






目录
一.简介
1.1概念
支持向量机(Support Vector Machine,简称SVM)是一种监督学习算法,用于数据分类和回归分析。其目标是找到一个最优的超平面,将数据集划分成不同的类别。在这个过程中,SVM关注的是距离超平面最近的一些数据点,这些数据点被称为支持向量。
1.2优点
-
泛化能力:SVM通过最大化分类间隔(margin)来训练模型,这有助于减少模型的泛化误差,提高模型在未知数据上的表现。
-
适用于小样本:SVM算法在样本数量较少的情况下依然有效,因为它不依赖于整个数据集,而是依赖于支持向量。
-
高维数据处理:SVM通过使用核技巧可以有效地处理高维数据,即将数据映射到高维特征空间中,使得原本线性不可分的数据在新空间中变得线性可分。
-
避免过拟合:由于SVM的目标是最小化分类误差的同时最大化分类间隔,这有助于防止模型过拟合。
-
鲁棒性:SVM在参数选择合适的情况下,对于噪声和异常值有较好的鲁棒性。
1.3缺点
-
计算和存储成本:SVM算法的训练时间复杂度较高,为O(n^2)或O(n^3),在处理大规模数据集时会非常慢。此外,如果使用核函数,还需要存储核矩阵,这会占用大量内存。
-
参数选择:SVM算法中有多个参数需要调整,如C(惩罚参数)、核函数类型及参数等,参数的选择对模型性能有很大影响,需要通过交叉验证等方法进行优选。
-
非线性问题的核函数选择:对于非线性问题,核函数的选择和参数设置对模型性能至关重要,但没有通用的规则来确定最佳的核函数,通常需要根据具体问题进行尝试。
-
预测速度:SVM的预测速度可能较慢,尤其是当有大量支持向量时。
-
对不平衡数据的敏感性:如果数据集是类别不平衡的,SVM可能不会很好地工作,因为它旨在最大化间隔,而不考虑类别的分布。
二.支持向量机(SVM)
2.1工作原理
-
数据映射:SVM首先将输入数据映射到一个高维特征空间,这通常通过使用核函数来实现。映射的目的是为了找到一个最优的超平面,使得不同类别的数据在这个高维空间中可以被线性分割。
-
寻找最优超平面:在特征空间中,SVM寻找一个最优的超平面,这个超平面能够最好地将不同类别的数据分开,并且最大化分类间隔(margin)。分类间隔是超平面到最近的属于不同类别的数据点的距离。
-
支持向量的确定:那些位于分类间隔边界上的数据点被称为支持向量(support vectors)。它们是决定最优超平面位置的关键点,其他数据点对超平面的位置没有影响。
-
目标函数:SVM的目标是最小化一个目标函数,这个函数由两部分组成:一是分类间隔的宽度,二是误分类的损失。通过优化这个目标函数,可以找到最优的超平面。
-
软间隔:在现实问题中,完全线性可分的情况很少,因此SVM引入了软间隔(soft margin)的概念,允许一定程度上的误分类。这通过引入一个惩罚参数C来实现,C值越大,对误分类的惩罚越重。
-
核函数:对于线性不可分的数据,SVM使用核技巧将数据映射到更高维的空间,使得数据在新的空间中可以线性分割。常用的核函数包括线性核、多项式核、径向基函数(RBF)核和sigmoid核。
-
模型训练:通过解决一个凸二次规划问题,SVM找到最优的超平面参数。在数学上,这通常转化为求解一个对偶问题,使用序列最小优化(SMO)算法等。
-
模型预测:对于新的数据点,SVM通过计算该点到每个支持向量的距离,并使用核函数进行映射,然后将这些距离通过超平面的决策规则(如符号函数)进行分类。
SVM的核心思想是找到一个最优的超平面,使得不同类别的数据可以被最大化间隔地分开。通过引入核函数和软间隔,SVM可以有效地处理非线性问题和一定程度上的噪声数据。
2.2相关数学原理
训练过程:
目标函数:SVM的目标函数是一个凸二次规划问题,其目的是最小化一个由两部分组成的函数:一是与超平面的权重向量\mathbf{w}w相关的正规项,二是与训练数据点的分类误差相关的损失项。
拉格朗日乘子法:为了求解这个优化问题,我们使用拉格朗日乘子法。对于每个训练样本,引入一个拉格朗日乘子
,得到拉格朗日函数:
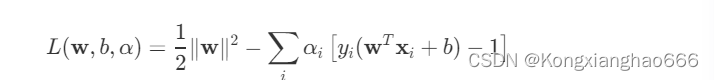 对偶问题: 通过对w和b求偏导并令其等于零,我们可以得到对偶问题:
对偶问题: 通过对w和b求偏导并令其等于零,我们可以得到对偶问题:
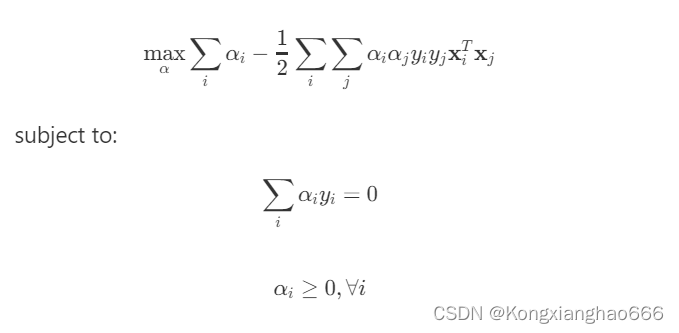
求解题对偶问题:对偶问题通常使用序列最小优化(SMO)算法或其他二次规划求解器来求解,得到最优的值。
计算w和b:一旦我们得到了,我们可以通过以下公式计算w:
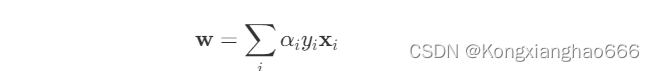
b可以通过选择任意一个支持向量(即>0的样本)并使用其分类约束来计算:

预测过程:
分类决策:对于一个新的数据点x,其分类决策函数为:

使用核函数: 如果在训练过程中使用了核函数,那么在预测时,我们需要将与所有支持向量
进行核函数计算,然后将结果相加并加上偏置b来得到预测值。
三.代码实现
3.1代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# 创建 40 个点
np.random.seed(0)
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
Y = [0] * 20 + [1] * 20
Y = np.array(Y) # 将 Y 转换为 NumPy 数组以便进行索引
# 添加噪点
num_noise = 2
noise_indices = np.random.choice(range(40), num_noise, replace=False)
Y[noise_indices] = 1 - Y[noise_indices]
# 绘制原始数据点
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired, label='Data points')
# 建立 svm 模型,并添加 C 参数来改变对噪点的敏感度
C_values = [0.1, 1, 10, 100] # 尝试不同的 C 值
colors = ['red', 'green', 'blue', 'purple']
for C, color in zip(C_values, colors):
clf = svm.SVC(kernel='linear', C=C)
clf.fit(X, Y)
# 绘制划分超平面
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-5, 5)
yy = a * xx - (clf.intercept_[0]) / w[1]
plt.plot(xx, yy, color=color, label=f'C={C}') # 注意这里使用 color=color 而不是 color + '-'
# 圈出支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none', edgecolors=color, label='_nolegend_')
# 显示图例
plt.legend()
plt.axis('tight')
plt.show()3.2运行截图
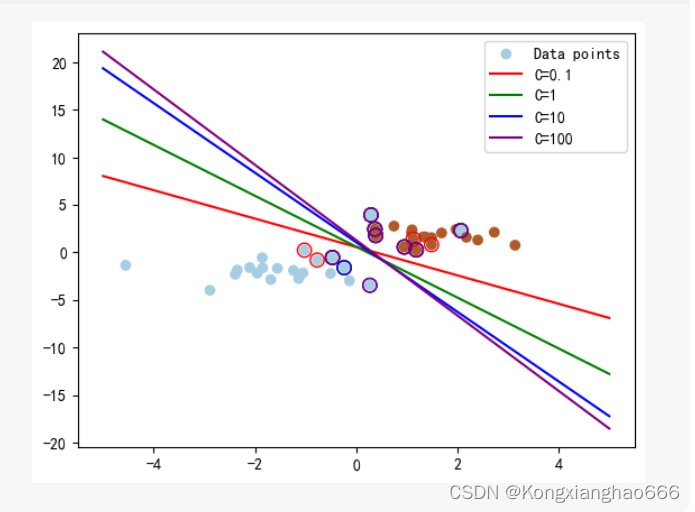
可以看到,随着C值的变化,分类超平面和支持向量的位置也随之改变。C值越小,超平面越倾向于忽略噪点,而C值越大,超平面则更加努力地避免误分类
四.总结
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,用于分类和回归分析。它是由Vapnik和Cortes于1995年提出的,是一种基于统计学习理论的模式识别方法。
总的来说,SVM是一种强大的分类算法,特别适合于中小规模的数据集,并且在特征维度较高时表现出色。然而,在大规模数据和高维特征空间的情况下,SVM的训练和预测成本可能会变得很高,这时可以考虑使用其他算法,如随机梯度下降(SGD)分类器或基于树的算法。















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









