










专题:大数据单机学习环境搭建和使用
大数据单机学习环境搭建(10)Pycharm中操作spark和hive
1.环境准备
需要提前准备Hadoop、Hive、Spark和Anaconda,以及Pycharm连接Linux的Anaconda环境,具体见本人如下相关文章。
Hadoop本地单节点安装
Linux使用yum安装Mysql
Hive单节点安装和启用
Spark单节点安装与pyspark使用
Linux单节点Anaconda安装和Pycharm连接
另外,还可以看Azkaban调用,执行定时任务,包括python、hive、spark都可以执行,具体见下方文章。
Azkaban单机部署
Azkaban的简单使用
2.Pycharm连接Hive
- 必须关闭防火墙
systemctl stop firewalld和 开启 hiveserver2/opt/hive/bin/hiveserver2,因为连接的本质是 jdbc:hive2://自己的ip:10000,暂时不理解的话直接操作就行,不影响使用
- 可以从"文件-设置"找到数据库,也可以通过侧边栏找到,具体如图
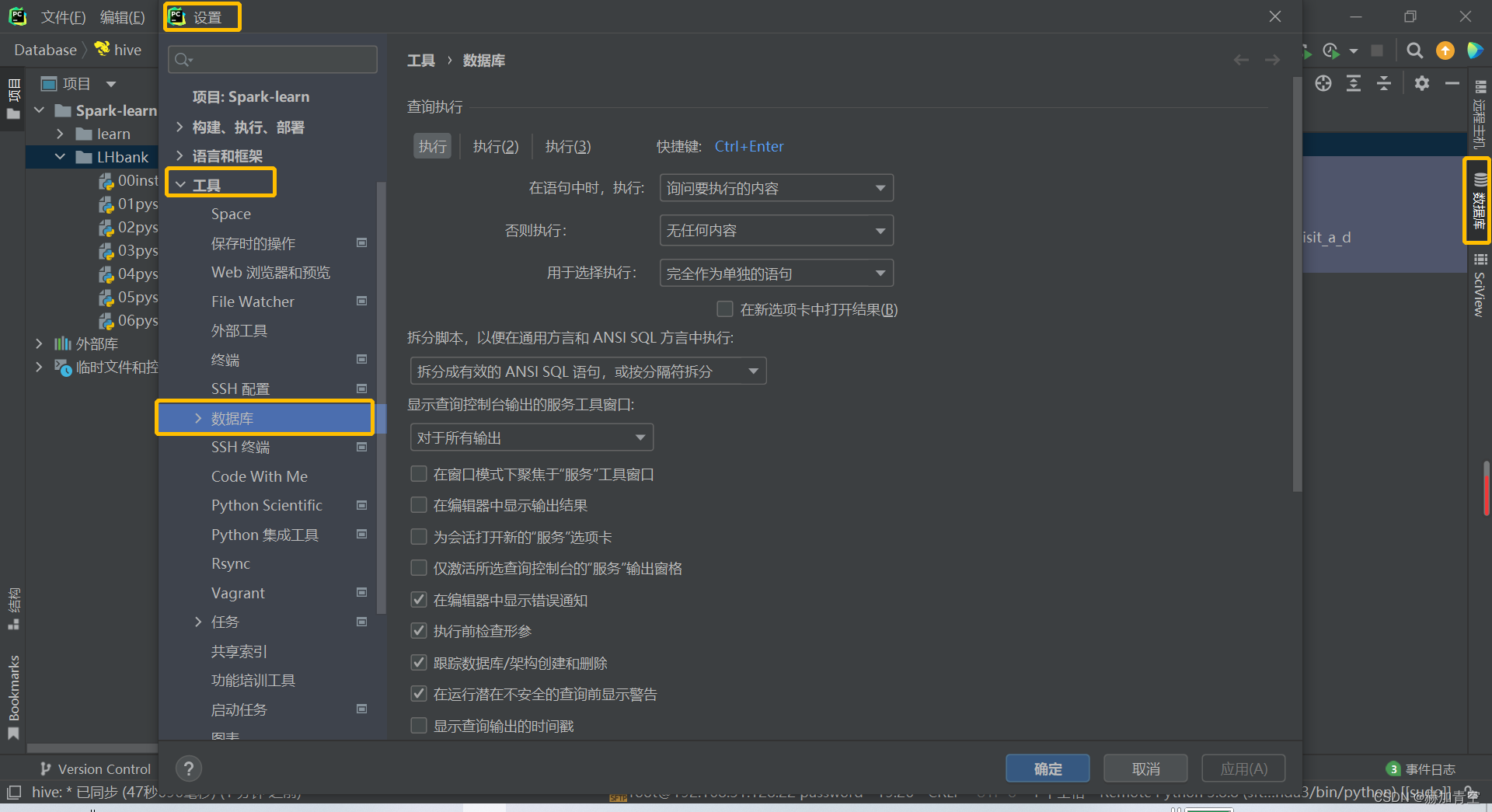
- Hive数据库连接,碰到要安装驱动就点击安装,最后测试连接显示如图即完成
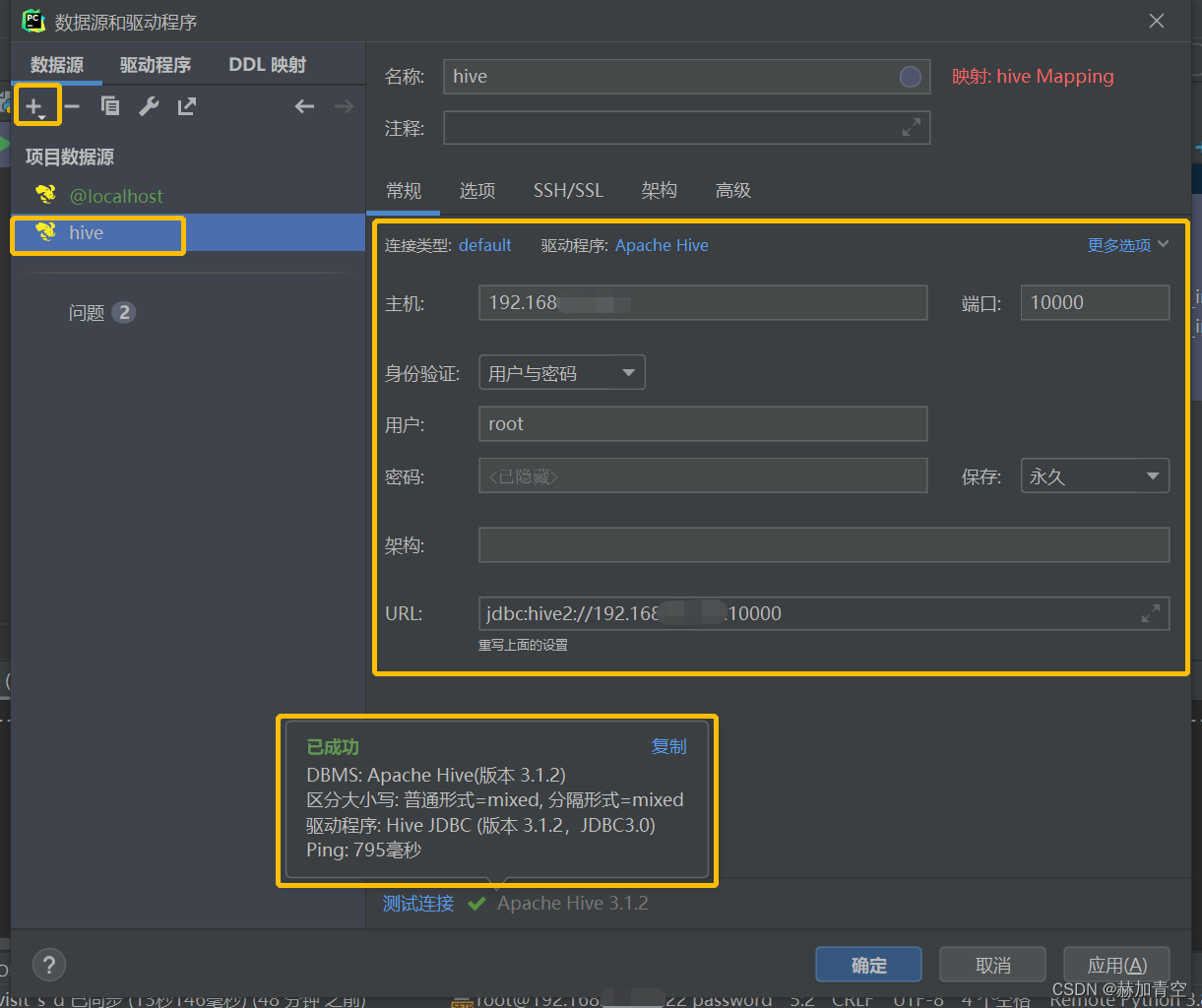
- 添加查询控制台即可如图执行MR查看数据,不再赘述,但是MR太慢了,关于HQL优化见另一篇文章 Hive优化实现
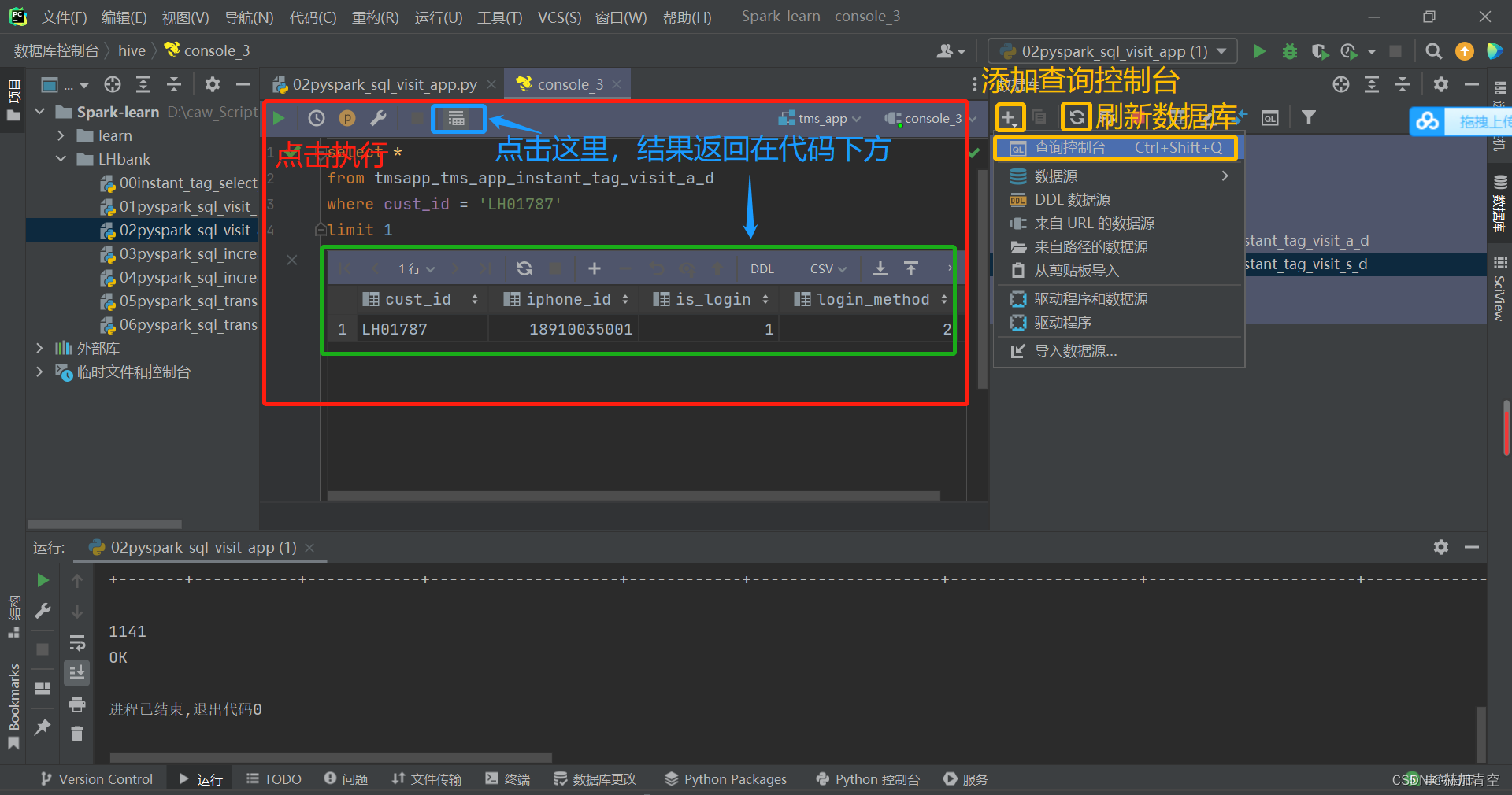
至此,通过pycharm可以方便的查看和操作Hive了
3.Pycharm执行py脚本
先解决Pycharm执行sparksql时碰到的问题
错误:JAVA_HOME is not set ,执行下方命令即可解决
# /etc/environment中加入JAVA_HOME变量即可
vim /etc/environment
JAVA_HOME=/opt/jdk # 换成自己的jdk路径

3.1SparkSql操作数据的方式
SparkSql的两种操作数据的方式(DSL和SQL)
1.SQL方式
Spark单节点安装与pyspark使用 3.Spark使用中的脚本就是纯粹的SQL方式
举个简单例子,完整代码会再后面给出,别着急
sql_result = """select * from tms_app.tmsapp_tms_app_instant_tag_visit_s_d where dt=current_date();"""
spark.sql(sql_result).show(5)
2.DSL方式
sql_result = """select * from tms_app.tmsapp_tms_app_instant_tag_visit_s_d where dt=current_date();"""
result = spark.sql(sql_result)
# where
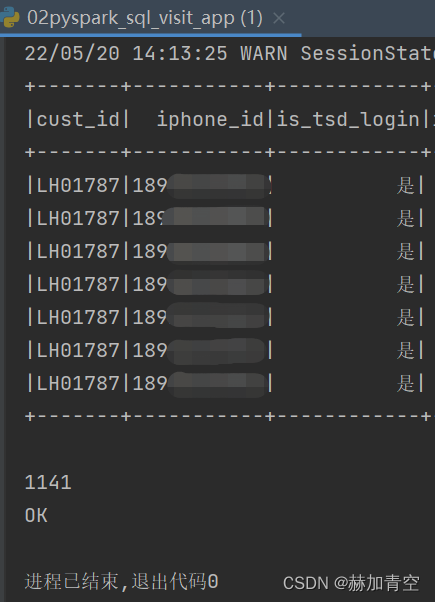
result.where(result.cust_id == 'LH01787').show()
# count
result_ct = result.count()
print(result_ct)
返回结果如图,有where过滤后show的结果,有count后print的结果
3.2一个完整的pyspark脚本
这个可以接上 Spark单节点安装与pyspark使用 的内容继续执行,如果没有按照上述文件建a_d的表,请先执行上述文件,然后进行s_d表的操作,因为s_d表采用orc格式的文件,不支持load方法,只能insert,如果对Hive建表不了解可以看本人另一篇文章 Hive建表DDL详解。
这个脚本包括删表、建表、删分区、建分区、插入数据、查询数据,DSL和SQL的混合使用。内容简单不再赘述
# -*- coding:utf-8 -*-
"""
访问类报表创建
"""
from pyspark.sql import SparkSession
import datetime
spark = SparkSession.builder \
.appName('learn') \
.master("local[*]") \
.config("spark.sql.shuffle.partitions", 1) \
.config("spark.sql.warehouse.dir", "hdfs://自己的ip:8020/user/hive/warehouse") \
.config("hive.metastore.uris", "thrift://自己的ip:9083") \
.enableHiveSupport() \
.getOrCreate()
# 删表
sql_drop_table = """drop table if exists tms_app.tmsapp_tms_app_instant_tag_visit_s_d;"""
spark.sql(sql_drop_table)
# 建表
sql_create_table = """
CREATE TABLE tms_app.tmsapp_tms_app_instant_tag_visit_s_d(
cust_id string comment '客户号' ,
vip_name string comment '会员名称'
)
COMMENT '结果表'
PARTITIONED BY (dt string )
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
;
"""
spark.sql(sql_create_table)
# 分区格式yyyy-MM-dd,当前日期yyyyMMdd格式
cur_dt = datetime.datetime.now().strftime('%Y-%m-%d')
cur_dt_simple = datetime.datetime.now().strftime('%Y%m%d')
# 查询
sql = """
insert overwrite table tms_app.tmsapp_tms_app_instant_tag_visit_s_d partition (dt='{}')
(select * from tms_app.tmsapp_tms_app_instant_tag_visit_a_d
)
;
""".format(cur_dt)
# 删除分区
sql_drop_partition = """alter table tms_app.tmsapp_tms_app_instant_tag_visit_s_d drop if exists partition (dt='{}');""".format(
cur_dt)
spark.sql(sql_drop_partition)
# 增加分区
sql_add_partition = """alter table tms_app.tmsapp_tms_app_instant_tag_visit_s_d add partition (dt='{}');""".format(
cur_dt)
spark.sql(sql_add_partition)
# 插入select数据
spark.sql(sql)
# 查询数据插入结果
sql_result = """select * from tms_app.tmsapp_tms_app_instant_tag_visit_s_d where dt=current_date();"""
# spark.sql(sql_result).show()
result = spark.sql(sql_result)
result.where(result.cust_id == 'LH01787').show()
result_ct = result.count()
print(result_ct)
print('OK')
spark.stop()
至此,Pycharm可以正常操作Spark,相较Hive默认的的MR引擎Spark有极为明显的优势,具体比较后续会有使用原理的内容更新,到这里大数据环境搭建的专题就基本完成了。
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,如有雷同纯属巧合。















 2757
2757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









