









参考
目录
1.前言
AdaBoost是典型的Boosting算法。在说AdaBoost之前,先说说Boosting提升算法。Boosting算法要涉及到两个部分,加法模型和前向分步算法。加法模型就是说强分类器由一系列弱分类器线性相加而成,如下:
其中,![]() 就是一个个的弱分类器,
就是一个个的弱分类器,![]() 是弱分类器学习到的最优参数,βm就是弱学习在强分类器中所占比重,P是所有
是弱分类器学习到的最优参数,βm就是弱学习在强分类器中所占比重,P是所有![]() 和βm的组合。这些弱分类器线性相加组成强分类器。
和βm的组合。这些弱分类器线性相加组成强分类器。
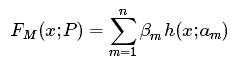
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
![]()
由于采用的损失函数不同,Boosting算法也因此有了不同的类型,AdaBoost就是损失函数为指数损失的Boosting算法。
2.AdaBoost算法
2.1 基本原理
AdaBoost是典型的Boosting算法,其基本原理是不断迭代训练弱分类器,提高那些被前一轮弱分类器错误分类样本的权值,降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据在后一轮训练中会获得更大关注,最后将多个弱分类器按照一定的权重组合起来形成强分类器。(分类问题就被一系列的弱分类器“分而治之”。),表达式如下:
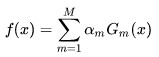
是第m个弱分类器,
是相应的权值。
基于Boosting的理解,对于AdaBoost,我们要搞清楚两点:
- 每一次迭代的弱学习
有何不一样,如何学习?
- 弱分类器权值
如何确定?
对于第一个问题,AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是提高那些被前一轮弱分类器错误分类样本的权值,降低那些被正确分类样本的权值。从而使那些没有得到正确分类的数据在后一轮训练中会获得更大关注。
对于第二个问题,AdaBoost采用加权多数表决的方法,加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。这个很好理解,正确率高分得好的弱分类器在强分类器中当然应该有较大的发言。
2.2 算法流程
给定训练数据集,![]() ,其中
,其中![]() 。
。
(1)初始化训练样本的权值分布:![]() ,
,![]()
(2)对于m=1,2,…,M(m表示当前的迭代轮数,共有M次迭代):
- 使用具有权值分布
的训练数据集进行学习,得到弱分类器
- 计算
:
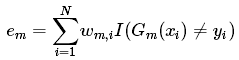
代表第
个样本。
是样本权重。
为指示函数,取值为1或0。当指示函数
括号中的表达式为真时,即当前的弱分类器能将样本错误分类时,
函数结果为1;当指示函数
括号中的表达式为假时,即当前的弱分类器能将样本正确分类时,
函数结果为0。也就是说上式是将错误分类的样本的权重全部都加起来。最后,取错误率最低的弱分类器为当前迭代的最优弱分类器。
- 计算弱分类器

可以看出,错误率越小,则 alpha 值越大,即该弱分类器的权重越高;反之,错误率越大,则 alpha 值越小,则该弱分类器的权重越小。这样可以使分类精度高的弱分类器起到更大的作用,并削弱精度低的弱分类器的作用。
- 更新训练数据集的权值分布,用于下一轮(m+1)迭代:
![]()
其中为规范化因子,计算公式如下。目的是使得新的样本权值成为一个概率分布(和为1)。
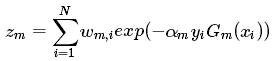
是前面计算的弱分类器的权重。当样本分类错误时,y 和 Gm 取值不一致,
![]() 大于0,
大于0,![]() 大于1,则新样本权重变大;当样本分类正确时,y 和 Gm 取值一致,
大于1,则新样本权重变大;当样本分类正确时,y 和 Gm 取值一致,![]() 小于0,
小于0,![]() 小于1,则新样本权重变小。这样处理,可以使被错误分类的样本权重变大,从而在下一轮迭代中得到重视。
小于1,则新样本权重变小。这样处理,可以使被错误分类的样本权重变大,从而在下一轮迭代中得到重视。
(3)得到最终分类器。
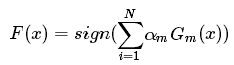
2.3 步骤概览
① 初始化训练样本的权值分布,每个训练样本的权值应该相等(如果一共有N个样本,则每个样本的权值为1/N)
② 依次构造训练集并训练弱分类器
③ 计算在训练数据集上的分类误差率
:
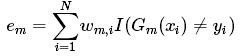
④ 计算弱分类器在最终分类器中的系数(即所占权重):
⑤ 更新训练数据集的权值分布,用于下一轮(m+1)迭代:
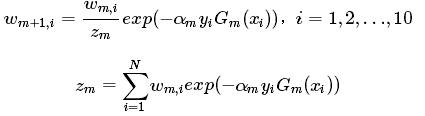
⑥更新模型:
![]()
|
| 第一轮迭代 | 第二轮迭代 | 第m轮迭代 |
| 样本权重 | | | |
| 弱分类器 | | ||
| 分类误差 | | ||
| 分类器权重 | | | |
| 模型更新 | | | |
| 样本权重更新 | 得到 | 得到 | 得到 |
3.公式推导
3.1 和的推导
假设已经经过m−1轮迭代,得到,根据前向分步,我们可以得到:
![]()
我们已经知道AdaBoost是采用指数损失,由此可以得到损失函数:
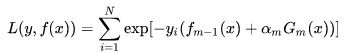
把指数加法因子展开,变成指数的乘积(想一下具体的例子:![]() )得到:
)得到:
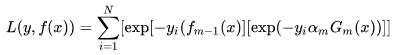
由于和
已知, 可以令
![]() ,于是有:
,于是有:

PS:adaboost是在给定训练数据及损失函数
的条件下,学习加法模型
,优化目标是经验风险极小化,即损失函数极小化问题:
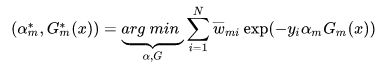
继续地,当样本预测正确有![]() 大于0,预测错误有
大于0,预测错误有![]() 小于0,因此上式子可变为:
小于0,因此上式子可变为:
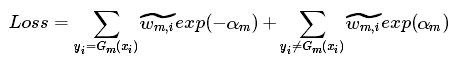
可再进一步变为:
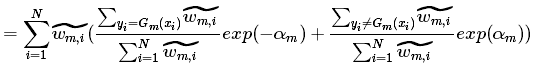
我们令 =
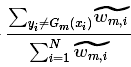 ,由于
,由于,因此
就是分类错误的样本权值和,即
的由来。同时也易得
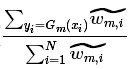 =
= ,因此有:
之后对求偏倒,令
![]() ,有:
,有:

这就是计算公式的由来。
3.2 权值更新公式推导
在3.1的推导中,我们令![]() ,于是有:
,于是有:
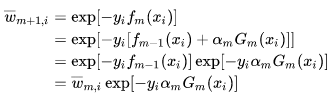
相关面试题
(1)简述一下 Adaboost 的权值更新方法。
答:参考上面的算法介绍。
(2)训练过程中,每轮训练一直存在分类错误的问题,整个Adaboost却能快速收敛,为何?
答:每轮训练结束后,AdaBoost 会对样本的权重进行调整,调整的结果是越到后面被错误分类的样本权重会越高。而后面的分类器为了达到较低的带权分类误差,会把样本权重高的样本分类正确。这样造成的结果是,虽然每个弱分类器可能都有分错的样本,然而整个 AdaBoost 却能保证对每个样本进行正确分类,从而实现快速收敛。
(3) Adaboost 的优缺点?
答:优点:能够基于泛化性能相当弱的的学习器构建出很强的集成,不容易发生过拟合。
缺点:对异常样本比较敏感,异常样本在迭代过程中会获得较高的权值,影响最终学习器的性能表现。
(4)AdaBoost 与 GBDT 对比有什么不同?
答:区别在于两者boosting的策略:Adaboost通过不断修改权重、不断加入弱分类器进行boosting;GBDT通过不断在负梯度方向上加入新的树进行boosting。
(4)AdaBoost 与随机森林的区别?
- 随机森林是bagging算法,训练出的模型更偏向与降低方差;Adaboost是boosting算法,训练出的模型更偏向于降低偏差;
- 随机森林每一轮训练中样本的权重是不变的;而Adaboost在训练中会提升分类错误的样本的权重,降低分类正确的样本的权重;
- 随机森林每一个基学习器的权重是不变的;而Adaboost中加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。
- 随机森林可以并行训练,提升训练效率;Adaboost只能串行训练,因为后一轮的迭代依赖前一轮迭代的结果。
- 随机森林在样本样本扰动的基础上进一步增加了特征扰动,泛化能力更强,对异常数据不敏感。Adaboost在训练中会提升分类错误的样本的权重,因此异常点的权重往往相对较高,对模型训练影响很大。















 1668
1668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









