






1、监督学习的概念
监督学习是机器学习的类型,其中机器使用“标记好”的训练数据进行训练,并基于该数据,机器预测输出。标记的数据意味着一些输入数据已经用正确的输出标记。
在监督学习中,提供给机器的训练数据充当监督者,教导机器正确预测输出。它应用了与学生在老师的监督下学习相同的概念。
监督学习是向机器学习模型提供输入数据和正确输出数据的过程。监督学习算法的目的是找到一个映射函数来映射输入变量(x)和输出变量(y)。
在现实世界中,监督学习可用于风险评估、图像分类、欺诈检测、垃圾邮件过滤等
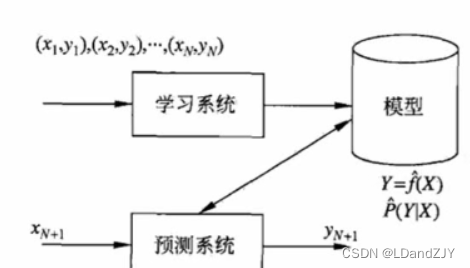
2、监督学习如何运作
监督学习中,模型使用标记数据集进行训练,其中模型学习每种类型的数据。训练过程完成后,模型会根据测试数据(训练集的子集)进行测试,然后预测输出。
通过以下示例和图表可以很容易地理解监督学习的工作原理: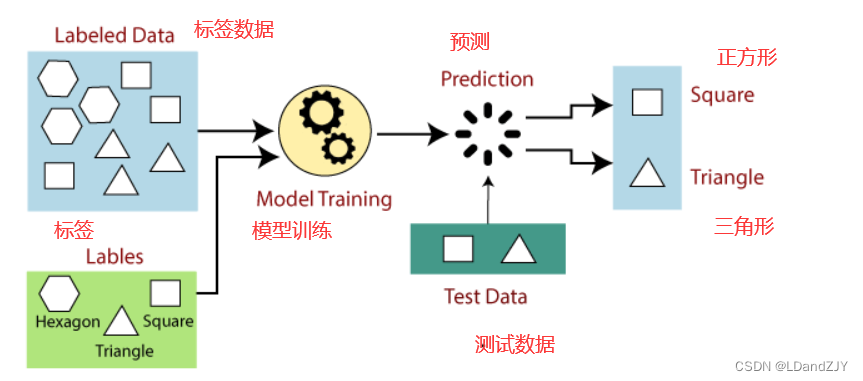
3、监督学习深入介绍
1、 监督学习三要素
模型(model):总结数据的内在规律,用数学函数描述的系统。
策略(strategy):选取最优模型的评价准则
算法(algorithm):选取最优模型的具体方法。
2、监督学习实现步骤
- 首先确定训练数据集的类型
- 收集/收集标记的训练数据(一般可能需要手动标记)
- 将训练数据集拆分为训练数据集、测试数据集和验证数据集。
- 确定训练数据集的输入特征,这些特征应该有足够的知识使模型能够准确地预测输出。
- 确定适合模型的算法,如支持向量机、决策树等。
- 在训练数据集上执行算法。有时我们需要验证集作为控制参数,它们是训练数据集的子集。
- 通过提供测试集来评估模型的准确性。如果模型预测出正确的输出,这意味着我们的模型是准确的。
3、监督机器学习算法的类型
监督学习可以进一步分为两类问题:回归和分类。
1、回归
如果输入变量和输出变量之间存在关系,则使用回归算法。它用于预测连续变量,例如天气预报、市场趋势等。以下是一些流行的回归算法,它们属于监督学习:
- 线性回归
- 回归树
- 非线性回归
- 贝叶斯线性回归
- 多项式回归
3、分类
当输出变量是分类时使用分类算法,这意味着有两个类别,例如是 - 否,男性 - 女性,真假等。垃圾邮件过滤,是否为垃圾等。
可能用到的算法:
- 随机森林
- 决策树
- 逻辑回归
- 支持向量机
监督学习应用举例:
-
预测房价或房屋出售情况
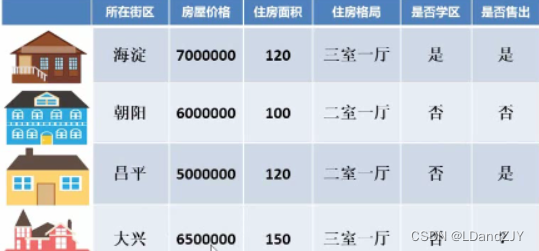
我们将所在街区、房屋价格、住房面积、住房格局、是否学区总体当成一个x,是否售出当做一个y输入模型内,再通过模型预测第四套房子是否售出。由于结果只有“是”和“否”这两个答案,因此结果是离散的,我们采用分类算法。如果我们要预测第四套房子的价格多少时可以售出,那么此时是否售出是“是”,y应该为房屋的价格。房屋的价格是连续的数字,有无穷多个可能,没有固定的数目,因此 不是离散的,我们采用回归算法。















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









