






1、什么是无监督学习?
顾名思义,无监督学习是一种机器学习技术,其中模型不使用训练数据集进行监督。相反,模型本身会从给定数据中找到隐藏的模式和见解。它可以比作在学习新事物时发生在人脑中的学习。它可以定义为:
监督学习是一种机器学习,其中模型使用未标记的数据集进行训练,并允许在没有任何监督的情况下对该数据进行操作。
无监督学习不能直接应用于回归或分类问题,因为与监督学习不同,我们有输入数据但没有相应的输出数据。无监督学习的目标是找到数据集的底层结构,根据相似性对数据进行分组,并以压缩格式表示该数据集。
2、无监督学习的工作原理
下图可以理解无监督学习的工作原理: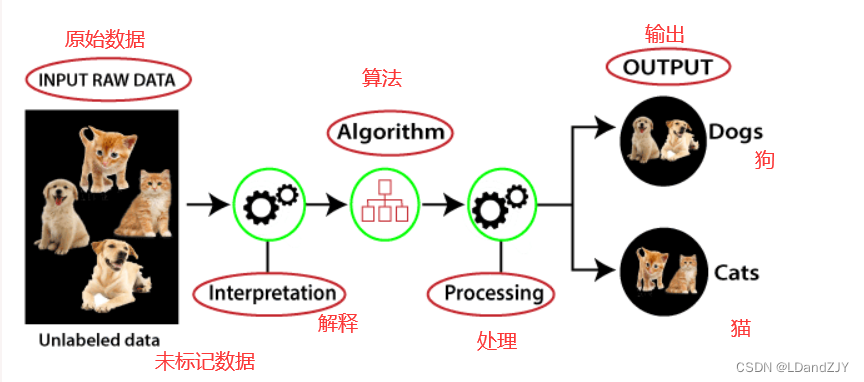
在这里,我们采用了未标记的输入数据,这意味着它没有分类,也没有给出相应的输出。现在,这些未标记的输入数据被输入机器学习模型以对其进行训练。首先,它将解释原始数据以从数据中找到隐藏的模式,然后应用合适的算法,如 k-means 聚类、决策树等。
一旦应用了合适的算法,该算法就会根据对象之间的相似性和差异性将数据对象分组。
3、无监督学习算法的类型
无监督学习算法可以进一步分为两类问题:聚类和关联
1、聚类
聚类一般使用的是sklearn库,常用的聚类算法函数都在这个sklearn.cluster这个模块中,根据各种算法的特点,得到分类的结果以及耗费的时间也是不同的,这是由算法的特性决定的。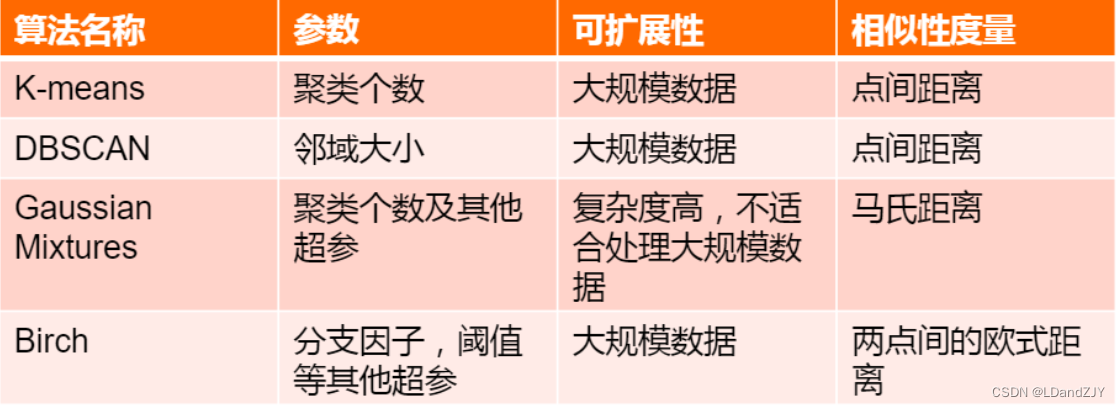
聚类:聚类是一种将对象分组为聚类的方法,使得具有最多相似性的对象保留在一个组中,并且与另一组的对象具有较少或没有相似性。聚类分析发现数据对象之间的共性,并根据这些共性的存在和不存在对它们进行分类。
2、关联
将原数据中用处不大或者没有用处的部分去掉,从而简化数据,让数据在判断的过程中少进行一些操作。同聚类一样,由于我们使用的是Python的库文件,所以不需要去了解降维算法的具体原理,这个是机器学习的内容而不是机器学习应用的内容,我们需要的是会用给定的库文件。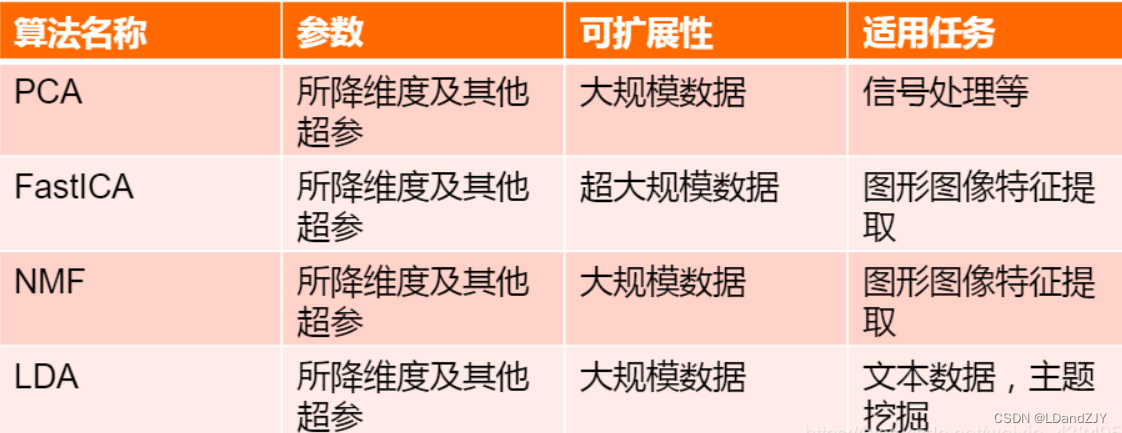
关联:关联规则是一种无监督学习方法,用于查找大型数据库中变量之间的关系。它确定在数据集中一起出现的项目集。关联规则使营销策略更加有效。例如购买 X 商品(假设是面包)的人也倾向于购买 Y(黄油/果酱)商品。关联规则的一个典型例子是市场篮子分析。
4、无监督学习算法
- K-means 聚类
- KNN(k-最近邻)
- 层次聚类
- 异常检测
- 神经网络
- 主成分分析
- 独立成分分析
- 先验算法
- 奇异值分解
5、无监督学习的优势
- 与监督学习相比,无监督学习用于更复杂的任务,因为在无监督学习中,我们没有标记的输入数据。
- 无监督学习更可取,因为与标记数据相比,它更容易获得未标记数据。
6、无监督学习的缺点
- 无监督学习本质上比监督学习更难,因为它没有相应的输出。
- 无监督学习算法的结果可能不太准确,因为输入数据没有标记,并且算法事先不知道确切的输出。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









