






前言
在自然语言处理(NLP)领域,大模型(LLM)的发展日新月异,为各种应用场景带来了前所未有的能力。近日,Meta公司宣布推出了其最新的开源模型——Llama 3.1,这一消息在行业内引起了广泛关注。本文将详细介绍Llama 3.1的背景、特点、部署流程以及使用实例,帮助读者深入了解并掌握这一强大的NLP工具。
Llama 3.1概述
大模型(LLM)是指基于深度学习算法进行训练的自然语言处理模型,它们不仅在自然语言理解和生成方面表现出色,还广泛应用于机器视觉、多模态处理和科学计算等领域。随着“百模大战”的愈演愈烈,开源LLM如雨后春笋般涌现,其中包括国外的LLaMA、Alpaca以及国内的ChatGLM、BaiChuan、InternLM等。这些模型支持用户本地部署和私域微调,为每一个想要构建独特大模型的开发者提供了可能。
2024年7月23日,Meta公司宣布了迄今为止最强大的开源模型Llama 3.1,并同时发布了405B、70B和8B三个版本的模型。其中,Llama 3.1 405B模型支持上下文长度为128K Tokens,在基于15万亿个Tokens、超过1.6万个H100 GPU上进行训练,是Meta有史以来训练规模最大的一次。尽管我们此次主要关注8B版本的部署与使用,但其背后的技术实力和应用潜力不容忽视。
Llama 3.1 8B部署流程
创建实例
部署Llama 3.1 8B模型的第一步是创建一个合适的GPU云实例。以下是在Ubuntu 22.04环境下,使用Python 3.12、CUDA 12.1和PyTorch 2.4.0的基本步骤:
- 选择实例配置:在GPU云实例页面选择付费类型(如按量付费或包月套餐),并配置GPU数量和型号。推荐配置为NVIDIA GeForce RTX 4090,其拥有60GB内存和24GB显存(满足Llama 3.1 8B至少16G显存的需求)。

- 配置数据硬盘:每个实例默认附带50GB数据硬盘,可根据需要扩容至60GB。
- 选择镜像:选择安装了PyTorch 2.4.0的基础镜像,以快速启动环境。
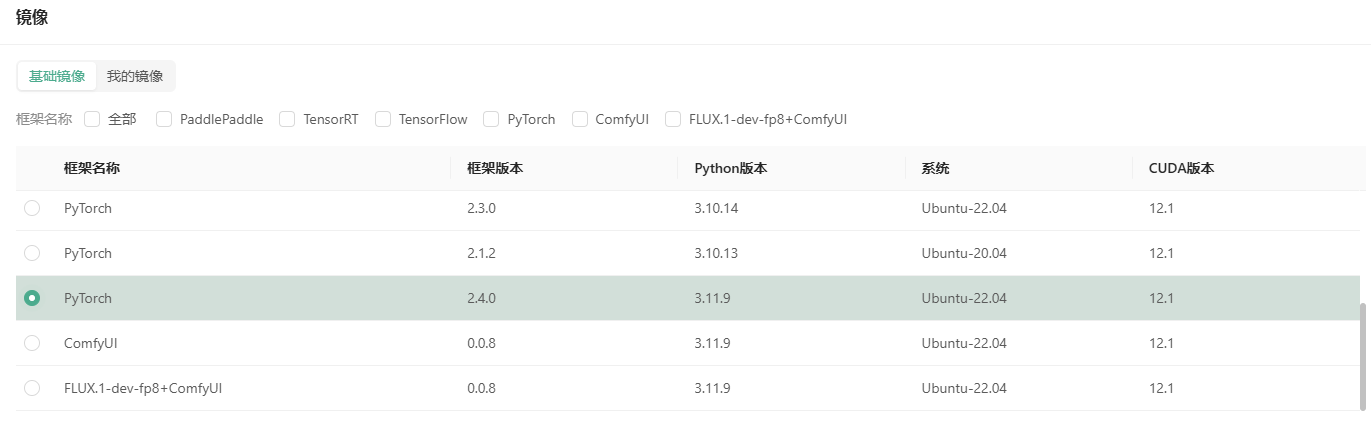
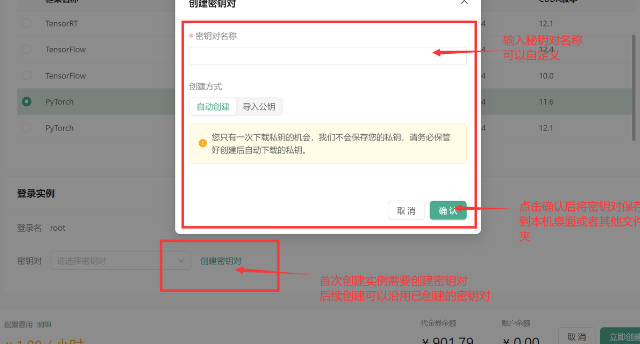
- 创建密钥对:创建并保存密钥对,以便后续通过SSH登录实例。
登录实例
实例创建成功后,可以通过多种方式登录,包括JupyterLab和SSH。SSH登录需要用户名、远程主机域名或IP、端口号以及登录密码或密钥。
部署Llama 3.1
- 创建Conda环境:使用conda创建Python 3.12的新环境,并激活该环境。
- 安装依赖:安装Langchain、Streamlit、Transformers和Accelerate等依赖库。
- 下载模型:通过内网高速下载Llama-3.1-8B-Instruct模型,并解压缩。
使用教程
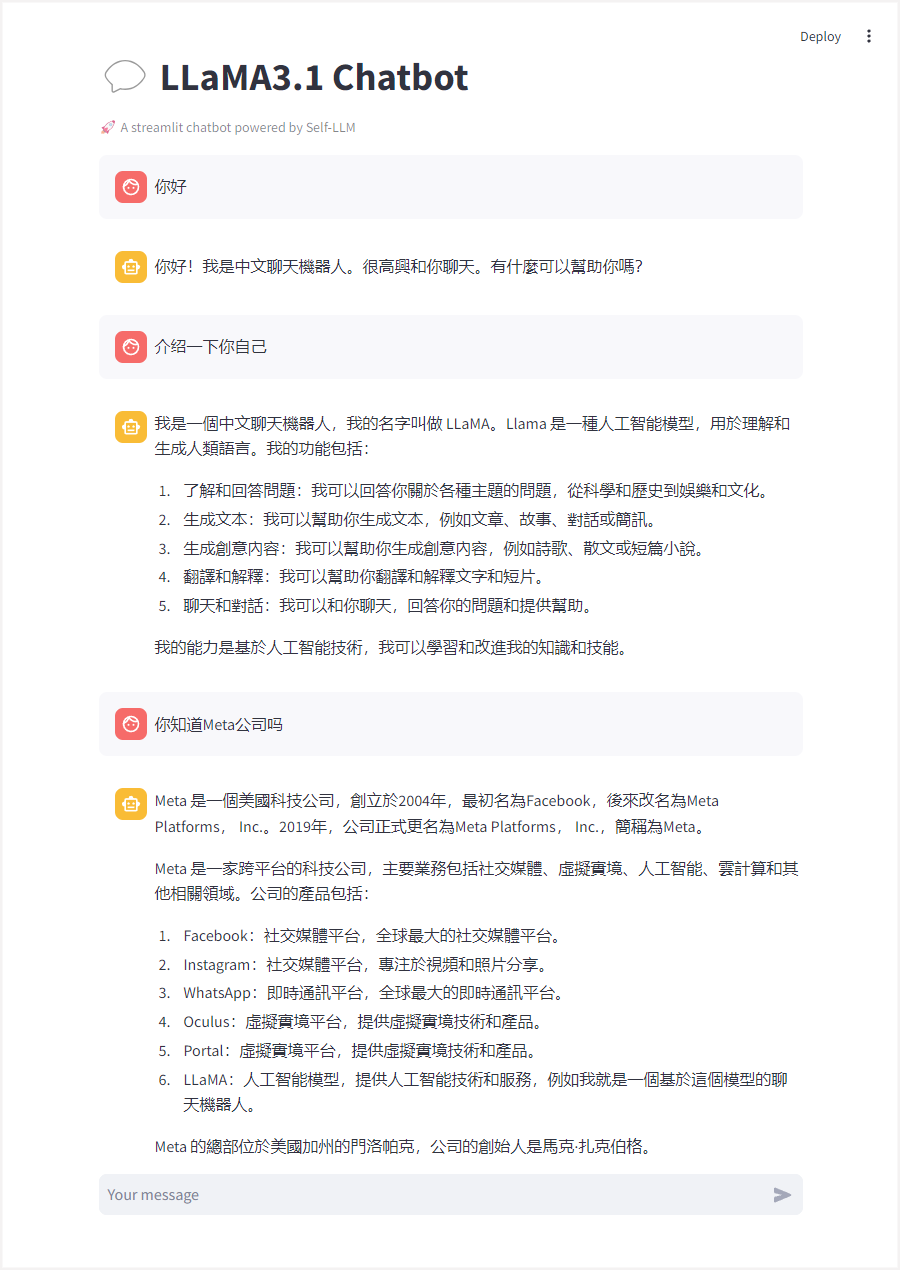
部署完成后,可以开始使用Llama 3.1 8B模型进行自然语言处理任务。以下是一个简单的聊天机器人示例:
- 编写Python脚本:创建
<font style="color:rgb(5, 7, 59);">llamaBot.py</font>文件,并编写代码加载模型、处理用户输入和生成响应。 - 启动Streamlit服务:在终端中运行命令启动Streamlit服务,确保服务地址指定为0.0.0.0,以便通过浏览器访问。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 创建一个标题和一个副标题
st.title("💬 LLaMA3.1 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")
# 定义模型路径
mode_name_or_path = '/root/workspace/Llama-3.1-8B-Instruct'
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 从预训练的模型中获取模型,并设置模型参数
model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()
return tokenizer, model
# 加载LLaMA3的model和tokenizer
tokenizer, model = get_model()
# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 将对话输入模型,获得返回
input_ids = tokenizer.apply_chat_template(st.session_state["messages"],tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 将模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
print(st.session_state)
- 端口映射:使用云实例的端口映射功能,将内网端口映射到公网,以便通过访问链接与聊天机器人交互。

应用前景与挑战
Llama 3.1的推出为自然语言处理领域带来了新的机遇。凭借其强大的上下文理解能力和生成能力,Llama 3.1在对话系统、内容创作、辅助写作等领域具有广泛的应用前景。然而,随着模型规模的不断扩大,也带来了算力、存储和训练成本等方面的挑战。此外,如何有效地利用和调优模型,以及如何保护用户隐私和数据安全,也是亟待解决的问题。
结语
Llama 3.1的推出标志着自然语言处理技术的又一重要进展。通过深入了解其特点、部署流程和使用方法,我们可以更好地利用这一强大的工具,推动自然语言处理技术的发展和应用。未来,随着技术的不断进步和应用的不断扩展,我们有理由相信,自然语言处理将为我们带来更多的便利和惊喜。















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









