






Boosting算法原理
Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。Boosting是一种提高任意给定学习算法准确度的方法。
1)提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样本的权值,使误分的样本在后续受到更多的关注。
2)加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
boosting的算法原理我们可以用一张图做一个概括如下:

从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
强学习器:根据得到的弱学习机和相应的权重给出假设(最大程度上符号实际情况)根据天气以往的预测表现及实际天气情况做出综合准确的天气预测
弱学习器:对一定分布的训练样本可以给出假设(仅仅好于随机猜测)例如根据天空有云彩,推测可能会下雨
Boosting算法,我理解的就是两个思想:
- 一堆弱分类器的组合就可以成为一个强分类器
- 不断地在错误中学习,迭代来降低犯错概率
Adaboost
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且还有一个关键点,决策的阈值也需要考虑。
这样,达到“你分不对的我来分”,下一个分类器主要关注上一个分类器没分对的点,每个分类器都各有侧重。
举个例子,在以前没有权重时(其实是平局权重时),一共10个点时,对应每个点的权重都是0.1,分错1个,错误率就加0.1;分错3个,错误率就是0.3。现在,每个点的权重不一样了,还是10个点,权重依次是[0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91],如果分错了第1一个点,那么错误率是0.01,如果分错了第3个点,那么错误率是0.01,要是分错了最后一个点,那么错误率就是0.91。这样,在选择决策点的时候自然是要尽量把权重大的点(本例中是最后一个点)分对才能降低误差率。由此可见,权重分布影响着单层决策树决策点的选择,权重大的点得到更多的关注,权重小的点得到更少的关注。
下面我们来看一下一个二维划分图
原始数据分布如下图:

Adaboost分类器试图把两类数据分开,运行一下程序,显示出决策点,如下图:
注:每一条线代表一个分类器进行的数据切分(共三个分类器)

这样一看,似乎是分开了,不过具体参数是怎样呢?查看程序的输出,可以得到如其决策点与弱分类器权重,在图中标记出来如下:

图中被分成了6分区域,每个区域对应的类别就是:
1号:sign(-0.998277+0.874600-0.608198)=-1
2号:sign(+0.998277+0.874600-0.608198)=+1
3号:sign(+0.998277+0.874600+0.608198)=+1
4号:sign(-0.998277-0.874600-0.608198)=-1
5号:sign(+0.998277-0.874600-0.608198)=-1
6号:sign(+0.998277-0.874600+0.608198)=+1
其中sign(x)是符号函数,正数返回1负数返回-1。
最终得到如下效果:

若是大家还是不理解的话下面我给大家看一个更加易懂的案例,如下
具体案例
接下来,给定下边的数据集D,我们用AdaBoost算法来学习得到一个强分类器
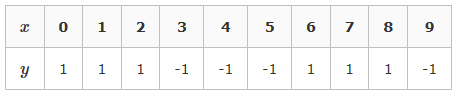
数据集D共有10条数据,根据x的输入得到的y可以分类两类,即y=1与y=-1。我们每一轮使用最简单的决策树桩来构建基分类器,即每轮设定一个阈值θ,只要x<θ,就判定为正类(y=1),x>θ, 就判定为负类(y=-1)。
第一轮
D1(x)
因为是第一轮,故所有样本的权重相同:
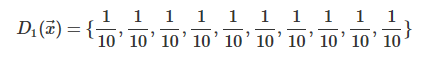
θ
因为是离散数据,所以θ可以依次取0.5,1.5,2.5,...,8.5来对x进行分类,这里可以有两种分类方法:
x<θ时分为正类,x>θ时分为负类,分类错误率对应 ![]()
x>θ时分为正类,x<θ时分为负类,分类错误率对应![]()
最终要选择一个令ϵ1取得最小值的θ与分类方法,这9个值在两种分类方法下,此层h1的错误率![]() 分别为:
分别为:

可以看到![]() 中的0.3*1/10为最小值。对应的,我们取θ为2.5(θ为8.5亦可),使用第一种分类方法。则x为0,1,2的样本分为正类,都分对了;而之后的样本都被分为负类,分错了3个,所以总错误率为3*1/10。故此轮弱分类器的阈值θ取2.5,分类方法取第一种。
中的0.3*1/10为最小值。对应的,我们取θ为2.5(θ为8.5亦可),使用第一种分类方法。则x为0,1,2的样本分为正类,都分对了;而之后的样本都被分为负类,分错了3个,所以总错误率为3*1/10。故此轮弱分类器的阈值θ取2.5,分类方法取第一种。
α1
第一层基分类器h1的权重α1的计算推到方法后面的推导部分再细说,此处只要知道通过如下的公式来计算即可:
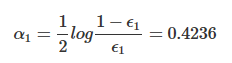
H(x),PA(D)、
根据如下公式计算H(x),此时T为1:
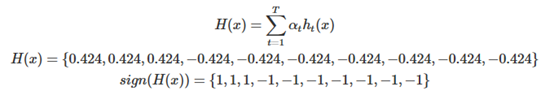
整个模型(现在只有一个基分类器)的准确率为:
![]()
至此第一轮的工作就结束了,可以看出被误分类样本的权值之和影响误差率,误差率影响基分类器在最终分类器中所占的权重。
第二轮
D2(x)
第一轮训练完成后对D1(x)进行更新得到D2(x),更新公式的推导过程也是等到后边的推到部分再说,此处还是只要知道通过下边的公式来计算更新即可:
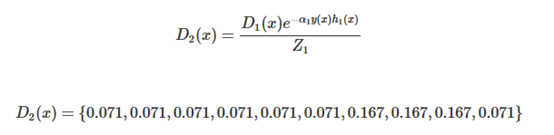
上一轮中x=6、7、8的点分错了,可以看到这三个点在D2中的权重变大了,而其余分类正确的点权重变小了。
θ
我们依然对θ依次取0.5, 1.5, ... , 8.5来对x进行分类,注意我们刚才已经得到了D2(x),样本权重的分布不再是第一轮全部相等的1/10了,如当θ取0.5按第一种分类方法进行分类时,![]() 计算方法如下:
计算方法如下:
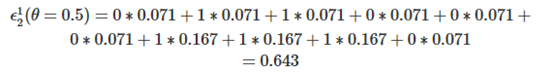
对所有θ与分类方法都按照如上的步骤进行计算,则可得到![]() 与
与![]() 分别为:
分别为:

可以看到![]() 中的0.214为最小值,故此轮弱分类器的阈值θ取8.5,分类方法为第一种。
中的0.214为最小值,故此轮弱分类器的阈值θ取8.5,分类方法为第一种。
α2
依然使用如下公式进行计算:

H(x),PA(D)
继续根据如下公式计算H(x),此时T为2:

整个模型(现在有两个基分类器)的准确率仍然为:
![]()
至此第二轮的工作就结束了,下面我们继续使用上边的方式来看第三轮是否能将准确率提升。
第三轮
D3(x)
使用D2(x)更新得到D3(x)如下:
![]()
上一轮中x=3、4、5的点被分错,所以在D3中的权重变大,其余分类正确的点权重变小。
θ
继续使用之前的方法得到![]() 与
与![]() 分别为:
分别为:

可以看到![]() 中的0.182为最小值,故此轮弱分类器的阈值θ取5.5,分类方法为第二种。
中的0.182为最小值,故此轮弱分类器的阈值θ取5.5,分类方法为第二种。
α2
依然使用如下公式进行计算:
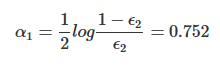
H(x),PA(D)
继续根据如下公式计算H(x),此时T为3:
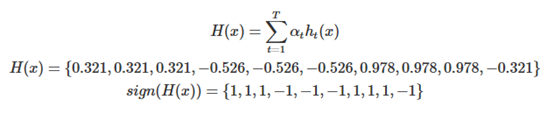
整个模型(现在有三个基分类器)的准确率为:
![]()
至此,我们只用了3个弱(基)分类器就在样本集D上得到了100%的准确率,总结一下:
1.在第tt轮被分错的样本,在下一轮更新得到的Dt+1(x)中权值将被增大
2.在第tt轮被分对的样本,在下一轮更新得到的Dt+1(x)中权值将被减小
3.所使用的决策树桩总是选取让错误率ϵt(所有被ht分类错误的样本在Dt(x)中对应的权值之和)最低的阈值来设计基本分类器
4.最终Adboost得到的H(x)为:
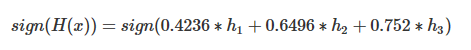
通过三个若分类器迭代出的强分类器就这样得到了。















 3302
3302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









