






首先谈一下什么是目标检测

目录
R-CNN
主要动机:
(1)图像特征。传统的目标检测方法使用的是SIFI和HOG采取像素级别的特征,鲁棒性和泛化能里较差。RCNN从这个点出发进行模型设计,考虑到图像特征的重要性(RCNN正文第一句话:Features matter),使用深度学习来获取图像特征。然而由于目标检测的数据集PASCAL VOC 2007过小,直接使用PASCAL VOC 2007进行模型训练容易出现过拟合等现象,因此RCNN使用图像分类中的ImageNet ILSVC 2012数据集来为目标检测模型进行初始化。
(2)R-CNN将目标检测分成了定位和分类两个子问题。OverFeat采用滑动窗口在输入图像或者特征图上进行滑动,以此来完成区域的界定,这种窗口滑动方法虽然可以有效确定目标的位置区域,但是这个过程非常复杂,需要耗费大量的计算量,很难在实际应用场景中使用,R-CNN提出Regions with CNN features,首先先基于图像生成2000个左右的候选框,然后对这些候选框分别进行分类和定位,最后在进行汇总。
网络框架:

step 1 获取候选区域:对于一张输入的图像,首先使用selective search算法获取2000个左右的候选区域,由于selective search生成的候选区域是大小不一致的区域,而后续的卷积神经网络中的全连接层需要保证固定大小的输入,因此在输入卷积网络之后将其缩放至固定大小的图像;论文中采用的是227×227。
step 2 特征提取:将图像输入到卷积神经网络中获取图像特征,这一部分可以采用常用的图像卷积神经网络如VGGNet,AlexNet等。RCNN采用在ImageNet数据集上预训练完成的模型进行初始化,由于ImageNet数据集包括1000个类别,而PASCAL VOC只有21个类别(包括20个物体类别和1个背景类别,因此需要将最终的全连接层改成4096->21,因此对之前的特征提取模型进行微调。关于训练此部分的数据,RCNN使用IOU来完成正负样本的定义,IOU(真实框,候选框)小于0.5的视为负样本,IOU大于0.5的视为正样本,每轮训练batch包含128个样本,其中32个正样本,96个负样本。
step 3 SVM分类:在训练SVM时,将IOU小于0.3的样本视为负样本,将ground truth当做正例,其他所有的样本都被丢弃,此外还在训练过程中使用了hard negative mining策略(加快收敛),重点训练哪些容易分错的样本。
这里需要特别说明的是RCNN在补充材料部分讨论了为什么需要使用SVM来对候选区域进行分类而不是直接用卷积神经网络的全连接层输出,理由如下:由于卷积神经网络的训练较多的训练样本,将IOU小于0.3的样本视为负样本(即与上述训练SVM的设置方式一样)导致过拟合现象的出现,而将0.5作为阈值来划分正负样本则会造成候选区域的定位不精确,由于SVM训练需要的样本没有那么多,因此可以使用阈值0.3来确定样本。为此,RCNN在训练模型时使用SVM来获取区域类别,同时对于训练卷积神经网络和SVM采用不同的正负样本划分策略。
step 4 Bounding-Box regression:尽管Selective search方法会生成2000个左右的候选区域,但是也很难保证这些候选区域与真值完全一致,为此在此基础上进一步微调是非常有必要的。RCNN使用线性回归器对位置进行微调微调,得到更加准确的边界框。

P-候选框 G'-微调后的框 G-真实框
微调的目的:候选框通过平移或者缩放,使其微调后的区域框不断接近真实框,最后通过非极大值抑制留下最终候选框。
SPP-Net
论文:https://arxiv.org/pdf/1406.4729.pdf
主要动机:
(1)卷积神经网络的全连接层需要固定输入的尺寸,而Selective search所得到的候选区域存在尺寸上的差异,无法直接输入到卷积神经网络中实现区域的特征提取,因此RCNN先将候选区缩放至指定大小随后再输入到模型中进行特征提取。无论是通过区域裁剪还是缩放来实现区域大小的固定,其实都是一种次优的操作。

解决方案:
空间金字塔层(Spatial pyramid pooling layer)

当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)
(2)R-CNN使用Selective Search从图像中获取候选区域,然后依次将候选区域输入到卷积神经网络中进行图像特征提取,如果有2000个候选区域,则需要进行2000次独立的特征提取过程。然后,这2000个候选区域是存在一定程度的重叠的,所以如此设计会导致大量的冗余计算。
解决方案:共享特征。在具体的实现上,SPPNet直接将原图输入到卷积神经网络中获取图像特征,然后利用区域和特征图之间的映射关系得到候选区域的特征。

SPP-Net通过可视化Conv5层特征,发现卷积特征其实保存了空间位置信息(数学推理中更容易发现这点),并且每一个卷积核负责提取不同的特征。
如何从一个region proposal 映射到feature map?(文章附录中有提及)
假设原始图像的中心点是(x,y) 特征图上的中心点是(x',y')
左边(上边)
右边(下边)
S代表CNN中所有的stride,包括卷积,池化等
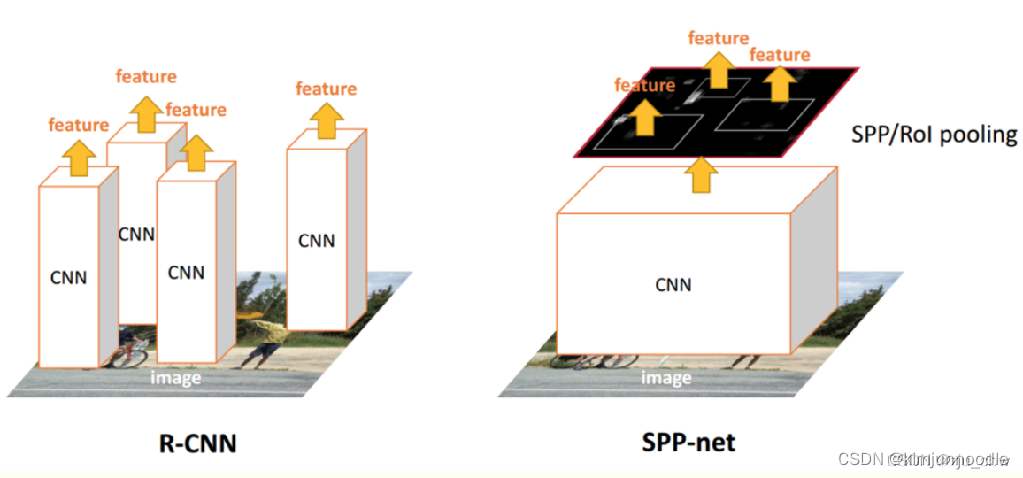
| R-CNN | SPP-Net |
| 1、R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2、固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 | 1、SPPNet把全图塞给CNN得到全图的feature map 2、让候选区域与feature map直接映射,得到候选区域的映射特征向量 3、映射过来的特征向量大小不固定,这些特征向量塞给SPP层(空间金字塔变换层),SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层 |
Fast R-CNN
论文:
主要动机:
(1)R-CNN需要多阶段//在训练过程需要花费较多的时间和空间//目标识别较慢等问题
(2)SPP-Net虽然大幅度提高了运行速度,但是任然需要多阶段训练//同时R-CNN无法在spp层之前更新CNN的参数
相比于RCNN主要在以下方面进行了改进:
(1)Fast R-CNN仍然使用selective search选取2000个建议框,但是这里不是将这么多建议框都输入卷积网络中,而是将原始图片输入卷积网络中得到特征图,再使用建议框对特征图提取特征框。这样做的好处是,原来建议框重合部分非常多,卷积重复计算严重,而这里每个位置都只计算了一次卷积,大大减少了计算量;
(2)由于建议框大小不一,得到的特征框需要转化为相同大小,这一步是通过ROI Pooling层来实现的(ROI表示region of interest即目标)
(3)Fast RCNN里没有SVM分类器和回归器了,分类和预测框的位置大小都是通过卷积神经网络输出。
(4)为了提高计算速度,网络最后使用SVD代替全连接层
网络框架
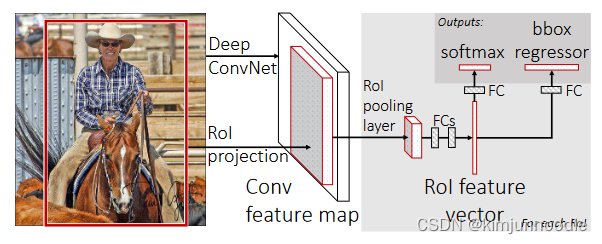
(1)使用selective search选取建议框;
(2)将原始图片输入卷积神经网络之中,获取特征图;
(3)根据建议框与特征图截取特征;
(4)将每个特征框划分为H×W个网格(论文中是7×7),在每个网格内进行最大池化,这就是ROI池化。这样每个特征框就被转化为了7×7×C的矩阵(其中C为特征图深度);
(5)对每个矩阵拉长为一个向量,分别作为之后的全连接层的输入;
(6)全连接层的输出有两个第一个是sotfmax的21类分类器(假设有20个类别+背景类),输出属于每一类的概率(所有建议框的输出构成得分矩阵);第二个是输出一个20×4的矩阵,4代表回归框的(x,y,w,h),20表示20个类,这里是对20个类分别计算了框的位置和大小;
(7)对输出的得分矩阵使用非极大抑制方法选出少数框,对每一个框选择概率最大的类作为标注的类,根据网络结构的第二个输出,选择对应类下的位置和大小对图像进行标注。
ROI Pooling:简单讲可以看做是SPPNet的简化版本,因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换。
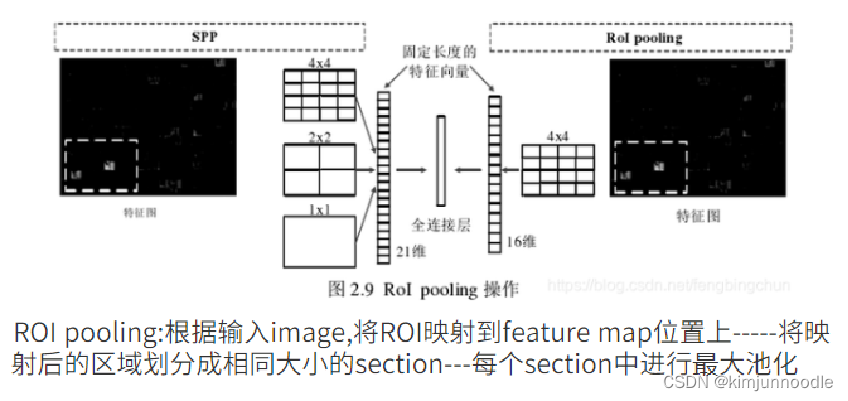
初始化训练网络:
- 输入既有image也可以是ROIs
- 最后一个卷积的池化层被ROI pooling取代
- softmax输出从1000改成了(k+1)
微调网络:
在Faster R-CNN 训练中,随机梯度下降 (SGD) 迷你批次按层次结构进行采样(Mini batch sampling),首先通过对N张图像进行采样,然后从每个图像中采样R/N个特征。至关重要的是,来自同一图像的RoI在正向和向后传递中共享计算和内存。缩小N可减少小批量计算。例如,当使用 N=2和 R=128时,建议的训练方案比从 128 张不同的图像(即 R-CNN 和 SPPnet 策略)中采样一个 RoI 快大约快 64 倍。
Faster R-CNN的Faster在哪里?
多任务损失

,
这里为什么不使用L2损失?相比于R-CNN 和 SPP-net 中使用的L2损失函数,其对离群点、异常值不敏感,当回归目标不受限制时,L2损失的训练可能需要仔细调整学习速率,以防止梯度爆炸。smooth L1消除了这种灵敏度。
小批量采样
在微调期间,每个 SGD 小批量处理都是从N=2张图像中构造的,这些图像是随机均匀选择的(按照通常的做法,我们实际上迭代数据集的排列)。我们使用大小为 R=128的批量,从每个映像中抽取 64 个 ROI。与R-CNN中的一样,从对象提案中获取25%的RoI,这些对象提案与至少0.5的地面真值边界框重叠。在训练期间,图像以 0.5 的概率水平翻转。不使用其他数据扩充。
RoI Pooling的反向传播
普通max pooling反向传播与RoI max pooling反向传播解读_xunan003的博客-CSDN博客_max pooling 反向传播
简单的奇异值分解对FC层进行加速
AMS :: Feature Column from the AMS
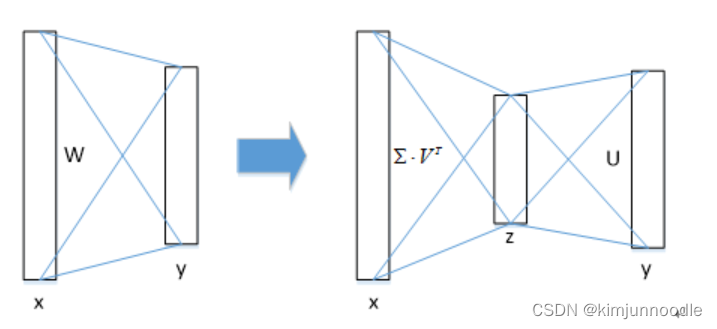
物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为:y=Wx,计算复杂度为u×v;
若将W进行SVD分解,并用前t个特征值近似代替,即:
![]()
那么计算复杂度就变成了t(u+v)















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









