






深度强化学习算法:DDPG TD3 SAC
实验环境:机器人MuJoCo
YID:7750717083674322
什么都会的超级工科男
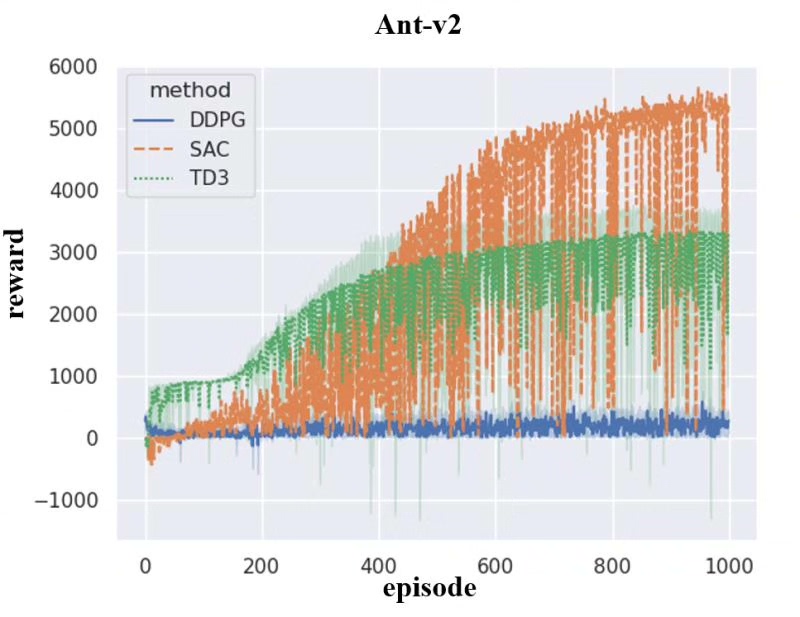
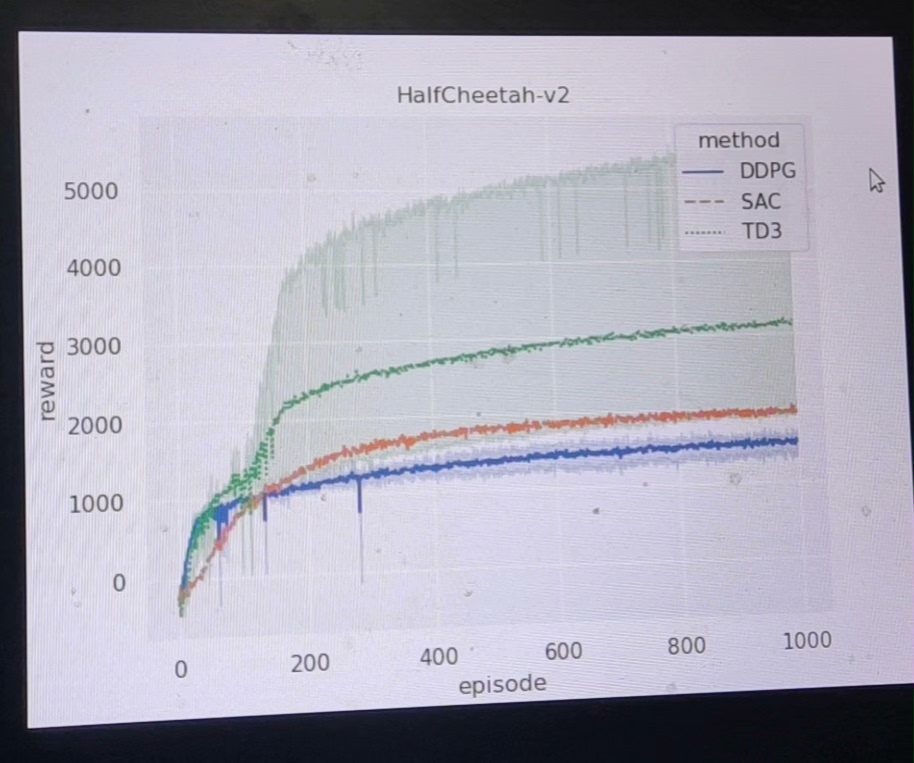
深度强化学习算法(Deep Reinforcement Learning)自问世以来,一直是人工智能领域备受瞩目的研究方向。它通过让智能体在环境中与之交互,并根据不同的行为进行奖励或惩罚来训练智能体的策略,从而实现智能体在未知环境中的自主决策和学习能力。在这篇文章中,我们将重点介绍三种常用的深度强化学习算法:DDPG、TD3和SAC,并以机器人MuJoCo环境为例,展示它们在实验中的应用和效果。
DDPG(Deep Deterministic Policy Gradient)是一种基于策略梯度和Q-learning的算法。它引入了一个Actor-Critic框架,其中Actor负责输出动作策略,Critic则负责评估这些动作策略的价值。DDPG通过利用神经网络来近似Actor和Critic的函数,实现在连续动作空间下的强化学习。在MuJoCo环境中,我们可以利用DDPG算法来训练机器人完成一系列复杂的动作任务,例如行走、跳跃等。实验结果显示,DDPG算法在MuJoCo环境中可以取得较好的性能。
TD3(Twin Delayed DDPG)是对DDPG算法的改进。它通过增加两个Critic网络,引入了双重Q网络和延迟更新的机制,从而进一步提升了算法的性能和稳定性。TD3在MuJoCo环境中的实验表明,相比于DDPG算法,TD3能够更快地收敛,并且对于一些复杂任务具有更好的鲁棒性和泛化能力。
SAC(Soft Actor-Critic)是一种基于最大熵理论的算法。它以最大化策略的熵为目标,通过在训练过程中引入一个熵系数来平衡探索和利用之间的权衡。SAC算法在MuJoCo环境中的实验结果表明,相比于DDPG和TD3算法,SAC能够更好地探索环境,提高整体性能,并且在一些复杂任务中表现出更好的稳定性。
总结来说,DDPG、TD3和SAC是三种常用的深度强化学习算法,它们在MuJoCo环境中的实验表明,这些算法能够在复杂的机器人任务中取得良好的性能。然而,每种算法都有其特点和适用范围,选择合适的算法需要考虑任务的复杂性、样本效率和计算开销等因素。未来,我们可以进一步研究和改进这些算法,以满足更高级别的任务需求,并推动深度强化学习在机器人领域的应用。
以上相关代码,程序地址:http://wekup.cn/717083674322.html















 6211
6211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









