下载:
数据集内容
分为两个数据集:
- Tsinghua-Tencent 100K Annotations 2016
- Tsinghua-Tencent 100K Annotations 2021(类别更多)
数据集分以下文件夹/文件:
- train:训练集图片,jpg文件
- test:测试集图片,jpg文件
- other:从训练集和测试集排除的图
- masks:标准图,png文件
- annotations.json文件:标签数据:
- path:图片路径
- objects:
- category
- bbox(xyxy)
- ellipse_org[[x1,y1],[x2,y2],…]:椭圆的标注点
- ellipse[[x_o,y_o],[r_l,r_s],angle]:根据椭圆标注点拟合的椭圆
- polygon[[x1,y1],[x2,y2],…]:三角形的标注点

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









