







 ViT是首个将Transformer引入CV领域的模型,它在ImageNet上击败了当时的CNN。模型由Transformer编码器组成,使用多头自注意力机制处理图像块。ViT的优势在于其全局注意力机制和较低的参数数量,但挑战在于处理大图像时的计算复杂度和对大量数据的依赖。实验表明,ViT在大规模数据集上预训练后能取得SOTA性能。
ViT是首个将Transformer引入CV领域的模型,它在ImageNet上击败了当时的CNN。模型由Transformer编码器组成,使用多头自注意力机制处理图像块。ViT的优势在于其全局注意力机制和较低的参数数量,但挑战在于处理大图像时的计算复杂度和对大量数据的依赖。实验表明,ViT在大规模数据集上预训练后能取得SOTA性能。
ViT( Vision Transformer)
ViT(Vision Transformer)模型是一种在计算机视觉领域应用Transformer架构的模型。它首次将NLP领域中广泛使用的Transformer模型引入到了CV领域,并在ImageNet数据集上击败了当时最先进的CNN网络。
ViT模型的基本结构由Transformer编码器组成,其中包含多个Transformer编码层。每个编码层由多头自注意力机制(multi-head self-attention)和前馈神经网络(feed-forward neural network)组成。这种结构使得ViT能够充分捕捉图像中的全局信息和局部细节,从而实现准确的图像分类。
在ViT模型中,输入是一张图像,它首先被分割成一系列的图像块。每个图像块经过线性变换后,被展平成一个向量,并与位置编码相加。这样,每个图像块就被编码成一个向量表示,作为输入传递给Transformer编码器。每个编码层都包含一个多头自注意力机制和一个前馈神经网络,用于提取图像中的特征。
与CNN相比,ViT模型具有以下优势:
不依赖于卷积操作,减少了模型中的参数数量,从而降低了计算复杂度。
引入全局注意力机制,ViT模型能够有效地捕捉到图像中的全局信息,提高了在大规模图像数据集上的性能。
具有一定的泛化能力,可以应用于其他类型的数据,如自然语言处理中的序列数据。
然而,ViT模型也面临一些挑战。例如,对于较大的图像,ViT模型需要将其拆分为较小的图像块,这可能会导致信息丢失或精度下降。此外,ViT模型在处理高分辨率图像时的计算复杂度仍然较高。
ViT模型在中等规模(例如ImageNet)以及大规模(例如ImageNet-21K、JFT-300M)数据集上进行了实验验证。实验结果表明,当有大量的训练样本时,ViT模型可以达到或超越当前的SOTA水平。然而,在数据量不充分时,由于Transformer相较于CNN结构缺少一定的平移不变性和局部感知性,ViT模型的性能可能会受到一定影响。
模型介绍
在计算机视觉领域中,多数算法都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。有研究者提出,没有必要总是依赖于CNN。因此,作者提出ViT[1]算法,仅仅使用Transformer结构也能够在图像分类任务中表现很好。
受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
该算法在中等规模(例如ImageNet)以及大规模(例如ImageNet-21K、JFT-300M)数据集上进行了实验验证,发现:
- Transformer相较于CNN结构,缺少一定的平移不变性和局部感知性,因此在数据量不充分时,很难达到同等的效果。具体表现为使用中等规模的ImageNet训练的Transformer会比ResNet在精度上低几个百分点。
- 当有大量的训练样本时,结果则会发生改变。使用大规模数据集进行预训练后,再使用迁移学习的方式应用到其他数据集上,可以达到或超越当前的SOTA水平。
模型结构与实现
ViT算法的整体结构如 图1 所示。
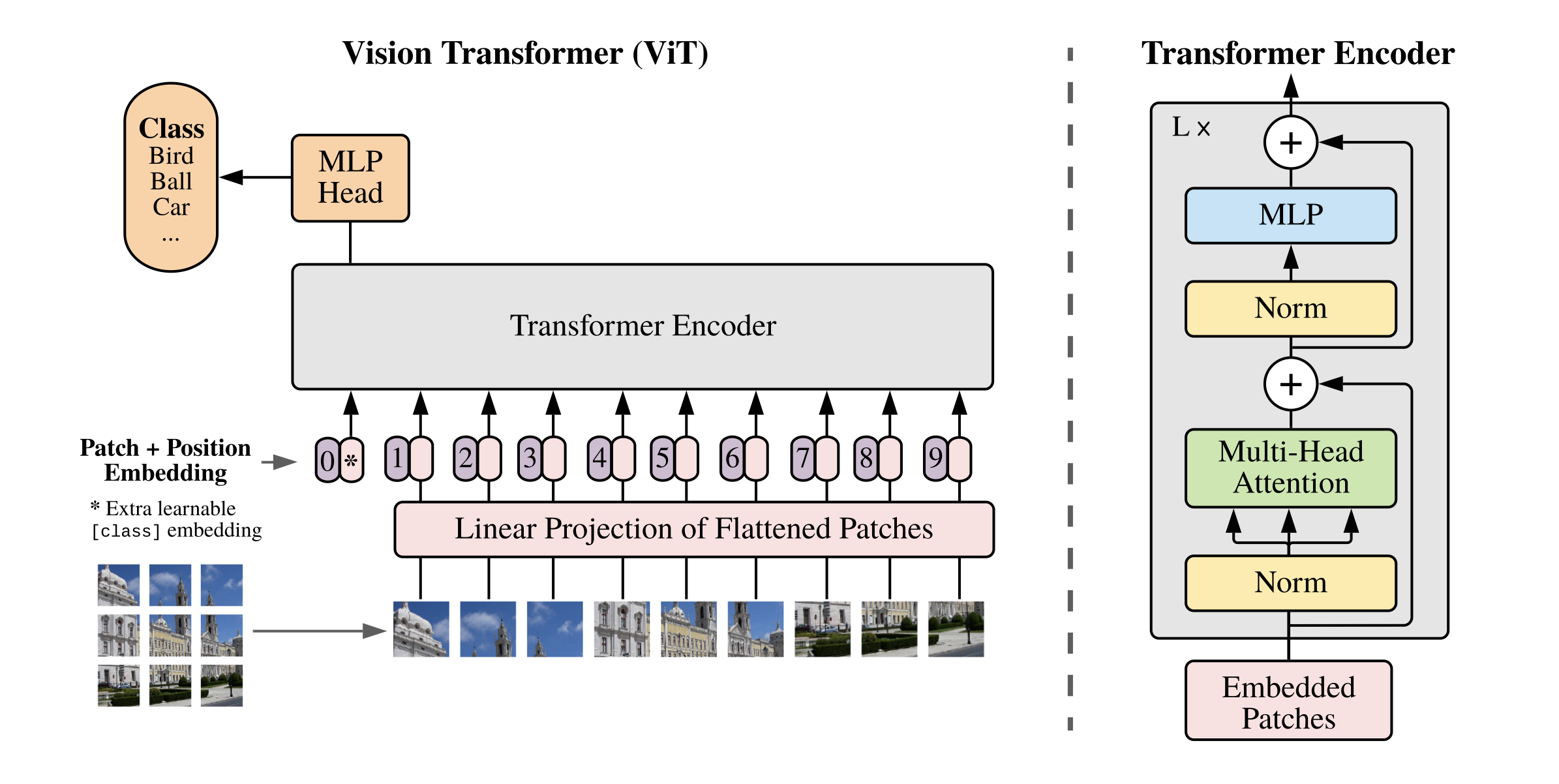
1. 图像分块嵌入
考虑到在Transformer结构中,输入是一个二维的矩阵,矩阵的形状可以表示为 ( N , D ) (N,D) (N,D),其中 N N N 是sequence的长度,而 D D D 是sequence中每个向量的维度。因此,在ViT算法中,首先需要设法将 H × W × C H \times W \times C H×W×C 的三维图像转化为 ( N , D ) (N,D) (N,D) 的二维输入。
ViT中的具体实现方式为:将 H × W × C H \times W \times C H×W×C 的图像,变为一个 N × ( P 2 ∗ C ) N \times (P^2 * C) N×(P2∗C) 的序列。这个序列可以看作是一系列展平的图像块,也就是将图像切分成小块后,再将其展平。该序列中一共包含了 N = H W / P 2 N=HW/P^2 N=HW/P2 个图像块,每个图像块的维度则是 ( P 2 ∗ C ) (P^2*C) (P2∗C)。其中 P P P 是图像块的大小, C C C 是通道数量。经过如上变换,就可以将 N N N 视为sequence的长度了。
但是,此时每个图像块的维度是 ( P 2 ∗ C ) (P^2*C) (P2∗C),而我们实际需要的向量维度是 D D D,因此我们还需要对图像块进行 Embedding。这里 Embedding 的方式非常简单,只需要对每个 ( P 2 ∗ C ) (P^2*C) (P2∗C) 的图像块做一个线性变换,将维度压缩为 D D D 即可。
上述对图像进行分块以及 Embedding 的具体方式如 图2 所示。
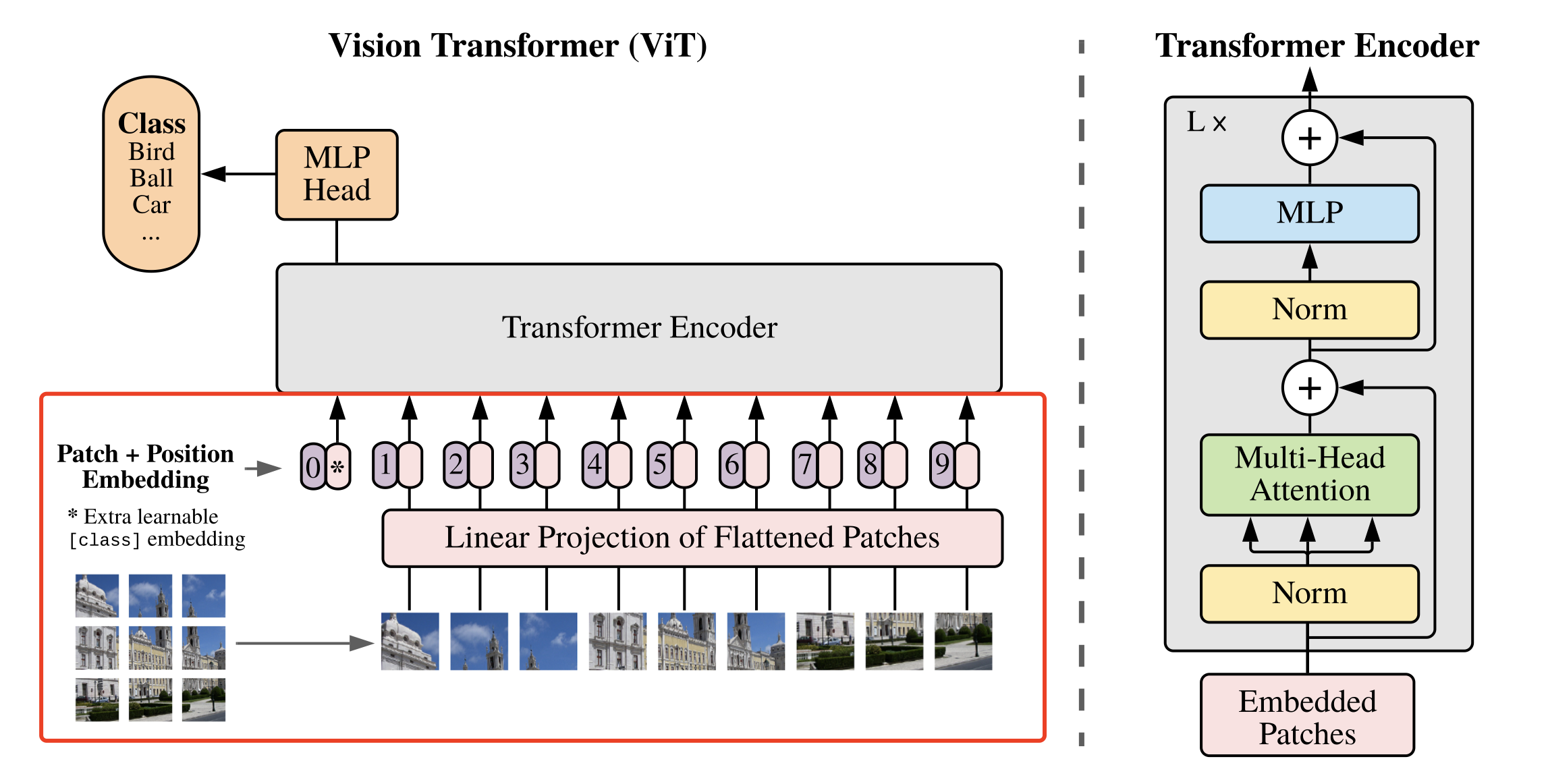
ViT(Vision Transformer)中图像分块嵌入(Patch Embedding)的核心步骤。在ViT中,为了将图像输入到Transformer结构中,需要进行以下几步处理:
图像分块:
输入图像通常具有 H×W×C 的形状,其中 H 和 W 分别是图像的高度和宽度,C 是颜色通道数(在RGB图像中通常是3)。
图像被均匀地切分成大小为 P×P 的小块,其中 P 是块的大小。这可以通过在图像的高度和宽度上应用步长为 P 的滑动窗口来实现。
分块后,图像被表示为一个由 N=HW/P 2 个小块组成的集合
。
展平与连接:
每个 P×P×C 的图像块被展平成一个 P 2 ×C 的一维向量。
所有这些一维向量被连接成一个二维矩阵,其形状为 N×(P 2×C)。
Patch Embedding:
由于Transformer需要固定长度的输入,因此我们需要将每个图像块的维度从 P 2 ×C 转换为 D。
这通过线性变换(也称为嵌入层或全连接层)来实现,该变换将每个 P 2 ×C 的向量映射到一个 D 维的向量上。
结果是一个 N×D 的矩阵,可以直接作为Transformer的输入。
位置编码(可选):
由于Transformer本身不包含任何循环或卷积结构,因此它不知道输入序列中元素的位置信息。
为了解决这个问题,通常会在输入到Transformer之前添加一个位置编码(如正弦和余弦位置编码)。
位置编码与Patch Embedding的输出相加或拼接,以提供位置信息。
Transformer编码器:
经过Patch Embedding处理后的 N×D 矩阵被输入到Transformer编码器中。
Transformer编码器通过自注意力机制和多层前馈神经网络来捕捉图像块之间的依赖关系。
分类头(对于分类任务):
对于图像分类任务,Transformer编码器的输出通常会被送入一个额外的分类头(如全连接层)。
分类头将Transformer编码器的输出映射到类别分数的向量上。
通过上述步骤,ViT能够将图像作为一系列图像块的序列输入到Transformer中,从而利用Transformer强大的序列建模能力来处理图像数据。
具体代码实现如下所示。本文中将每个大小为 P P P 的图像块经过
大小为 P P P 的卷积核来代替原文中将大小为 P P P 的图像块展平后接全连接运算的操作。
# 图像分块、Embedding
class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
# 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224]
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
# 图像块的个数
num_patches = (img_size[1] // patch_size[1]) * \
(img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
# kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理
# 输入维度为3,输出维度为块向量长度
# 与原文中:分块、展平、全连接降维保持一致
# 输出为[B, C, H, W]
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











