






HDFS中每个块的大小以及为什么是128MB —— 深入理解Hadoop分布式文件系统的核心设计
随着大数据时代的到来,数据量呈爆炸式增长,传统的文件系统难以满足对大规模数据存储与处理的需求。为了解决这一问题,Apache Hadoop 应运而生,其中最核心的模块之一就是 HDFS(Hadoop Distributed File System)。HDFS 采用“分布式存储”的方式,将大文件拆分为多个数据块(Block)分布存储在多个节点上,从而实现高可靠性和高吞吐量。
在 HDFS 中,“块”的大小是一个至关重要的设计参数,直接影响系统的性能、可靠性和可扩展性。默认情况下,HDFS 的块大小为 128MB(Hadoop 2.x 及以后版本),而这一设计并非偶然选择,而是经过大量工程实践与理论分析得出的最优解。

本文将围绕以下几个方面,深入探讨 HDFS 的块大小设计及其背后的原理:
-
块在 HDFS 中的定义与作用
-
块大小从64MB到128MB的演进历程
-
为什么选择128MB:从系统性能、I/O效率、NameNode内存消耗、容错能力等方面分析
-
块大小与 MapReduce 作业性能的关系
-
块大小设置的可调性与实际生产环境配置建议
-
与其他分布式存储系统对比
二、HDFS中的块:定义与作用
1. 什么是块(Block)
在传统文件系统中,文件被划分为若干小块(如4KB)存储在磁盘上。但在 HDFS 中,块的单位远大于传统文件系统,默认大小为 128MB。这些块不是物理磁盘块,而是逻辑块,由 HDFS 管理。
一个大文件在上传到 HDFS 时,会被切分成多个块,分别存储在不同的 DataNode 上,并由 NameNode 维护每个块的元数据(位置、副本等信息)。
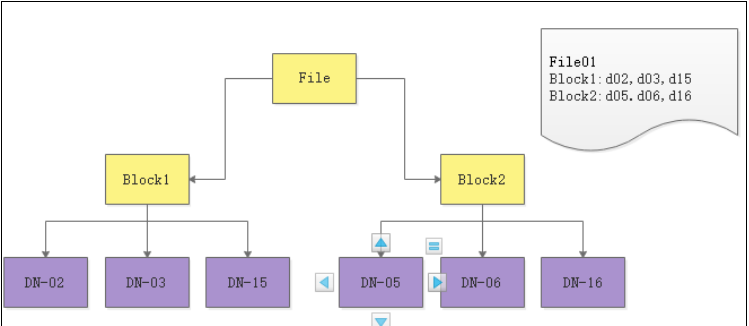
2. 块的作用
- 便于大文件的分布式存储与处理
- 实现数据并行处理(如 MapReduce)
- 提供容错机制(多副本)
- 降低单点故障风险
三、块大小的演进历程
1. Hadoop 1.x:默认64MB
最早期的 Hadoop 版本中,默认块大小为 64MB。当时硬件资源有限、网络带宽较小,64MB 被认为是一个合理的选择,兼顾了并行处理和系统资源占用。
2. Hadoop 2.x 及以后:默认128MB
随着硬件发展,尤其是磁盘吞吐量与网络带宽的提升,64MB 渐渐不能满足大规模数据处理的需求。从 Hadoop 2.x 开始,块大小默认值提升到 128MB,以适应更高性能的数据处理场景。
四、为什么HDFS选择128MB作为默认块大小
HDFS 之所以选择128MB作为默认块大小,主要考虑了以下几个方面:
1. 减少 NameNode 的内存开销
NameNode 是 HDFS 的元数据中心,它负责记录每个文件的块信息。每一个块在内存中都需要占用一定的空间(约150字节/块)。如果块太小,则会显著增加 NameNode 的内存负担。
示例对比:
| 块大小 | 存储1TB数据需要的块数 | NameNode元数据总量(估算) |
|---|---|---|
| 64MB | ~16,000块 | ~2.4MB |
| 128MB | ~8,000块 | ~1.2MB |
| 256MB | ~4,000块 | ~600KB |
2. 提高数据传输效率(减少磁盘和网络I/O频率)
较大的块意味着:
- 每次传输的数据量大,网络连接建立频率少
- 减少磁盘查找次数,提升顺序读写效率
在大数据场景中,顺序读写远远优于随机读写,大块数据能更好地发挥磁盘吞吐能力。
3. 提高 MapReduce 性能
在 MapReduce 中,每个块通常对应一个 Mapper。块太小意味着 Mapper 数量过多,导致:
- 作业启动、调度开销变大
- 集群负载不均衡
- 整体执行时间增加
较大的块可使作业调度更高效,每个 Mapper 能处理更多数据。
4. 减少元数据通信开销
客户端在读取文件时,需要首先从 NameNode 获取块位置信息。块数量越多,需要的通信次数越多,网络开销越大。128MB 能在块数量和通信频率之间找到平衡点。
5. 更好地支持容错机制
HDFS 默认每个块有3个副本。块越小,副本总数量越多,意味着副本维护、复制、同步的成本更高。而大块减少了副本数量,提高了副本调度效率。
五、块大小与MapReduce作业的关系
1. 块大小决定Mapper数量
MapReduce 框架按块划分输入分片(InputSplit)。通常,一个块对应一个Mapper。块小→Mapper多→作业调度复杂,反之则简化调度过程。
2. 大块提升处理效率
大块使得每个 Mapper 能充分发挥其 CPU 和 I/O 能力,避免频繁切换任务,提高任务处理效率。
3. 结合数据本地性(Data Locality)
MapReduce 会尽量将计算调度到数据本地节点上运行,大块数据能使本地化调度效果更显著,减少网络传输。
六、块大小设置的灵活性
1. 配置方式
HDFS 块大小可以通过以下方式设置:
xml复制编辑<!-- hdfs-site.xml -->
<property>
<name>dfs.block.size</name>
<value>134217728</value> <!-- 128MB -->
</property>
也可以在上传文件时通过命令行指定:
bash
复制编辑
hadoop fs -Ddfs.block.size=268435456 -put bigfile.txt /user/hdfs/
2. 实际应用中的块大小选择建议
| 文件大小 | 建议块大小 | 原因说明 |
|---|---|---|
| 小于500MB | 64MB | 减少资源浪费 |
| 500MB - 1GB | 128MB | 默认值适用,大多数场景通用 |
| 大于1GB | 256MB+ | 减少块数量,提高处理效率 |
| TB级别大文件 | 512MB~1GB | 进一步减小NameNode负担 |
七、与其他分布式存储系统的块大小对比
| 系统 | 默认块大小 | 特点说明 |
|---|---|---|
| HDFS | 128MB | 平衡I/O与元数据,适合大数据处理 |
| Amazon S3 | N/A | 面向对象存储,按Key存取 |
| Google GFS | 64MB | 最早的分布式文件系统设计之一 |
| Alluxio | 512MB | 面向内存加速场景,块更大 |
| Ceph | 可配置 | 块对象灵活,适合多种存储需求 |
面向对象存储,按Key存取 |
| Google GFS | 64MB | 最早的分布式文件系统设计之一 |
| Alluxio | 512MB | 面向内存加速场景,块更大 |
| Ceph | 可配置 | 块对象灵活,适合多种存储需求 |

















 3847
3847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









