







一、前言
在前一篇文章中我们介绍了集成学习算法中的Bagging模型,本篇文章将继续介绍集成学习算法中的另一个代表性算法Boosting模型。Boosting是一种可将弱学习器提升为强学习器的算法,其理论依据是Kearns和Valiant首先提出了”强可学习(strongly learnable)”和“弱可学习(weakly learnable)”的概念。他们指出:
- 一个概念(一个类,label),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;
- 一个概念(一个类,label),如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。
- Schapire后来证明了: 强可学习和弱可学习是等价的。 也就是说,在PAC学习的框架下,一个概念是强可学习的 充分必要条件 是 这个概念是弱可学习的。
如此一来,问题便成为:在学习中,如果已经发现了”弱学习算法”,那么能否将它提升为”强学习算法”呢? 因为通常发现弱学习算法通常要比发现强学习算法容易得多。那么如何具体实施提升,便成为Boosting算法的核心问题。
Boosting的工作机制为:先从初始训练集训练出一个基学习器(弱学习器),再根据基学习器的表现对样本分布进行调整,使得先前的基学习器识别错误的训练样本在后面的基学习器中得到更多的关注(调高权重),然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到指定的值,或整个集成算法结果达到退出条件,然后将这些学习器进行加权组合得到最终结果。由前面过程可知Boosting是一个串行学习过程,后一个弱学习器的学习样本依赖于前一个弱学习器的学习结果。Boosting模型较具代表性的算法有GBDT和AdaBoost等。下面详细介绍这两种模型的原理和API。在介绍之前,我们先思考两个问题:①前一个弱学习器在学习完后,怎么调整判断错误和判断正确样本的权重?②对于最终得到的多个弱学习器该怎么组合?即两个权重问题,一个是样本的权重怎么确定,另一个是弱学习器的权重怎么调整?对于任何一种Boosting算法,都需要解决这两个问题,而Boosting算法的核心也正在于这两个问题。

二、AdaBoost
AdaBoost(Adaptive Boosting)是Boosting算法中的一个经典代表,由Yoav Freund和Robert Schapire在1995年提出。
1.1 分类问题
1.1.1 算法原理
对于分类问题,AdaBoost首先从训练集用初始权重训练出一个弱学习器1(弱分类器,只要比随机选择的效果好一些就行),这里的弱学习器可以为浅层决策树等算法,在sklearn的AdaBoost API类AdaBoostClassifier中,默认的弱学习器就是深度为1的决策树。然后根据弱学习器1的学习误差率来更新训练样本的权重并计算弱学习器1在最终组合时的权重,使得弱学习器1识别错误的的训练样本点的权重变高,从而使得这些识别错误的样本在后面的弱学习器2中得到更多的重视。基于调整权重后的训练集来训练弱学习器2(构建第二棵树),如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过加权组合策略进行整合,得到最终的强学习器。具体计算方法如下:
(1)假设我们的训练集样本是一个二分类(类别为-1和1两种)数据集: ,
,在构建第一颗树(第一轮迭代)的时候每个样本的权重
(2)第k个弱学习器在数据集上的加权错误率计算方法为:
其中
其实就是识别错误样本的权重和,例如在构建第一颗树的时候,如果有5个样本识别错误,则
(3)第k个弱学习器在最后组合为强学习器时的权重系数为:
可以发现:分类误差率 越大,则对应的弱分类器权重系数
就越小,即在组合强分类器的时候越不重要
(4)假设第k个弱学习器学习的样本权重为,则第k+1个弱学习器的学习样本权重为:
。
可以发现:前一个弱学习器识别正确的样本权重变小了,识别错误的样本权重变大了。这里是规范化(标准化)因子:
其实就是调整后的权重和,所以很容易得出调整后的样本权重和依然为1,这也解释了为什么在(2)中计算错误率时,可以直接求和错误样本的权重得出。
(5)最终的强分类器组合策略就很容易得出了:
关于上面公式的计算方法,尤其是(3)、(4)中的公式暂时只需要知道怎么计算的即可,至于为什么要这样计算,后面会详细介绍。
1.1.2 案例解析
为了更好地理解1.1.1中介绍的计算方法,本节我们以一个简单的模拟数据集为例来说明AdaBoost的学习过程。
已知有下列样本,用AdaBoost算法学习一个强分类器,默认每个弱学习器都是深度为1的决策树:

(1)构建第一个弱学习器
第一棵树的学习样本权重都是:,原始数据集的10个样本构建决策树有9个候选划分点,分别计算划分点取2.5、5.5、8.5时的弱学习器错误率:
,小于2.5的为1,大于等于2.5的为-1,6、7、8错误
,小于5.5的为-1,大于等于5.5的为1,0、1、2、9错误
,小于8.5的为1,大于等于8.5为-1
可知第一个弱学习器在划分点取2.5时(8.5也可)错误率最低为0.3。此时,第一个弱学习器为:
加权错误率 ,弱学习器权重为:
分类错误样本6、7、8调整后的权重为:
分类正确样本0、1、2、3、4、5、9调整后的权重为:
(2)构建第二个弱学习器
由(1)可知第二个弱学习器学习的样本权重为:。重新遍历所有候选划分点的错误率,可以发现当划分点取8.5时,错误率最低,小于8.5的为1,大于等于8.5的为-1,样本3、4、5判断错误,第二个弱学习器的错误率为
。即得到的第二个弱学习器为:
加权错误率 ,弱学习器权重为:
分类错误样本3、4、5调整后的权重为:
分类正确样本0、1、2调整后的权重为:
分类正确样本6、7、8调整后的权重为:
;
分类正确样本9调整后的权重为:
。
(3)构建第三个弱学习器
由(2)可知第三个弱学习器学习的样本权重为:。重复前面过程即可构建第三个弱学习器,具体划分点选择不再介绍,第三个弱学习器为:
则加权错误率为(0、1、2、9错误):,弱学习器权重为:
新的样本权重计算方法和新的弱学习器构建过程和前面一样,这里不再赘述。不断在前一个弱学习器的基础上构建新的弱学习器,直到达到指定的基学习器数量或者其他停止条件。
假设我们只构建三个弱学习器,则最终的强学习器模型为:
sign表示符号函数:
可以把原始10个样本数据集代入最后的f(x),可以发现10个样本全部识别正确。
1.1.3 损失函数
(1)前向分步加法模型
Adaboost算法其实是前向分步加法模型的特例,下面我们将从什么是前向分步加法模型开始来介绍Adaboost的损失函数。 如下式所示的便是一个加法模型:
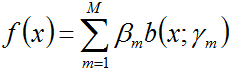
其中,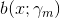
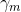

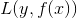
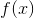
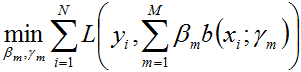
即极小化问题。因为加法模型从前向后,每一步只学习一个基函数及其系数,且是学习前一个基学习器的错误部分,逐步逼近上式,则上式的损失函数可以简化如下,即每步只优化如下损失函数:
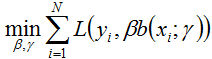
(2) 指数损失函数
(1)中介绍的优化方法就是所谓的前向分步算法。前向分步算法将同时求解从m=1到M的所有参数(

其中,Adaboost使用的是指数损失函数。因为指数损失在分类问题上的效果要比均方误差更好,均方误差损失适合于输出是连续值的情况,例如回归问题。这里需要注意的是,指数损失函数的结果是不可能为0的,也不会接近于0,因为即使识别正确的结果损失也是 ,但是只要识别正确的情况损失更小即可。
(3)Adaboost损失函数
现在回到1.1.1节中的内容,说明几个公式的由来。前面说过,
第k-1轮的强学习器为:
第k轮的强学习器为:
由指数损失函数定义可知,Adaboost损失函数为(注意这里的m是样本数):
利用前向分步学习算法的关系可以得到损失函数为:
这里将指数函数拆成了两部分,已有的强分类器,以及当前弱分类器对训练样本的损失函数,前者在之前的迭代中已经求出,可以看成常数,令,注意这里的
只是符号,与当前的弱分类器无关,使用其他符号也可,不必纠结。目标函数可以简化为:
对于两个未知参数α和G,我们分别求解。上式变换如下:
则基于上式,为了保证损失最小,可以得到G为:
这一步相当于针对不同权重的样本训练分类器,且每个弱学习器只需保证自身误差损失最小即可。现在来看α,对前面的损失函数求α导数并令其为0:
由1.1.1中定义和定义可知如下结果:

即仅仅是比
多了一个规范化因子的分母
而已。也就是说,
是
规范化后的表达式,可以得到
,即损失越大(分类错误)的样本权重越高。同时,第二个式子也印证了1.1.1中提到的权重更新方法。确切的说权值代表了这个样本在当前轮迭代之前被误分类的次数度量,被误分类的次数越多,权值就越大,在当前轮就会越被重视。如何被重视呢?这里采用的就是用的权值乘以损失函数,分类错误的样本损失更大。因为我们的目标是极小化损失函数,这样做自然对大权值的样本误分类的惩罚高。
根据1.1.1中定义的错误率计算公式可知:
则前面对α的求导结果可以得出:
1.1.4 SAMME.R算法
在Adaboost中有两种分类算法,一种是SAMME算法,基于分类错误率的,即用对样本集分类效果作为弱学习器权重(参考α的计算方法),然后根据α计算样本权重,前面介绍的算法原理就是SAMME算法,对于多分类问题,SAMME算法原理和二分类类似,最主要区别在弱分类器的系数上。SAMME算法的弱分类器的权重系数为:
其中R为类别数。从上式可以看出,如果是二分类,R=2,则上式和我们的二分类算法中的弱分类器的系数一致。
在Adaboost中还有另外一种分类算法,叫做SAMME.R,和SAMME不同,SAMME.R是基于样本集分类的预测概率大小来计算弱学习器样本权重的。对于第k个弱学习器,可以获得任意样本带有权重的分类评估概率:
其中表示第 i 个样本
在第 k 个弱学习器上识别为类别 r 的概率,R表示分类的类别数。令:
则最终构建的强分类器为:
由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,而且通过较少的boosting迭代实现更低的测试误差,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器,即在sklearn中有predict_proba属性方法,SAMME算法则没有这个限制。另外需要注意的是,因为SAMME.R是根据预测概率来计算结果,因此每个弱学习器的权重都是1。
1.1.5 正则化项
从Adaboost的原理可知,在弱学习器数量足够多的情况下,它对样本的拟合能力是很强的,这就导致它对异常值(噪音)会出现过拟合,为了防止Adaboost过拟合,我们通常也会加入正则化项。这个正则化项我们通常称为步长(learning rate),定义为ν。对前面弱学习器的迭代过程:
加入正则化项:
ν的取值范围为0<ν≤10<ν≤1。对于同样的训练集,较小的ν意味着我们需要更多的弱学习器的迭代次数,换句话说就是削弱弱学习器的作用。通常我们用步长和弱学习器数一起来决定算法的拟合效果。
1.1.6 实践
在sklearn中的Adaboost分类API类定义如下:
class sklearn.ensemble.AdaBoostClassifier(
base_estimator=None, ##弱学习器,默认None表示DecisionTreeClassifier(max_depth=1)
*,
n_estimators=50, ##弱学习器数量
learning_rate=1.0, ##学习率,上文提到的正则化项系数 v
algorithm='SAMME.R', ##算法参数,可选‘SAMME’, ‘SAMME.R’
random_state=None)AdaBoost算法最成功的应用之一是机器视觉里的目标检测问题,如人脸检测和行人检测。车辆检测。在深度卷积神经网络用于此问题之前,AdaBoost算法在视觉目标检测领域的实际应用上一直处于主导地位,详情可参考资料[6]。在传统业务领域,目前使用较多的多为GBDT、Xgboost等算法,Adaboost的使用并不是很多。
这里有一个sklearn官方提供的Adaboost在SAMME和SAMME.R算法上的测试效果比对案例,可以发现SAMME.R在更低的学习率情况下,损失下降反而更快,且测试效果表现也更好。同时,sklearn官方也提供了一个不同模型的对比测试案例,可以看一下比对效果。
1.2 回归问题
Adaboost在回归问题上的计算方法和分类问题略有不同,在最终的组合策略也不一样。
1.2.1 原理
Adaboost回归权重计算过程如下:
(1)误差计算:对于第k个弱学习器,计算他在训练集上的最大误差为
每个样本的相对误差为:,实则是做了归一化处理。这是误差损失为线性时的情况。
如果我们用平方误差,则
也可以用指数误差,
则第k个弱学习器的加权误差率为:
(2)弱学习器权重系数α计算:,
(3)样本权重更新公式为:,
为规范化因子:
,这里也需要注意误差率大的样本权重并不是变小了,因为
是小于1的,所以以
为底数的指数函数是减函数
(4)组合策略:取所有弱学习器预测结果的中位数,注意这里不同于分类问题的加权和方式。其实这里的组合方式并不唯一,网上也有很多资料在这一步介绍的是弱学习器权重的中位数,也有是弱学习器结果的加权和,每种方法都有理论依据,这里选择了sklearn中的处理方法介绍说明,具体信息可参考1.2.3节组合策略测试。
1.2.2 正则化项
在回归问题中也有正则化项处理步骤,主要体现在弱学习器权重更新程度和样本权重更新上,具体可以看1.2.3节中的源码部分。
1.2.3 实践
- API类
Adaboost回归API类的定义如下:
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, *, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)loss参数就是1.2.1提到的损失计算方法,可取‘linear’, ‘square’, ‘exponential’,分别表示线性误差、平方误差、指数误差,默认是线性误差,一般取线性误差即可。
- 源码介绍
这里再解释一下1.2.1中提到的取中位数处理,sklearn中的源码如下:
##计算弱学习器权重
beta = estimator_error / (1. - estimator_error)
# Boost weight using AdaBoost.R2 alg
estimator_weight = self.learning_rate * np.log(1. / beta)
##样本权重
if not iboost == self.n_estimators - 1:
sample_weight *= np.power(
beta,
(1. - error_vect) * self.learning_rate)
##中位数输出
def _get_median_predict(self, X, limit):
# Evaluate predictions of all estimators
predictions = np.array([
est.predict(X) for est in self.estimators_[:limit]]).T
# Sort the predictions
sorted_idx = np.argsort(predictions, axis=1)
# Find index of median prediction for each sample
weight_cdf = stable_cumsum(self.estimator_weights_[sorted_idx], axis=1)
median_or_above = weight_cdf >= 0.5 * weight_cdf[:, -1][:, np.newaxis]
median_idx = median_or_above.argmax(axis=1)
median_estimators = sorted_idx[np.arange(_num_samples(X)), median_idx]
# Return median predictions
return predictions[np.arange(_num_samples(X)), median_estimators]- 组合策略测试
这里返回的实则是所有弱学习器预测结果的中位数值,并不是弱学习器的加权和值。另外,最终的输出结果是弱学习器预测结果的中位数,并不是权重的中位数,测试案例如下:
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, n_informative=2,random_state=0, shuffle=False)
regr = AdaBoostRegressor(random_state=0, n_estimators=5)
regr.fit(X, y)
regr.estimator_weights_
##array([0.94082322, 1.18300521, 0.69304211, 0.78291407, 0.99175517])
regr.predict([[0, 0, 0, 0]])
##array([6.80445787])
for clf in regr.estimators_:
print(clf.predict([[0, 0, 0, 0]]))
[11.31024929]
[-24.48414636]
[7.66690353]
[6.80445787]
[-14.82559432]- 实践案例
下面是一个使用Adaboost和决策树作为回归模型的对比案例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
# Create the dataset
rng = np.random.RandomState(1)
X = np.linspace(0, 6, 100)[:, np.newaxis]
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=4)
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),
n_estimators=300, random_state=rng)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
y_1 = regr_1.predict(X)
y_2 = regr_2.predict(X)
# Plot the results
plt.figure()
plt.scatter(X, y, c="k", label="training samples")
plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2)
plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Boosted Decision Tree Regression")
plt.legend()
plt.show()
三、GBDT
如果说Adaboost在实际任务中用的不多的话,那么GBDT就是一个很普遍应用的算法了,而实践也证明GBDT在很多业务场景中都取得了不凡的效果。在介绍GBDT的原理之前,我们先来回顾一下梯度下降的内容,理解了梯度下降的原理,那么再去理解GBDT就更加容易了,其实GBDT的G也正是梯度的意思。
3.1 梯度下降
梯度下降(Gradient Descent)是求解损失最小化最常用的优化算法之一,不管是在机器学习领域,还是深度学习领域,梯度下降都是大名鼎鼎的存在。这里我们主要以案例形式简单介绍其原理。
假设已知损失函数为:L(θ) = min f(θ) = ,这里简单处理不考虑输入输出变量,实际上原理一样。现需找到一个最合适的θ,使得 f(θ) 最小。暴力的解法是找极值点,但是实际的损失函数一般很复杂,直接求解的难度很大,所以一般都是通过梯度下降法逐渐逼近最优值。主要步骤如下:
- 随机选取一个初始值
(假设为 -10)和学习步长(学习率)r (假设为0.1)
- 求解在选取点的梯度值,因为沿着梯度的方向下降最快:
,则
- 根据步长r更新θ:
,这里之所以写
,是考虑到存在学习率衰减的情况,如果学习率不变,则这里的
- 重复上述步骤,可以逼近最优的
可以看出,对于最终的最优解,是由初始值
经过K次的迭代之后得到的,在这里,设
,
,则
。

3.2 函数空间最优解
在3.1节介绍了基于变量的梯度下降过程,现在我们介绍上升到函数空间的梯度下降过程。根据前面梯度下降算法思路,对于模型的损失函数L(y,F(X)),求解最优的函数F∗(X),使得损失最小。
首先,设置初始值为:,可以认为是随机选取的初始值,则经过K轮迭代后得到的最优F*(X)为:
假设
之所以以平方函数为例,因为在回归问题中对于连续值的损失函数常是平方误差,所以这里直接使用平方函数介绍。
则:
所以
其中
即L在F(X)上的梯度正是样本目标y和学习器预测值F(X)之间的残差,而GBDT的原理也正是通过后面的第k个弱学习器不断地学习前面强学习器
和实际值之间残差的过程。
3.3 GBDT原理
不同于Adaboost通过调高识别错误样本的权重,从而来不断纠正被学习错误的样本,GBDT(Gradient Boosting Decision Tree)是通过不断学习前 k-1 个弱学习器组成的强学习器学习的残差(梯度提升),从而来弥补错误(区别于纠正)。这里可以发现Adaboost和GBDT一个很大的不同点,Adaboost每一个弱学习器学习的样本标签是一样的,即假如某个样本的目标值(标签)是1,则每个弱学习训练过程的Y都是1,而GBDT每个弱学习器训练过程的Y却是不同的,学习的都是残差。
举个通俗理解的例子:假如有个人30岁,第一棵树(弱学习器)学习拟合后的值是20岁,残差是10岁,第二棵树去学习10这个目标(不再是30),假如拟合的结果是8,残差是2,则第三棵树继续学习拟合2,依次进行下去。每一轮迭代,拟合的岁数误差都会减小,最后的拟合结果就是每个弱学习器的输出和。这里需要注意的一点是,GBDT的弱学习器都是CART回归树,即使是分类问题,因为GBDT学习的梯度值(连续值)。算法流程如下:
(1)初始化弱学习器
M是样本数,
(2)对每个样本计算负梯度,即:
在CART回归树中,实则就是 y-c,c是每个叶子节点样本标签的平均值(具体原理可参考决策树那篇文章)
(3)将(2)中的残差作为样本新的目标值,并将 , m = 1,2,3,...,M 作为下一课树的训练数据
(4)基于(3)中新的训练数据,训练得到新的弱学习器 ,则新的强学习为:
(5)依次重复(2)、(3)、(4)步,直到达到指定的弱学习器个数或者满足最低误差要求,最终的强学习器为:
3.3.1 正则化项
和Adaboost一样,GBDT中也有正则化项,也就是我们在3.1和3.2节中提到的学习率步长r,这里我们和Adaboost保持统一,也使用v表示,则最终的GBDT表达形式为:
除了上面提到的正则化方法外,GBDT还有另外一种通过控制采样方法进行正则化,和随机森林类似,但是GBDT是不放回采样,在介绍API类参数时会再介绍。
3.3.2 一般式的GBDT
前面我们介绍了GBDT的原理,也提到了每个弱学习器是不断拟合残差的过程,之所以这么介绍,是因为很多人对GBDT的感性认识就是残差。但是残差成立的条件是损失函数为平方误差函数,如果损失函数不是平方误差,例如对数或者指数函数,那么显然 就不再是残差,所以GBDT弱学习器学习的目标实质是损失函数的负梯度,只是当损失函数为平方误差时,负梯度刚好等于残差了,这才能解释为何换了损失函数后,即使弱学习器拟合的不再是残差(在下文分类问题中对数损失的偏导就不再是残差),但是组合后依然可以得到一个表达很好的强学习器原因。也就说GBDT是拟合残差的说法是不对的,至少是很局限的。
理解上面这段话对于理解GBDT的原理很重要,那么为何不断地拟合负梯度就可以得到一个表达很好的模型呢?这就要回到梯度下降的问题了,因为沿着负梯度的方向损失下降是最快的,或者说训练迭代效率是最好的。当损失最小时,那么对应的F(X)自然就是最优的。其实还可以从泰勒展开多项式来理解为何通过拟合一阶导就可以达到效果,对于泰勒多项式,如果足够小,则:
即忽略二阶及其更高阶导部分,在后面介绍xgboost的时候,会介绍xgboost其实是取了一阶和二阶导,忽略更高阶导的过程。因为泰勒多项式是加法形式,所以最终所有弱学习器的组合策略是相加。现在我们来重新梳理一般形式下的GBDT过程:
(1)初始化弱学习器
(2)对第t轮(第t棵CART树)的第i个样本,求损失函数的负梯度
(3)利用 (),i=1,2,..m,拟合一颗新的CART回归树,得到了第t颗回归树,其对应的叶节点区域
, j=1,2,...,J,其中J为叶子节点的个数。
(4)针对每一个叶子节点里的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的的输出值:
这里需要注意的是,并不一定是叶子节点上所有样本的均值,因为均值只是使得CART树的损失最小,并不一定使得全局损失函数最小。
(5)则本轮得到的弱学习器CART树就为
本轮得到的强学习器为:
(6)最终的强学习器为:
通过拟合损失函数的负梯度,我们找到了一种通用的拟合损失误差的办法,这样无轮是分类问题还是回归问题,我们通过其损失函数的负梯度的拟合,就可以用GBDT来解决我们的分类回归问题。区别仅仅在于损失函数不同导致的负梯度不同而已。
3.4 分类问题
前面提到GBDT使用的弱学习器是CART回归树,即使是分类问题,但是因为类别直接加减是没有意义的,使用平方损失计算负梯度就没有意义,但是可以拟合分类类别的概率值,因为概率是连续值。但是对于多分类问题怎么得到每个类别的概率呢?结合我们深度学习处理多分类的经验,可以通过输出和类别数一样多的值,再通过softmax求概率。因此,在GBDT中,对于有k个类别的分类任务(k>2),如果迭代m次,则共有 k*m个CART树。对于二分类问题,只要知道其中一个类别的概率,自然就知道另一个类别的概率了。
到这里,我们知道了GBDT目标是拟合概率值,但是并不是直接去拟合概率值,还是去拟合类别标识 。如果模型在类别1上的强学习器输出值比在其他类别上的强学习器输出大很多,那结果自然就是该类别,例如在类别1和2上的输出分别是7和-0.5,这也是我们更希望看到的,因为差别越大,表示分类效果越好,所以下文实践部分我们会看到所有弱学习器的输出和会大于1或者小于-1很多,这都是正常的。这也从另一方面解释了为何在分类问题中我们选择对数似然损失函数,而不是平方损失函数。
为了解决损失计算问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。因为如果采用指数函数,那么Adaboost每一步就在拟合指数损失的梯度,根据在Adaboost部分介绍的指数损失函数的表达形式,也就是第t轮要学习的训练样本是,则全局损失为:
就回到了1.1.3(3)中的Adaboost的损失形式。
3.4.1 二分类
对于二元GBDT,采用了类似于逻辑回归的对数似然损失函数,参见1.1.3(2)中的对数损失形式,则损失函数为:
,其中
则此时的负梯度误差为:
对于生成的决策树,我们各个叶子节点的最佳负梯度拟合值为:
由于上式比较难优化,我们一般使用近似值代替:
除了负梯度计算和叶子节点的最佳负梯度拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同,而两者区别的根本原因其实都是由于损失函数不同导致的。关于上式 的近似计算证明,可以参考原论文。这里再说一下损失函数
,可以发现
是一个单调递减函数,所以当 y 和 f(x)同符号时,|f(x)| 值越大,损失就越小,当y 和 f(x)异号时,损失最大。
3.4.2 对数似然损失函数
为了更好地理解多分类下的损失函数表达形式,我们再简单介绍下对数似然函数。对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是根据概率估计定义的。它常用于(multi-nominal, 多项)逻辑斯谛回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出。最大似然估计的原理是:找到一组估计值,使得未知参数取该组估计值时,观察值以最大概率出现。说人话就是,已知样本分布模型,但是不知道模型的参数,现在我有N个观测样本,既然这N个样本被选中了,那我就认为这N个样本被选中的概率最大,因此只要求得使得N个样本出现概率最大的模型参数即可。保证所有样本概率最大的方法就是所有样本概率的乘积最大,但是一般累积不容易计算,因此取对数处理,变为累加,为了转化为最小损失问题,在前面加负号处理。
对数损失通过惩罚错误的分类,实现对分类器的准确度(Accuracy)的量化.。最小化对数损失基本等价于最大化分类器的准确度。为了计算对数损失, 分类器必须提供对输入的所属的每个类别的概率值,不只是最可能的类别.。对数损失函数的计算公式如下:
![]()
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为可能的类别数, 是一个二值指标, 表示类别 j 是否是输入实例
的真实类别。
为模型或分类器预测输入实例
属于类别 j 的概率。如果只有两类 {0, 1}, 则对数损失函数的公式简化为:

这时, 为输入实例
的真实类别,
为预测输入实例
属于类别 1 的概率。 对所有样本的对数损失表示对每个样本的对数损失的平均值, 对于完美的分类器,对数损失为 0。
3.4.3 多分类
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假设类别数为K,根据3.4.2节的对数似然损失函数表达形式,则此时我们的对数似然损失函数为:
其中如果样本输出类别为k,则 。第k类的概率
的表达式为:
集合上两式,我们可以计算出第 t 轮的第 i 个样本对应类别 的负梯度误差为:
关于上式的推导过程如下:
则
即:当弱学习器所在类别是x真实类别时,y = 1,则:
当弱学习器所在类别不是x真实类别时,y = 0,则:
可以发现,在多分类模型中,对数似然损失函数的拟合目标就是样本 i 对应类别 的真实概率和 t−1 轮预测概率的差值。
对于生成的CART树,我们各个叶子节点的最佳负梯度拟合值为:
由于上式比较难优化,我们一般使用近似值代替:
3.5 损失函数
通过前面的介绍可以发现,在GBDT中回归、二分类、多分类的不同根本是损失函数的不同,这里我们在列举一些常用的损失函数。
(1)指数损失函数,损失函数表达式为:
可参考文章Adaboost和3.4节开头部分内容。
(2)对数损失函数,分为二元分类和多元分类两种,可参考3.4.1和3.4.3节。
(3)均方误差损失,最常见的回归损失函数:
可参考3.3节。
(4)绝对损失:
绝对损失因为计算方面,求导简单,也很常见。绝对损失对应负梯度误差为:。
(5)Huber损失,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
对应的负梯度误差为:
之所以使用Huber损失,因为平方误差有个特性,就是当 y 与 f(x) 的差值大于 1 时,会增大其误差;当 y 与 f(x) 的差值小于 1 时,会减小其误差,这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(<1)的情况给予更小的惩罚。从训练的角度来看,模型会更加偏向于惩罚较大的点,赋予其更大的权重。如果样本中存在离群点,MSE 会给离群点赋予更高的权重,但是却是以牺牲其他正常数据点的预测效果为代价,这最终会降低模型的整体性能,而Huber损失可以在一定程度上避免这种情况。若发现模型在异常点上表现出过拟合现象,可以尝试使用Huber损失。
(6)分位数损失,它对应的是分位数回归损失函数,可用于判断预测区间,表达式为:
其中θ为分位数,需要我们在回归前指定。对应的负梯度误差为:
一般情况下,在建模之前,我们使用默认的损失函数即可,如果发现效果不理想,或者需要调优,再考虑更换损失函数。
四、总结
4.1 Boosting和Bagging的不同
(1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,每轮数据集的抽取是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
(2)样本权重:
Bagging:使用均匀取样,每个样本的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
(3)组合权重:
Bagging:所有基学习器的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器在决定最终输出结果时会有更大的权重。
(4)并行计算:
Bagging:各个基学习器可以并行生成
Boosting:各个弱学习器只能顺序生成,因为后一个弱学习器的样本权重需要依赖前一个弱学习器的结果。
(5)基学习器选择:
Bagging:基学习器一般选择强学习器,因为Bagging的最终结果是由所有弱学习器投票决定的,因此需要每个基学习器都要很强。
Boosting:基学习器一般选择弱学习器,因为如果选择强学习器,那么误分类的样本就会很少,要知道Adaboost后面的弱学习器是基于前面弱学习器的分类误差情况来调整的,如果前面的误分类样本少,后面的弱学习器可以调整权重的样本就不多,那么再建立一个弱学习器和前面的弱学习器区别就会很小,这样会导致Adaboost提前终止。另外,基学习器如果精度太高,后续的弱分类器基本一样,还有可能导致过拟合,因此单个弱学习器的精度不用太高。算法精度由整体保证即可。
4.2 其他Boosting算法
Boosting家族除了Adaboost和GBDT外,还有两个比较经典的算法:Xgboost和LightGBM,后续会在其他文章中单独介绍。另外,从scikit-learn 0.21开始,sklearn新增了GBDT的升级版本,HistGradientBoostingClassifier 和 HistGradientBoostingRegressor,其速度相对于GBDT快了一个量级,并且支持缺失值数据训练。因为这两个API也是借鉴了LightGBM的思想,因此放在Xgboost和LightGBM一起介绍。
五、实践
本章我们同样以sklearn 0.23.2为例,介绍GBDT的使用。
5.1 API
GBDT分类API定义如下:
class sklearn.ensemble.GradientBoostingClassifier(*,
loss='deviance', ##可选‘deviance’ 和 ‘exponential’,分别表示对数和指数损失
learning_rate=0.1, ##学习率正则项
n_estimators=100,
subsample=1.0, ##子采样,取值为(0,1],表示采样百分比。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。
criterion='friedman_mse',
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
min_impurity_split=None,
init=None, ##初始化的时候的弱学习器,即f0
random_state=None,
max_features=None,
verbose=0,
max_leaf_nodes=None,
warm_start=False,
presort='deprecated',
validation_fraction=0.1, ##验证集比例,只有n_iter_no_change被设置时有效
n_iter_no_change=None, ##当最近n_iter_no_change次迭代,validation_fraction划分的验证集score都没有提高时,停止迭代,默认不设置
tol=0.0001, ##当对于n_iter_no_change迭代,损失没有得到至少tol的改善时,训练停止。
ccp_alpha=0.0)设置合理的子采样和验证集可以加快训练效率,且可以使用更少的弱学习器,可参考sklearn官网案例。其他CART树的参数,可参考决策树篇文章。
GBDT回归API定义如下:
sklearn.ensemble.GradientBoostingRegressor(*,
loss='ls', ##默认是平方误差损失,可选‘ls’, ‘lad’, ‘huber’, ‘quantile’
learning_rate=0.1,
n_estimators=100,
subsample=1.0,
criterion='friedman_mse',
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_depth=3,
min_impurity_decrease=0.0,
min_impurity_split=None,
init=None, ##初始学习器f0,默认使用DummyEstimator,即所有样本的均值,可选 ‘zero’或者其他弱学习器
random_state=None,
max_features=None,
alpha=0.9, ##huber损失函数和分位数损失函数的alpha-分位数
verbose=0,
max_leaf_nodes=None,
warm_start=False,
presort='deprecated',
validation_fraction=0.1,
n_iter_no_change=None,
tol=0.0001,
ccp_alpha=0.0)5.2 案例
(1)验证二分类结果
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
max_depth=1, random_state=0).fit(X_train, y_train)
a0 = clf.init_.predict(X_train[:100,:])
print(a0)
for i in range(100):
a1 = clf.estimators_[i][0].predict(X_train[:100,:])
a0 = a1+a0
print(a0)可以发现最后的a0会出现很多大于1或者小于-1的结果。
(2)多个集成算法投票
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import VotingRegressor
X, y = load_diabetes(return_X_y=True)
# Train classifiers
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
reg1.fit(X, y)
reg2.fit(X, y)
reg3.fit(X, y)
ereg = VotingRegressor([('gb', reg1), ('rf', reg2), ('lr', reg3)])
ereg.fit(X, y)
xt = X[:20]
pred1 = reg1.predict(xt)
pred2 = reg2.predict(xt)
pred3 = reg3.predict(xt)
pred4 = ereg.predict(xt)
plt.plot(pred1, 'gd', label='GradientBoostingRegressor')
plt.plot(pred2, 'b^', label='RandomForestRegressor')
plt.plot(pred3, 'ys', label='LinearRegression')
plt.plot(pred4, 'r*', ms=10, label='VotingRegressor')
plt.tick_params(axis='x', which='both', bottom=False, top=False,
labelbottom=False)
plt.ylabel('predicted')
plt.xlabel('training samples')
plt.legend(loc="best")
plt.title('Regressor predictions and their average')
plt.show()更多案例可以参考sklearn官网。
(3)调参
GBDT调参过程同样可以通过GridSearchCV完成,具体案例可参考文献[10]的介绍。注意learning_rate和n_estimators是一对矛盾参数,一般调参需要综合两者效果,也可通过early stopping确定n_estimators大小。这里提一下,sklearn官网介绍了,CART树的参数max_leaf_nodes=k的结果与max_depth=k-1的结果相当,但是训练速度明显更快,代价是训练误差稍高一些,在实际调参中可以作为参考。
参考文献
[1] https://blog.csdn.net/zwqjoy/article/details/80424783
[2] https://pan.baidu.com/s/1hqePkdY
[3] https://www.cnblogs.com/pinard/p/6136914.html
[4] https://blog.csdn.net/v_july_v/article/details/40718799
[5] http://www.52caml.com/head_first_ml/ml-chapter6-boosting-family/
[6] https://zhuanlan.zhihu.com/p/43443518
[7] https://blog.csdn.net/Dby_freedom/article/details/81990279
[8] https://www.cnblogs.com/klchang/p/9217551.html














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









