






目录
一.算法简介
1.1算法概述
贝叶斯算法是一种基于概率论的分类方法,它通过计算先验概率和条件概率来预测样本的类别。贝叶斯算法的核心思想是利用已知的信息(如训练数据集)来估计未知参数的概率分布,从而对新的样本进行分类。贝叶斯算法在机器学习、数据挖掘和自然语言处理等领域有着广泛的应用。
二.样本的概率
2.1先验概率
在贝叶斯算法中,先验概率通常指在不考虑特征条件下,样本属于某个类别的概率。例如,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P(c)

2.2条件概率
条件概率是指在一个事件发生的条件下,另一个事件发生的概率。在贝叶斯算法中,条件概率表示在给定类别的情况下,样本具有某种特征的概率。例如,求的先验概率后,对于离散属性而言,令Dcixi表示Dc中在第i个属性上取值为Xi的样本组成的集合,则条件概率

2.3后验概率
后验概率等于先验概率和条件概率的乘积

三.代码实现
3.1准备数据集
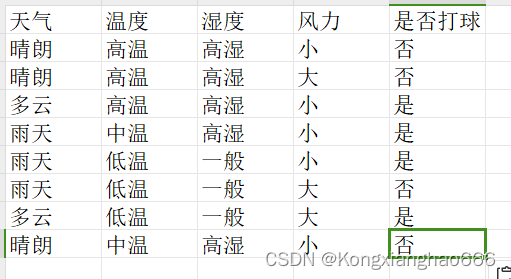
根据天气、温度、湿度、风力判断是否可以打球
数据集
测试集
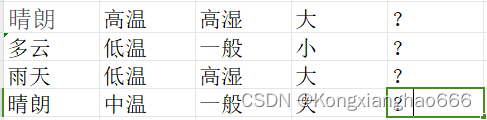
3.2计算概率
先验概率
#计算每个标签的先验概率
def cal_base_rates(data):
y = count_PlayTennis_total(data)
return {label: (y[label] + 1) / (len(data) + 2) for label in y}
条件概率
#计算每个标签下每个特征的条件概率
def likelihold_prob(data):
y = count_PlayTennis_total(data)
likelihold = defaultdict(lambda: defaultdict(int))
for label, count in y.items():
for row in data:
if row[4] == label:
for i, attr_value in enumerate(row[:4]):
likelihold[label][attr_value] += 1
# 规范化概率
for label, attr_dict in likelihold.items():
for attr_value, count in attr_dict.items():
likelihold[label][attr_value] = (count + 1) / (y[label] + count_sj(attr_value, data))
return likelihold
base_rates = cal_base_rates(train)
likehold_probs = likelihold_prob(train)
全部代码
from collections import defaultdict
outlook = ["晴朗", "多云","雨天"]
Temperature = ["高温", "中温","低温"]
Humidity = ["高湿","一般"]
Wind = ["大", "小"]
PlayTennis=["是","否"]
#数据集
data = [ ["晴朗","高温","高湿","小","否"],
["晴朗","高温","高湿","大","否"],
["多云","高温","高湿","小","是"],
["雨天","中温","高湿","小","是"],
["雨天","低温","一般","小","是"],
["雨天","低温","一般","大","否"],
["多云","低温","一般","大","是"],
["晴朗","中温","高湿","小","否"],
["晴朗","低温","一般","小","是"],
["雨天","中温","一般","小","是"],
["晴朗","中温","一般","大","是"],
["多云","中温","高湿","大","是"],
["晴朗","高温","高湿","大","?"],
["多云","低温","一般","小","?"],
["雨天","低温","高湿","大","?"],
["晴朗","中温","一般","大","?"]
]
train_length = 12
train = data[:train_length]
test = data[train_length:]
#计算训练集中每个标签(是否打网球)的频次
def count_PlayTennis_total(data):
return defaultdict(int, {val: sum(1 for row in data if row[4] == val) for val in set(row[4] for row in data)})
#计算每个标签的先验概率
def cal_base_rates(data):
y = count_PlayTennis_total(data)
return {label: (y[label] + 1) / (len(data) + 2) for label in y}
#计算每个特征出现的数量
def count_sj(attr_values, data):
return sum(1 for row in data if attr_values in [row[i] for i in range(4)])
#计算每个标签下每个特征的条件概率
def likelihold_prob(data):
y = count_PlayTennis_total(data)
likelihold = defaultdict(lambda: defaultdict(int))
for label, count in y.items():
for row in data:
if row[4] == label:
for i, attr_value in enumerate(row[:4]):
likelihold[label][attr_value] += 1
# 规范化概率
for label, attr_dict in likelihold.items():
for attr_value, count in attr_dict.items():
likelihold[label][attr_value] = (count + 1) / (y[label] + count_sj(attr_value, data))
return likelihold
base_rates = cal_base_rates(train)
likehold_probs = likelihold_prob(train)
def Test(data, test_features):
y = count_PlayTennis_total(data)
likehold = likelihold_prob(data)
playtennis = cal_base_rates(data)
RATE = defaultdict(float)
# 注意:我们只需要特征部分,因为标签不在测试数据中
for label, count in y.items():
rates = 1.0 # 使用浮点数来存储概率
for j, attr in enumerate(test_features):
rates *= likehold[label][attr]
RATE[label] = rates * playtennis[label]
print("预测结果:")
print(RATE)
print()
# 返回最有可能的标签
return max(RATE, key=RATE.get)
# 调用 Test 函数进行测试
predicted_label_0 = Test(train, test[0][:4])
predicted_label_1 = Test(train, test[1][:4])
predicted_label_2 = Test(train, test[2][:4])
predicted_label_3 = Test(train, test[3][:4])
#输出预测结果
print(f"第一个测试实例的预测标签是: {predicted_label_0}")
print(f"第二个测试实例的预测标签是: {predicted_label_1}")
print(f"第三个测试实例的预测标签是: {predicted_label_2}")
print(f"第四个测试实例的预测标签是: {predicted_label_3}")3.3运行结果
测试集为:
"晴朗","高温","高湿","大","?"
"多云","低温","一般","小","?"
"雨天","低温","高湿","大","?"
"晴朗","中温","一般","大","?"

预测标签为:
否
是
是
是
四.实验小结
通过构建朴素贝叶斯分类器对天气是否适合打球数据集进行分类,我体会到朴素贝叶斯算法的简洁性和解释性。朴素贝叶斯分类器的结构非常直观,易于理解,这使得它在很多领域都有广泛的应用。并且,实验结果表明,在特定条件下,如小样本数据集上,贝叶斯分类器能够提供较好的分类性能。















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









