






利用ReliefF算法对分类特征变量做特征重要性排序,实现特征选择。
通过重要性排序图,选择重要的特征变量,以期实现数据降维的目的。
程序直接替换数据就可以用,程序内有注释,方便学习和使用。
程序语言为matlab。
ID:41200703190825194
芝麻绿豆
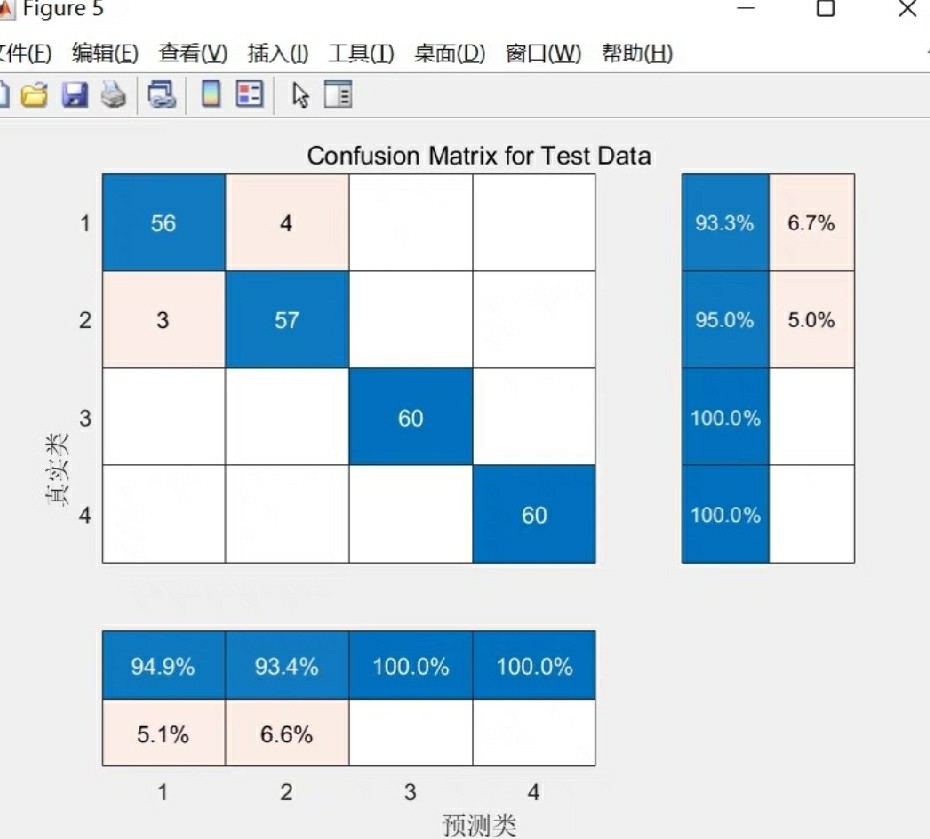
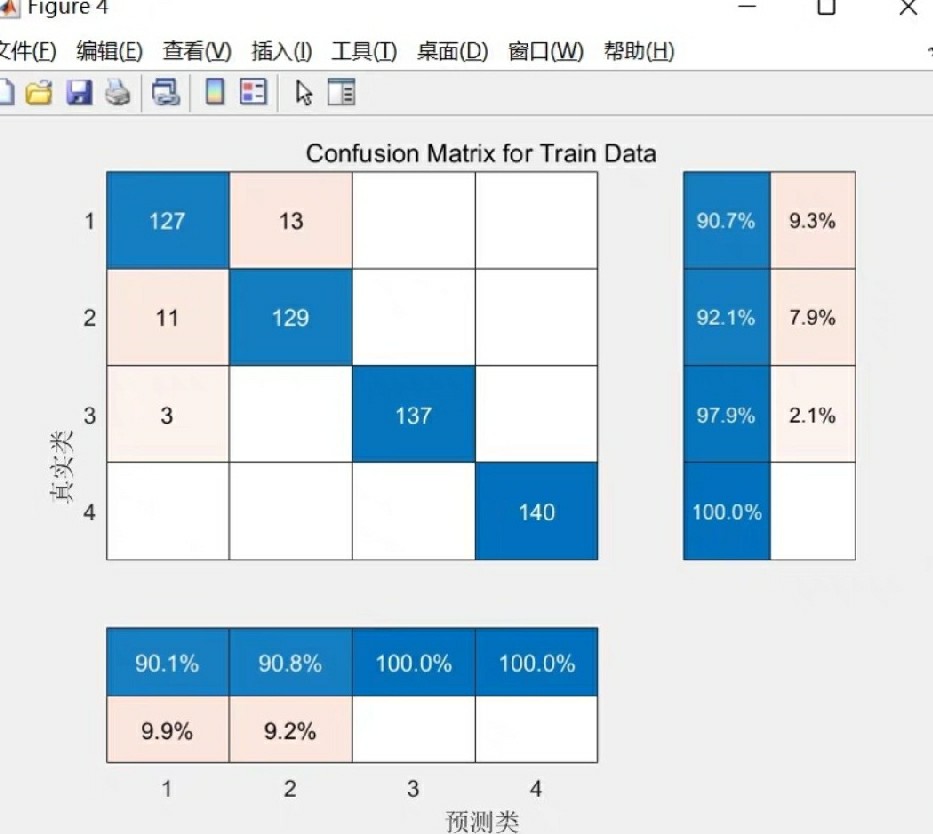
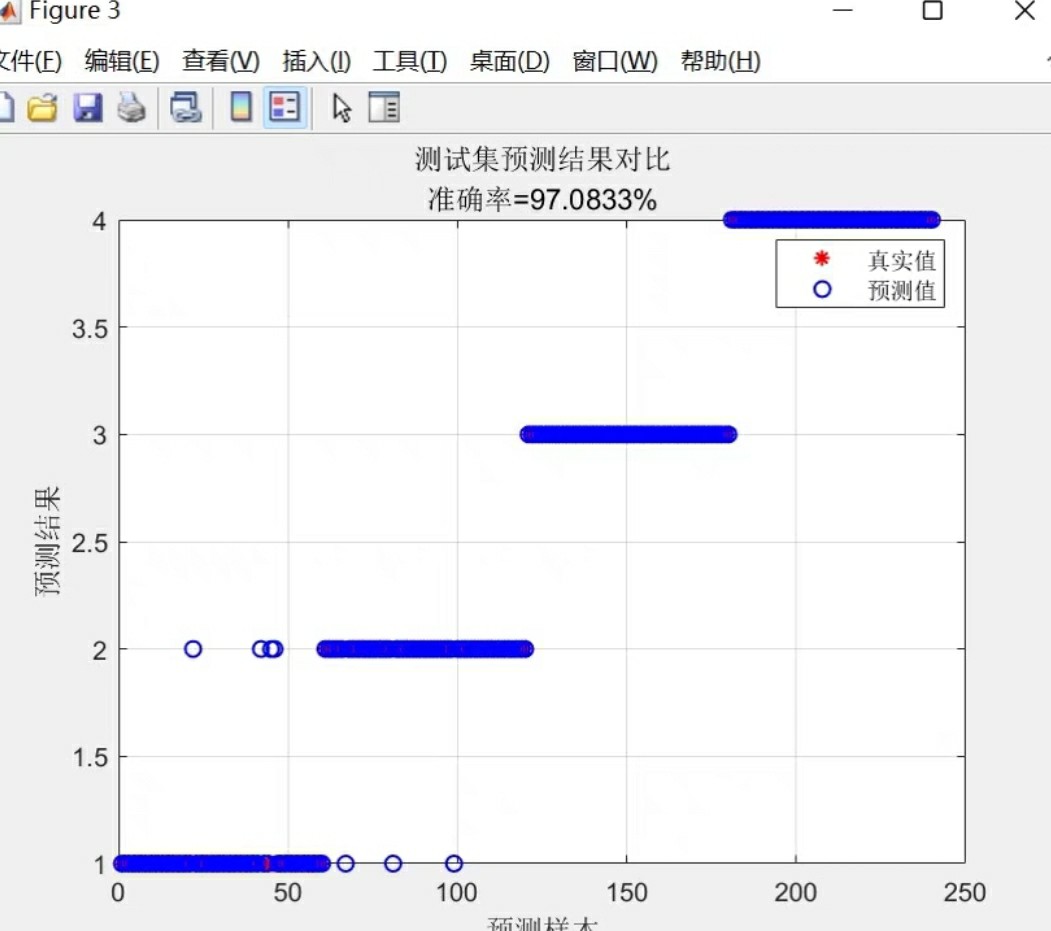
在数据分析和机器学习领域,特征选择是一项重要的任务。通过对特征变量进行排序和选择,我们能够更好地理解数据集并提高模型的性能。本文将介绍一种名为ReliefF的特征选择算法,该算法可用于对分类特征变量进行重要性排序,并通过选择重要的特征变量来实现数据降维的目的。该算法的实现基于Matlab,程序内包含详细的注释,方便学习和使用。
在数据分析的过程中,特征选择是一项关键的任务。通过选择重要的特征变量,我们可以减少特征空间的维度,从而简化模型的复杂度和计算量。此外,特征选择还可以帮助我们更好地理解数据,并提取与目标变量相关性最强的特征。
ReliefF算法是一种经典的特征选择算法,广泛应用于数据挖掘和机器学习领域。该算法基于实例之间的差异度量特征的重要性,通过评估特征对类别分离的贡献来进行特征重要性的排序。在ReliefF算法中,特征的重要性通过计算特征间的差异程度来获得。
具体而言,ReliefF算法通过计算每个实例与最近邻实例之间的差异来对特征进行权重计算。对于分类特征变量,ReliefF算法将特征的权重定义为该特征对于实例之间类别差异的贡献程度。通过计算所有实例的特征权重,并对其进行归一化处理,我们可以得到每个特征的重要性分数。
使用ReliefF算法对特征进行重要性排序的一种常见方法是生成一个重要性排序图。在该图中,特征按照其重要性分数从高到低进行排序,并以直观的方式展示出来。通过观察重要性排序图,我们可以选择排名靠前的特征作为我们的重要特征变量,以实现数据降维的目的。
在实现ReliefF算法时,我们提供了一个Matlab程序,该程序可以直接替换数据,并且内部包含了详细的注释,方便用户学习和使用。通过使用这个程序,用户可以轻松地对分类特征变量进行特征选择,以获得与目标变量相关性最强的特征。同时,该程序还为用户提供了学习和理解ReliefF算法的机会。
总之,ReliefF算法是一种有效的特征选择算法,可以帮助我们理解数据集并提高模型的性能。通过对分类特征变量进行重要性排序,并选择重要的特征变量,我们可以实现数据降维的目的,并提取与目标变量相关性最强的特征。通过本文提供的Matlab程序,用户可以轻松地学习和使用ReliefF算法,并在实际应用中取得良好的效果。
【相关代码 程序地址】: http://nodep.cn/703190825194.html















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









