







前言
深度学习兴起以来,CNN一直是CV领域的主流模型,而且取得了很好的效果。与此同时,基于Self-attention结构的Transformer在NLP领域大放异彩。虽然Transformer结构已经成为NLP领域的标准,但在计算机视觉领域的应用还非常有限。
ViT(Vision Transformer)是Google在2020年提出的直接将Transformer应用在图像分类的模型,它证明了Transformer在视觉任务中的潜力。ViT通过将图像分割成若干固定大小的图块,并将每个图块视为一个序列输入到Transformer中进行处理。与传统的卷积神经网络不同,ViT摆脱了卷积操作,完全依赖自注意力机制来捕捉图像中的长距离依赖关系。
本篇文章将深入探讨Vision Transformer(ViT)的原理、架构以及其在图像分类任务中的表现,并给出每个子模块以及ViT全部模型的代码注释。
一、模型整体框架
ViT模型的整体结构如下图所示:
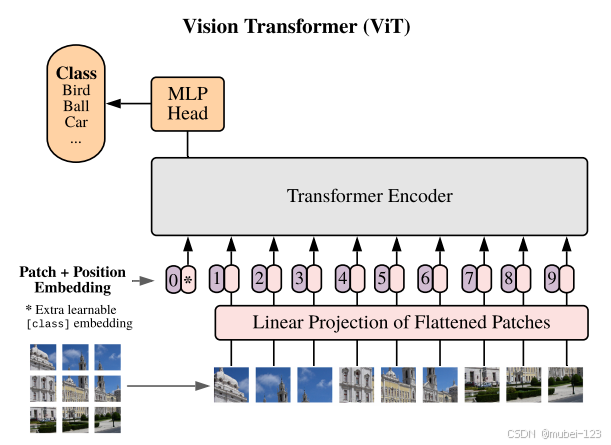
可以看出,ViT模型与传统的Transformer模型很相似,这也是ViT的作者设计ViT的初衷,即将可扩展的NLP Transformer架构及其高效实现,全部迁移过来使用。
从架构图中可以看出,ViT主要有Patch Embedding、Position Embedding、Transformer Encoder和MLP Head组成:
(1)Patch Embedding:将二维的图片转换成一维的序列,从而可以输入到Transformer Encoder中;
(2)Position Embedding:图像的每个patch和文本一样,也有先后顺序,所以我们需要再给每个补丁(也即NLP中的单词)向量添加位置信息;
(3)Transformer Encoder:ViT模型的核心模块,负责提取输入图片的特征向量,输入和输出的维度相同;
(4)MLP Head:Transformer Encoder的输出经Layer Norm层和抽取操作后,得到class token,将其输入MLP Head中,得到最终的分类结果。MLP一般由全连接的线性层组成,输出层的神经元数等于类别的个数。
下面,我们详细分析ViT的各个组成部分。
二、模型详解
2.1 Embedding
2.1.1 Patch Embedding
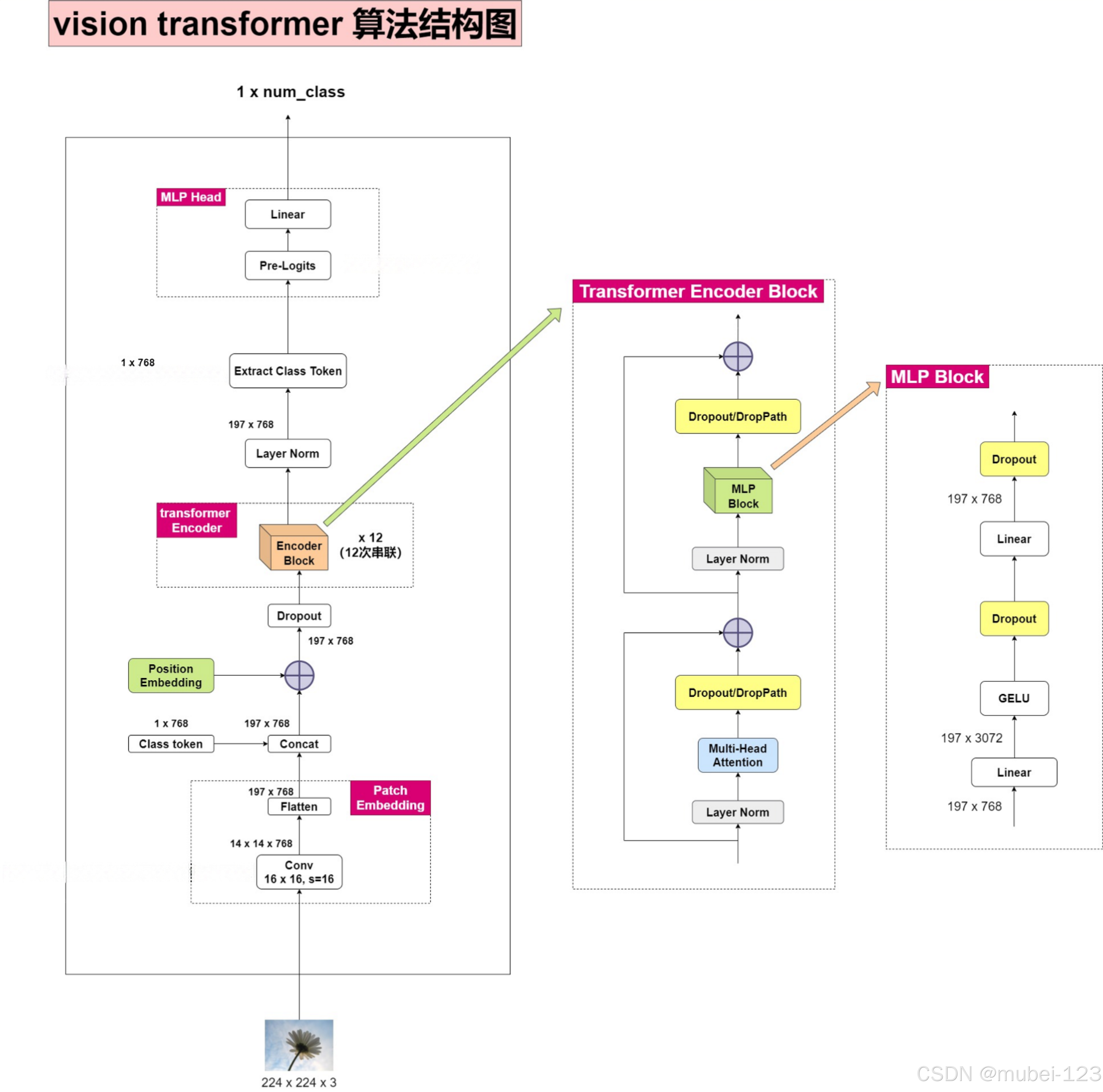
首先,对原始输入图像作切块处理。假设输入的图像大小为224×224,将图像切成一个个固定大小为16×16的方块,每一个方块就是一个patch,那么每张图像中patch的个数为(224×224)/(16×16) = 196个。切块后,我们得到了196个 [16, 16, 3] 的patch;
我们把这些patch送入Linear Projection of Flattened Patches(Embedding层),这个层的作用是将输入序列展平。所以输出后也有196个token,每个token的维度经过展平后为16×16×3 = 768,所以输出的维度为 [196, 768]。
不难看出,Patch Embedding的作用是将一个CV问题通过切块和展平转化为一个NLP问题。
2.1.2 类别编码
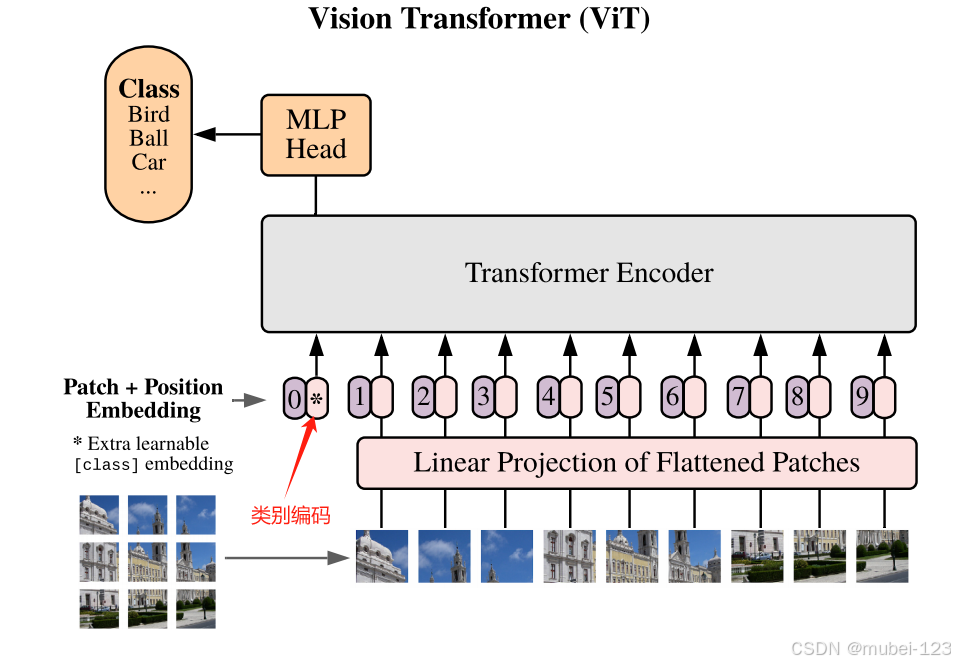
类别编码是一个用于表示图像整体的特殊标记符号,它的作用是让 Transformer 在整个图像的上下文中获取全局信息。Transformer 本身是基于序列模型的,它不像卷积神经网络 (CNN) 那样有局部感受野的结构,因此 Transformer 在处理图像时需要有一个机制来了解图像的全局信息。
类别编码就是一个类似于“占位符”的向量,表示图像的全局信息。它会与其他 patch 一同输入到 Transformer Encoder 中,最终模型学习到的类别编码的输出代表了整个图像的特征,可以用于分类或其他任务。
在框架图中,类别编码如下图箭头所指处所示:
2.1.3 Position Embedding
我们知道,图像的每个patch和文本一样,也有先后顺序,是不能随意打乱的,所以我们需要再给每个token添加位置信息。图像的196个token,加上类别编码class token(使用Concat操作而不是Add),需要Position Embedding的维度为197。
最终要输入到Transformer Encoder的序列维度为[197, 768]。
与传统Transformer不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 $sincos$ 编码,而是直接设置为可学习的 Positional Encoding 。
2.2 Transformer Encoder
Transformer Encoder共有L个Transformer Encoder Block组成(首尾连接),结构图如下图所示:
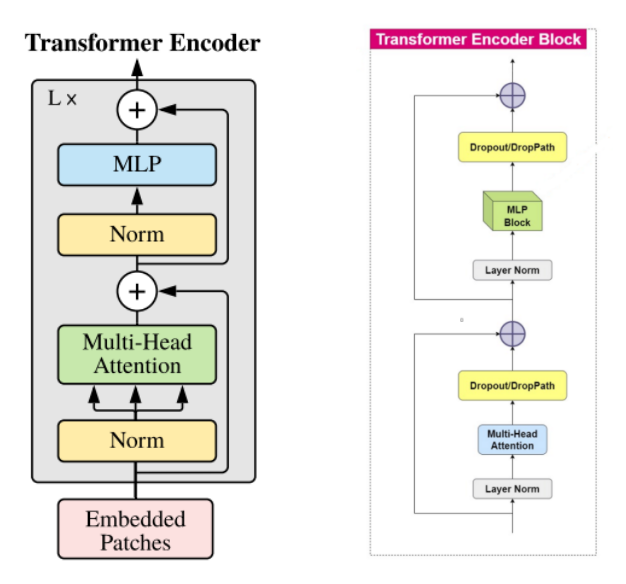
右侧为实际结构图,左图为原论文中给出的结构图,相比于世纪结构图,省去了Dropout/DropPath层(两次)。可以看出,主要有Layer Norm,Multi-Head Attention,Dropout/DropPath和MLP Block组成:
2.2.1 Layer Norm
Batch Norm(BN)是针对所有的样本,对某一个特征图计算均值和方差,然后然后对这个特征图神经元做归一化。
Layer Norm(LN)是对某一个样本,计算该样本所有特征图的均值和方差,然后对这个样本做归一化。
BN适用于不同mini-batch数据分布差异不大的情况,而且BN需要开辟变量以保存每个节点的均值和方差,空间消耗略大,而且 BN适用于有mini-batch的场景;LN只需要一个样本就可以做归一化,可以避免 BN 中受 mini-batch 数据分布影响的问题,也不需要开辟空间保存每个节点的均值和方差。
2.2.2 Multi-Head Attention
Multi-Head Attention是由多个Self-Attention组成,与传统的Transformer结构中的Multi-Head Attention一致(具体可看Transformer原理详解中的讲解),此处不再赘述。
2.2.3 Dropout/DropPath
Dropout和DropPath均为深度学习中应用的正则化方法,其中Dropout是随机的点对点路径的关闭,DropPath是随机的点对层之间的关闭。假设有一个Linear层是输入4结点,输出5结点,那么一共有20个点对点路径。dropout会随机关闭这些路径,而droppath会随机选择输入结点,使其与之相连的5条路径全部关闭。
原论文中描述是使用了DropOut,但实际复现过程中也可以使用DropPath,两者对最后的结果影响不大。
2.2.4 MLP Block
MLP Block的结构图如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4549
4549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









