




论文题目:LightLoc: Learning Outdoor LiDAR Localization at Light Speed(LightLoc:以光速学习户外激光雷达定位)
会议:CVPR2025
摘要:场景坐标回归在室外激光雷达定位中取得了令人印象深刻的结果,但需要几天的训练。由于每个新场景都需要重复训练,长时间的训练对于需要时间敏感的系统升级的应用来说是不切实际的,比如自动驾驶、无人机、机器人等。我们认为,大规模户外场景中的大覆盖区域和大量数据是限制快速训练的关键挑战。在本文中,我们提出了LightLoc,这是第一种能够在新场景中以光速有效学习定位的方法。除了冻结与场景无关的特征主干和只训练特定于场景的预测头之外,我们引入了两种新技术来解决这些挑战。首先,我们引入样本分类指导来辅助回归学习,减少相似样本的歧义,提高训练效率。其次,我们提出冗余样本下采样,在训练过程中去除学习良好的帧,在不影响准确性的情况下减少训练时间。此外,样本分类的快速训练和置信度估计特性使其能够集成到SLAM中,有效消除误差积累。在大规模户外数据集上进行的大量实验表明,LightLoc只需1小时的训练就能达到最先进的性能,比现有方法快50倍。
项目地址:https://github.com/liw95/LightLoc

引入:LiDAR定位旨在估计传感器的6自由度姿态,这是许多应用的基本组成部分,例如自动驾驶和机器人。
一、研究背景与问题
1.1 LiDAR定位的重要性
LiDAR定位是估计传感器6自由度(6-DoF)位姿的技术,是自动驾驶、机器人等应用的基础组件。当前主流方法分为两类:
-
基于地图的方法:将查询点云与预构建的3D地图匹配
- 缺点:需要昂贵的3D地图存储和高通信开销
-
基于回归的方法:将场景信息记忆在网络参数中
- 绝对位姿回归(APR):直接回归位姿
- 场景坐标回归(SCR):预测点云对应关系,再用RANSAC求解位姿
- 优势:SCR显式利用几何信息,定位精度更高
1.2 核心问题:训练时间过长
虽然SCR性能优异,但存在严重的实用性问题:
- LiSA作为当前最先进的方法,达到0.95m精度需要约53小时训练
- 每个新场景都需要重新训练,使其在需要快速系统升级的应用中不实用
1.3 大规模户外场景的两大挑战
论文识别出两个关键挑战:
挑战1:大覆盖区域
- 包含许多视觉相似的区域
- 使基于回归的方法训练变得复杂
挑战2:海量数据
- 自动驾驶数据集覆盖2km²,包含约150K训练样本
- 即使采样为1024点、512维特征,也需要约150GB存储空间
- 难以在GPU上存储特征进行优化
二、方法创新
2.1 整体框架设计
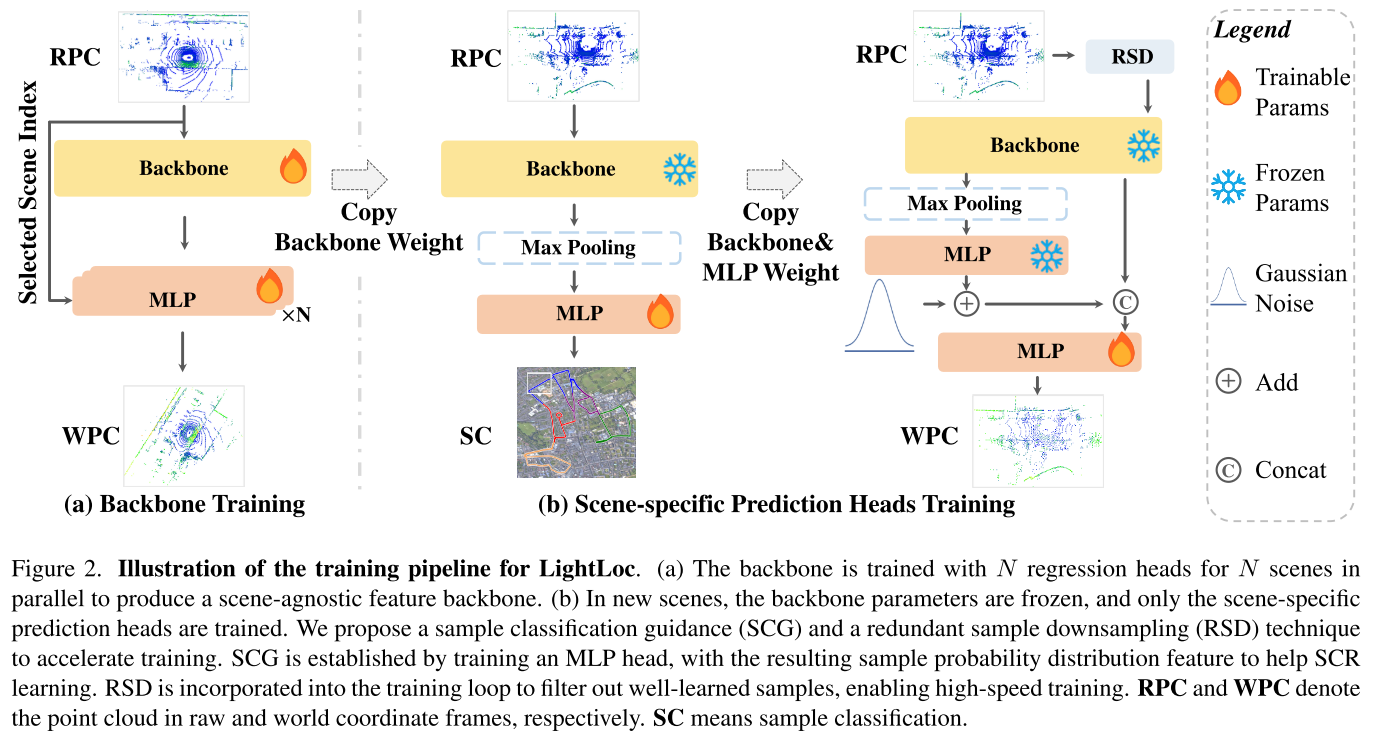
LightLoc采用两阶段训练策略:
阶段1:骨干网络训练
- 在N个场景上并行训练N个回归头和一个共享的特征骨干网络
- 在18个nuScenes场景上训练,包含350K帧,耗时2天
- 产生16M参数的场景无关特征提取器
阶段2:场景特定预测头训练
- 冻结骨干网络参数,只训练场景特定的预测头
- 结合两项创新技术:SCG和RSD
2.2 创新技术1:样本分类引导(SCG)
设计动机: 解决大覆盖区域中视觉相似样本带来的学习模糊性
实现方法:
-
标签生成
- 使用K-Means算法将训练位置聚类为k1个簇
- 在位置上聚类(而非点云地图),确保快速生成标签
-
分类网络训练
- 输入:点云P
- 特征提取:使用冻结的骨干网络f(P)
- 全局池化:获得全局特征
- MLP预测:生成样本概率分布
- 使用交叉熵损失训练,平滑因子ε=0.1
- 训练时间:仅需5分钟!
-
指导回归学习
- 归一化的样本概率分布特征添加高斯噪声(σ=0.1),再归一化到单位球面
- 将特征融合到SCR框架中
- 有效引导学习,确保快速收敛并防止过拟合
核心优势:
- 减少相似区域的模糊性
- 提高训练效率
- 提供置信度估计
2.3 创新技术2:冗余样本下采样(RSD)

设计动机: 解决海量数据带来的计算负担
核心思想: LiDAR的大范围(100m)和高频率(10Hz)导致数据冗余,通过识别并移除已学好的样本来加速训练
实现方法:
RSD是一个分层采样技术,将训练过程分为四个阶段:
第一阶段(初始训练):
- 在完整训练集T上优化E1个epoch
- 对每个样本计算L1损失的中位数Lm(选择中位数是因为对异常值鲁棒)
第二阶段(首次下采样):
- 在滑动窗口S内计算Lm的方差V
- 在epoch E1+S时,按V降序排序,保留前(1-rd)×|T|个样本
- 高方差样本优先保留,因为它们表示收敛较慢,需要更多训练
第三阶段(二次下采样):
- 在下采样集T'上重复过程,进一步减少到(1-rd)²×|T|个样本
第四阶段(恢复完整训练):
- 从epoch Es开始,在完整集T上训练以确保所有样本收敛
关键参数:
- 下采样率rd = 0.25
- 启动比率rst = 0.25
- 停止比率rsp = 0.85
核心优势:
- 通过简单计算损失方差,开销最小
- 训练期间排除已收敛样本
- 在保持精度的同时加速训练
2.4 集成到SLAM
SCG的5分钟快速训练和置信度估计特性使其能够集成到SLAM中,帮助消除误差累积
改进方法:
-
层次化分类网络
- 修改为两级结构:第一级k1个簇,第二级k2个簇,共k1×k2个簇
- 置信度定义为两级分类概率的乘积
- 仍可在5分钟内训练完成
-
卡尔曼滤波融合
- 过程系统:使用SLAM的位置估计
- 测量系统:使用分类网络输出的簇中心,测量噪声Vt=I×(1-c),c为置信度
- 滤波系统:通过卡尔曼增益更新状态估计,获得校正结果
三、实验结果
3.1 数据集与评估指标
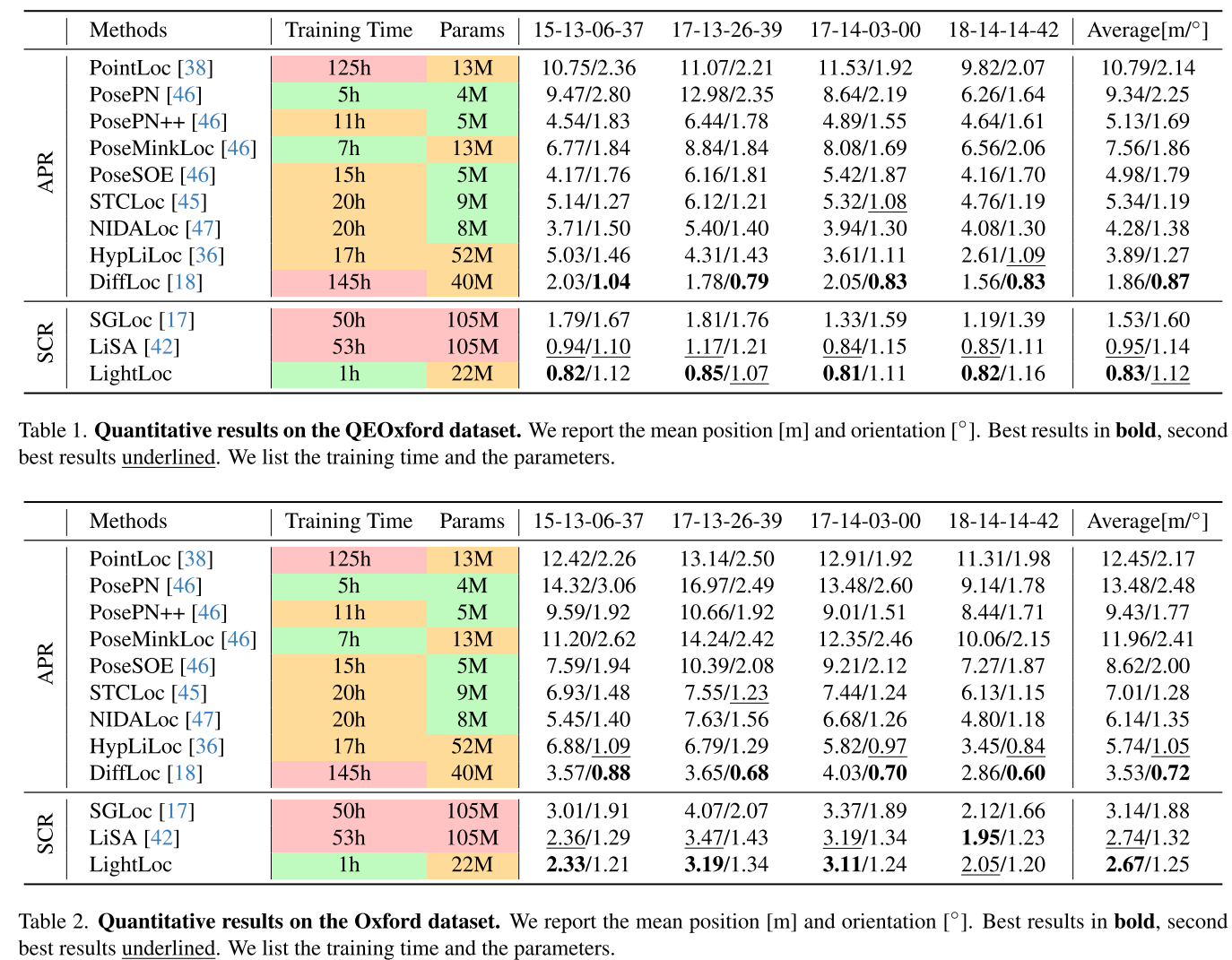
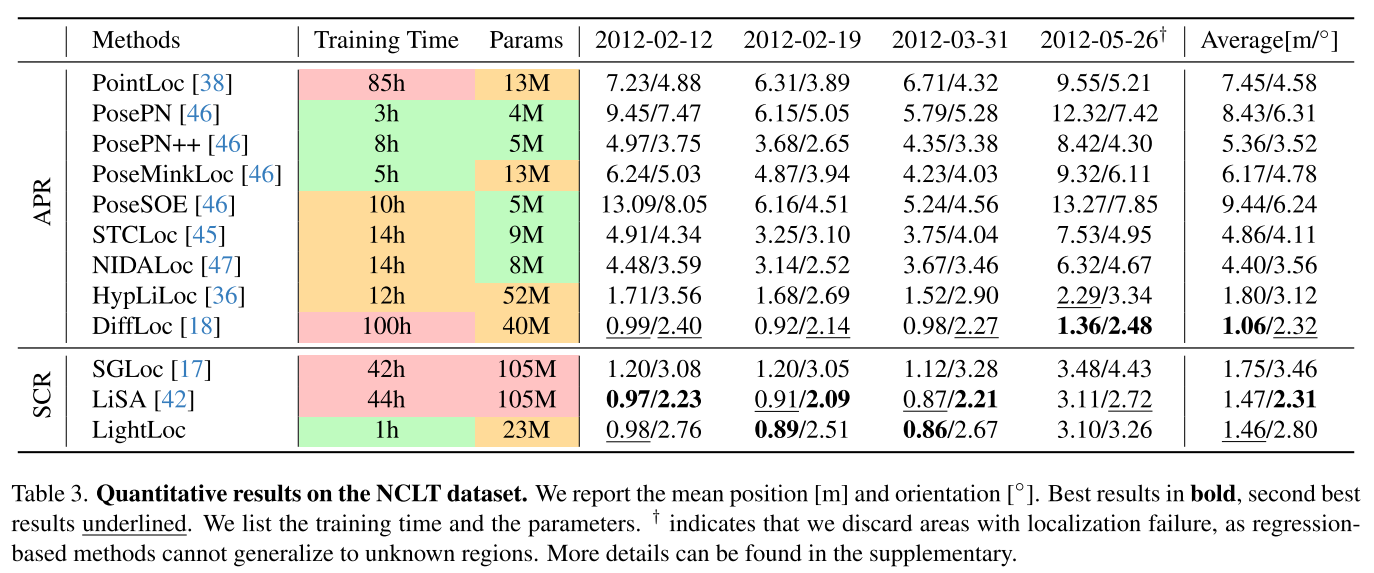
评估数据集:
- Oxford Radar RobotCar:覆盖约2km²,轨迹约10km,城市场景
- QEOxford:Oxford的质量增强版本
- NCLT:校园场景,覆盖约0.45km²,轨迹约5.5km
评估指标: 平均位置误差(米)和方向误差(度)
3.2 与最先进方法的对比
QEOxford数据集结果
LightLoc表现:
- 位置误差:0.83m(最佳)
- 方向误差:1.12°(第二佳)
- 训练时间:1小时
- 参数量:22M
与SOTA方法对比:
| 方法 | 训练时间 | 参数量 | 位置/方向误差 |
|---|---|---|---|
| LiSA (SCR SOTA) | 53h | 105M | 0.95m/1.14° |
| DiffLoc (APR SOTA) | 145h | 40M | 1.86m/0.87° |
| SGLoc | 50h | 105M | 1.53m/1.60° |
| LightLoc | 1h | 22M | 0.83m/1.12° |
关键发现:
- 相比LiSA:训练时间减少50倍,参数量减少4倍,精度相当或更好
- 相比DiffLoc:训练时间快145倍,位置精度提高55.4%,且只需单帧输入
Oxford数据集结果
- LightLoc:2.67m/1.25°
- LiSA:2.74m/1.32°
- 训练时间:1小时 vs 53小时
NCLT数据集结果
- LightLoc:1.46m/2.80°
- LiSA:1.47m/2.31°
- 训练时间:1小时 vs 44小时
3.3 推理速度
- Oxford数据集:29ms(要求<50ms)
- NCLT数据集:48ms(要求<100ms)
- 满足实时性要求
3.4 SLAM误差消除效果
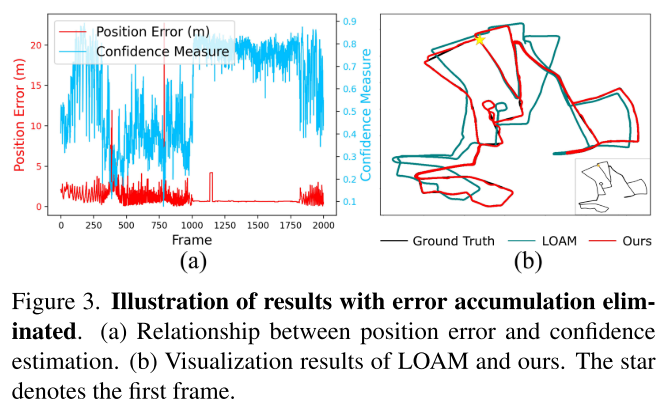
在QEOxford数据集上,将LOAM的平均位置误差从87.81m降低到4.48m,改善率94.9%
3.5 消融实验
骨干网络冻结的影响:
- 冻结场景无关骨干网络,只训练场景特定预测头,训练时间减少约57.9%,性能相当
SCG的影响:
- 位置精度提高19.6%,方向精度提高17.3%,训练时间减少约45.8%
RSD的影响:
- 在保持精度的情况下,进一步提升23.1%的训练效率
聚类数k1的影响:
| k1 | 5 | 15 | 25 | 50 | 100 |
|---|---|---|---|---|---|
| 分类准确率 | 100% | 99.86% | 99.79% | 99.55% | 99.19% |
| 误差(m/°) | 0.90/1.18 | 0.85/1.12 | 0.83/1.12 | 0.89/1.17 | 0.89/1.16 |
采样策略对比:
| 采样率 | 随机采样 | 均匀采样 | RSD |
|---|---|---|---|
| 15% | 1.02/1.30 | 0.82/1.13 | 0.82/1.11 |
| 25% | 1.12/1.37 | 0.92/1.14 | 0.83/1.12 |
| 35% | 1.25/1.55 | 1.25/1.52 | 0.93/1.15 |
RSD在25%剪枝率下无明显精度下降,即使在35%时下降也很小,通过有效选择已学好的样本确保了稳定性能
四、技术亮点总结
4.1 创新性
- 首个实现1小时训练的方法:相比现有SOTA方法快50倍
- 针对大规模户外场景的定制化设计:SCG和RSD分别解决覆盖范围大和数据量大的问题
- 多功能性:SCG不仅加速训练,还可集成到SLAM中消除误差累积
4.2 实用价值
- 快速部署:使基于回归的定位方法能够应用于需要时间敏感的系统升级场景
- 资源高效:
- 参数量减少4倍(22M vs 105M)
- 无需昂贵的GPU存储
- 即插即用:场景无关骨干网络可迁移到新场景
4.3 性能平衡
- 精度:达到或超过当前SOTA水平
- 速度:训练时间减少50倍,推理满足实时性
- 规模:参数量减少4倍
五、局限性与未来工作
5.1 当前局限
-
并非所有测试轨迹都达到最高性能:论文坦诚说明,方法的主要关注点是训练时间和存储需求,而非在所有情况下都达到最高精度
-
骨干网络训练仍需时间:虽然新场景训练快,但初始的场景无关骨干网络训练仍需2天
5.2 未来方向
论文提出将探索在更多场景、平台和LiDAR类型的数据上联合训练骨干网络,进一步提高泛化能力
六、总结
LightLoc是LiDAR定位领域的一项重要突破,它首次实现了在大规模户外场景中仅用1小时就能完成训练的目标。通过创新的SCG和RSD技术,论文优雅地解决了大覆盖区域和海量数据两大挑战,为基于回归的定位方法的实际应用铺平了道路。
核心贡献:
- 训练时间从2天缩短到1小时(50倍加速)
- 保持或超越SOTA精度
- 参数量减少4倍
- 可集成到SLAM消除误差累积
这项工作对自动驾驶、无人机、机器人等需要快速系统更新的应用具有重要意义,使得基于学习的定位方法在实际部署中更加可行。

















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









