







1.编译llama.cpp命令行(电脑版本);
2.交叉编译安卓命令行版本。
一、Llama.cpp是什么?
llama.cpp是一个开源项目,专门为在本地CPU上部署量化模型而设计。它提供了一种简单而高效的方法,将训练好的量化模型转换为可在CPU上运行的低配推理版本。
1.1 KV Cache
KV Cache是大模型推理中常用到的一个技巧,可以减少重复计算,加快推理速度。
KV Cache之所以可行,就是因为在LLM decoding阶段的Attention计算需要causal mask,这就会导致前面已经生成的Token不需要与后面的Token重新计算Attention,从而每个token的生成只和KV相关,与之前的Q无关,进而可以让我们通过缓存KV的方式避免重复计算。
1.2 LLM推理流程
大模型推理流程:
用户提问(prompt)-》1.输入Tokenize化--〉2.获取token的embedding+位置编码--》3.大模型推理一般包括两个阶段prefilling和decoding。
1.2.1 输入Tokenize化
原始的输入都是文本,也有可能是多模态类型的音频、图像,我们需要将其转化成大模型能识别的token。Token可以翻译为词元,在自然语言处理中,它通常是指一个词、一个字符或者一个子词等语言单位。tokenize就相当于传统NLP任务中的分词。用户输入的提问,通过切分,形成一个token列表。
大模型有一个词汇表,其中包含了模型能够识别的所有token。在将文本转化为token序列时,会根据词汇表中的token进行匹配和划分。
这一步的主要目的是将原始的prompt转化为token的id序列。
1.2.2 获取token的embedding+位置编码
这一步的操作是将token的id序列转化成embedding序列,embedding就是每个token的向量化表示。此外,在真正开始推理之前embedding中还需要加入位置编码(positional encoding)信息,这是由于transformer结构不再使用基于循环的方式建模文本输入,序列中不再有任何信息能够提示token之间的相对位置关系。具体来说,每个token在整个序列中所处的位置都会有一个位置向量,这一向量会与token的embedding向量相加。步骤1和2相当于大模型推理的前处理,将文本或者多模态输入变成一个N x d的矩阵正式进入后续大模型的推理阶段。
1.2.3 大模型推理
大模型推理一般包括两个阶段prefilling和decoding,如下图所示。
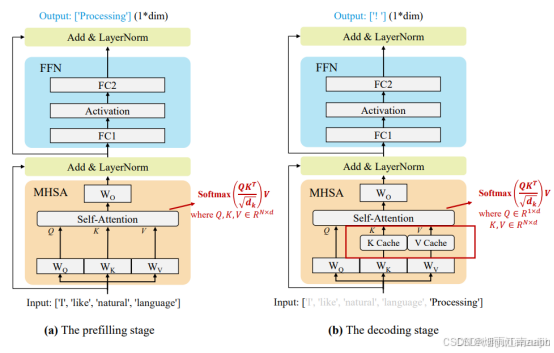
1.2.3.1 Prefilling阶段
Prefilling阶段就是将步骤2中生成的N x d矩阵送到大模型中做一遍推理。N就是prompt分词之后的长度,也即上下文的长度。N通常情况下会比较大,当前的大模型普遍可以支持128K的上下文。因为要一次性完成整个prompt对应token的计算,所以prefilling阶段的计算量很大,但它是一次性的过程,所以在整个推理中只占不到 10% 的时间。
更核心的是要解决Attention计算过程中显存占用过大的问题,业界的主流的方案就是FlashAttention。
大模型的最后一层往往是softmax,用来输出每个token的概率,从中选择概率最大的作为大模型的第一个输出token。对应的是模型的首响输出。
事实上,如果不考虑速度因素,单纯利用prefilling也可以完成整个大模型的推理过程。每完成一次大模型推理我们就可以获得一个token,将其与prompt和之前输出的所有token组合重新开始新一轮的大模型推理,直到输出停止符为止。
不过我们很容易看出这种推理模式包含非常多的重复计算,每增加一个token,prompt部分的推理就会重复一次。但是这些重复计算是没有意义的,所以才会将大模型推理拆分成了prefilling+decoding两阶段,目的就是要在prefilling阶段计算KV Cache供decoding阶段使用,当然prefilling也会生成第一个输出token。
1.2.3.2 decoding阶段
decoding阶段就是自回归输出每个token的过程。这里首先要强调一点,prefilling和decoding用的都是相同的大模型,只是推理方式不同:prefilling阶段一次性灌入整个prompt,而decoding阶段则是一次灌入一个token。所以prefilling阶段主要的操作是gemm(矩阵乘),到了decoding阶段就变成了gemv(矩阵向量乘)。正是由于 decoding阶段是逐个token生成的,每一次回答都会生成很多token,所以decoding阶段的数量非常多,占到整个推理过程的90%以上。decoding阶段就是要利用prefilling阶段生成的KV Cache来避免重复计算,这里的核心点在于causal mask机制保证了transformer每一个block中的Attention计算可以实现逐行运算。
将prefilling阶段输出的第一个token加decoding阶段所有的输出token组合起来即可以转换为最终的输出。
1.2.3 采样参数
为什么我们实际在使用大模型的时候同样的输入每次输出也不同呢?
这里面涉及到了大模型采样参数的问题。在prefilling阶段我们提到,可以选择softmax层中概率最大的token作为输出,这可以看做是一种贪婪解码,我们可以完全不选择top1作为输出,而是引入更多采样策略让生成的结果更加多样化,比如从topk中随机选择一个,又或者引入beam-search之类的解码策略。
二、Llama.cpp编译
首先我们尝试编译llama.cpp.
2.1 下载llama.cpp
项目的github地址:
https://github.com/ggerganov/llama.cpp
2.1.1 采用git克隆项目
可以采用git下载:
$ git clone https://github.com/ggerganov/llama.cpp然后同步submodules
$ cd llama.cpp
$ git submodule update kompute因为科学上网的问题,如果一直同步失败。这种情况下,可以考虑下载项目的方式。
2.1.2 手动下载项目
1)下载llama.cpp
llama.cpp项目页,code-->DownloadZip,然后下载。下载得到压缩包llama.cpp-master.zip,然后解压缩。
2)下载submodule。
[submodule "kompute"]
path = ggml/src/kompute
url = https://github.com/nomic-ai/kompute.git项目--》ggml-->src-->kompute @ 4565194 点击进入,同样(code-->DownloadZip),下载完成后,解压缩,然后拷贝到目标目录。
ggml/src/kompute
这样,项目就下载成功了。
2.2 编译项目
llama.cpp提供了本地API调用版本(直接调用本地模型进行推理),以及服务端版本(C/S架构)。
我们采用本地API版本。
首先看项目下的README.md
$ make -j && ./llama-cli -m models/llama-13b-v2/ggml-model-q4_0.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
可以看到,直接采用make编译。项目已经配置了cmake.
2.2.1 如何编译
在项目的docs/build.md, 有编译说明文档。
Linux or MacOS:采用make编译:
$ make采用cmake编译:
$ cmake -B build
$ cmake --build build --config Release我们直接使用 make编译。
编译完成以后,会在项目下生成一个build目录,生成物在此目录下。

项目根目录或者bin目录下是生成的可执行文件。此目录下的 llama-cli 和main 就是llama.cpp的命令行程序。
2.2.2 测试大模型推理
$ chmod +x llama-cli
$ ./llama-cli -m [模型名] --prompt [提问]
$ ./llama-cli -m [模型名] -p [提问]提问可以使用 -p 或者 -- prompt
例如:可以选择一个模型。模型未下载的话需要先进行下载。
$ ./llama-cli -m ./models/MiniCPM-0-2-Q4_K.gguf --prompt "北京有什么好玩的地方"得到推理结果:
build: 0 (unknown) with Android (11349228, +pgo, +bolt, +lto, -mlgo, based on r487747e) clang version 17.0.2 (https://android.googlesource.com/toolchain/llvm-project d9f89f4d16663d5012e5c09495f3b30ece3d2362) for x86_64-apple-darwin23.2.0
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_loader: loaded meta data with 24 key-value pairs and 219 tensors from ./models/MiniCPM-0-2-Q4_K.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = minicpm
llama_model_loader: - kv 1: general.name str = MiniCPM
llama_model_loader: - kv 2: minicpm.context_length u32 = 8192
llama_model_loader: - kv 3: minicpm.embedding_length u32 = 1024
llama_model_loader: - kv 4: minicpm.block_count u32 = 24
llama_model_loader: - kv 5: minicpm.feed_forward_length u32 = 2560
llama_model_loader: - kv 6: minicpm.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: minicpm.attention.head_count u32 = 8
llama_model_loader: - kv 8: minicpm.attention.head_count_kv u32 = 2
llama_model_loader: - kv 9: minicpm.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: general.file_type u32 = 15
llama_model_loader: - kv 11: minicpm.tie_lm_head bool = false
llama_model_loader: - kv 12: tokenizer.ggml.model str = llama
llama_model_loader: - kv 13: tokenizer.ggml.pre str = default
llama_model_loader: - kv 14: tokenizer.ggml.tokens arr[str,122753] = ["<unk>", "<s>", "</s>", "<SEP>", "<C...
llama_model_loader: - kv 15: tokenizer.ggml.scores arr[f32,122753] = [-1000.000000, -1000.000000, -1000.00...
llama_model_loader: - kv 16: tokenizer.ggml.token_type arr[i32,122753] = [3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 17: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 18: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 19: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 22: tokenizer.chat_template str = {% for message in messages %}{% if me...
llama_model_loader: - kv 23: general.quantization_version u32 = 2
llama_model_loader: - type f32: 49 tensors
llama_model_loader: - type q4_K: 145 tensors
llama_model_loader: - type q6_K: 25 tensors
llm_load_vocab: special tokens cache size = 3
llm_load_vocab: token to piece cache size = 0.7660 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = minicpm
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 122753
llm_load_print_meta: n_merges = 0
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 8192
llm_load_print_meta: n_embd = 1024
llm_load_print_meta: n_layer = 24
llm_load_print_meta: n_head = 8
llm_load_print_meta: n_head_kv = 2
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 4
llm_load_print_meta: n_embd_k_gqa = 256
llm_load_print_meta: n_embd_v_gqa = 256
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 2560
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 8192
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = ?B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 503.11 M
llm_load_print_meta: model size = 309.47 MiB (5.16 BPW)
llm_load_print_meta: general.name = MiniCPM
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 1099 '<0x0A>'
llm_load_print_meta: max token length = 48
llm_load_tensors: ggml ctx size = 0.20 MiB
llm_load_tensors: offloading 24 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 25/25 layers to GPU
llm_load_tensors: Metal buffer size = 242.04 MiB
llm_load_tensors: CPU buffer size = 67.43 MiB
.................................................
llama_new_context_with_model: n_ctx = 8192
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M1
ggml_metal_init: picking default device: Apple M1
ggml_metal_init: using embedded metal library
ggml_metal_init: GPU name: Apple M1
ggml_metal_init: GPU family: MTLGPUFamilyApple7 (1007)
ggml_metal_init: GPU family: MTLGPUFamilyCommon3 (3003)
ggml_metal_init: GPU family: MTLGPUFamilyMetal3 (5001)
ggml_metal_init: simdgroup reduction support = true
ggml_metal_init: simdgroup matrix mul. support = true
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: recommendedMaxWorkingSetSize = 11453.25 MB
llama_kv_cache_init: Metal KV buffer size = 192.00 MiB
llama_new_context_with_model: KV self size = 192.00 MiB, K (f16): 96.00 MiB, V (f16): 96.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.47 MiB
llama_new_context_with_model: Metal compute buffer size = 241.75 MiB
llama_new_context_with_model: CPU compute buffer size = 18.01 MiB
llama_new_context_with_model: graph nodes = 824
llama_new_context_with_model: graph splits = 2
llama_init_from_gpt_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 4
system_info: n_threads = 4 (n_threads_batch = 4) / 8 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 0 | NEON = 1 | SVE = 0 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
sampler seed: 1822835924
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> top-k -> tail-free -> typical -> top-p -> min-p -> temp-ext -> softmax -> dist
generate: n_ctx = 8192, n_batch = 2048, n_predict = -1, n_keep = 1
北京有什么好玩的地方吗
北京旅游攻略北京有哪些好玩的地方?
北京有什么好玩的地方吗
北京旅游攻略1、颐和园(北京颐和园):中国四大皇家园林之一,位于北京西郊,以水景和园林艺术闻名于世,被誉为“皇家园林博物馆”。颐和园以其碧水、碧草、碧花、碧石、碧泉、碧松、碧池、碧莲、碧云、碧林等自然景观而闻名于世,是中华民族文化的象征。
颐和园位于北京西郊,以水景和园林艺术闻名于世,被誉为“皇家园林博物馆”。颐和园以其碧水、碧草、碧花、碧石、碧泉、碧莲、碧云、碧林等自然景观而闻名于世,是中华民族文化的象征。
颐和园是中国八大名胜之一。颐和园位于北京西山南麓,东临昆明湖,西濒昆明湖,北依九龙山。它由内湖、外湖、山门、东配殿、西配殿、玉祥殿等部分构成。整个园呈南北走向,园内群山环绕,水景丰富。
颐和园的门票为20元。颐和园有1个入口,游客可乘坐园中索道游览。门票:1.门票:门票包括门票和景区的游览车,游览车收费在10元--60元之间,景区内游览车收费标准在20-100元之间。2.景区的游览车:游览车费用在20元--100元之间。
颐和园的门票包括门票和景区的游览车,游览车收费在10元-60元之间,景区内游览车收费标准在20-100元之间。颐和园有1个入口,游客可乘坐园中索道游览。门票:1.门票:门票包括门票和景区的游览车,游览车收费在10元--60元之间,景区内游览车收费标准在20-100元之间。
颐和园的门票包括门票和景区的游览车,游览车费用在20元--100元之间。
颐和园的门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园有1个入口,游客可乘坐园中索道游览。门票:1.门票:门票包括门票和景区的游览车,游览车费用在20元-100元之间,景区内游览车收费标准在20-100元之间。2.景区的游览车:游览车费用在20元-100元之间。
颐和园门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园的门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园有1个入口,游客可乘坐园中索道游览。
门票:1.门票:门票包括门票和景区的游览车,游览车费用在20元-100元之间,景区内游览车收费标准在20-100元之间。2.景区的游览车:游览车费用在20元-100元之间。
颐和园门票包括门票和景区的游览车,游览车费用在20元-100元之间。
颐和园有1个入口,游客可乘坐园中索道游览。门票:1.门票:门票包括门票和景区的游览车,游览车费用在20元-100元之间,景区内游览车收费标准在20-100元之间。2.景区的游览车:游览车费用在20元-100元之间。 [end of text]
llama_perf_sampler_print: sampling time = 174.82 ms / 888 runs ( 0.20 ms per token, 5079.63 tokens per second)
llama_perf_context_print: load time = 213.10 ms
llama_perf_context_print: prompt eval time = 23.00 ms / 5 tokens ( 4.60 ms per token, 217.35 tokens per second)
llama_perf_context_print: eval time = 8911.11 ms / 882 runs ( 10.10 ms per token, 98.98 tokens per second)
llama_perf_context_print: total time = 9372.60 ms / 887 tokens
三、交叉编译
大模型版本需要在手机上运行时,需要进行交叉编译。编译安卓版本为例。
3.1 安卓命令行版本
项目docs/android.md 有编译说明文档。
3.1.1 编译安卓端命令行
主要的编译步骤:
$ mkdir build-android
$ cd build-android
$ export NDK=<your_ndk_directory>
$ cmake -DCMAKE_INSTALL_PREFIX=./out -DCMAKE_TOOLCHAIN_FILE=$NDK/build/cmake/android.toolchain.cmake -DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=android-23 -DCMAKE_C_FLAGS="-fPIC" ..
$ cmake -DCMAKE_TOOLCHAIN_FILE=$NDK/build/cmake/android.toolchain.cmake -DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=android-23 -DCMAKE_C_FLAGS="-march=armv8.4a+dotprod -fPIC" ..
$ makeexport NDK=<NDK目录>
设置环境变量NDK,指定NDK的目录。
cmake设置cmake相关参数。
以下对cmake的参数说明。
| 参数 | 取值 | 说明 |
| CMAKE_TOOLCHAIN_FILE | NDK的toolchain的cmake文件 | NDK中cmake |
| ANDROID_ABI | 指令集类型,arm64-v8a:arm64位版本 | 指定的指令集类型,2019年以后,推荐使用ARM64版本 |
| ANDROID_PLATFORM | 安卓平台版本 | 安卓平台版本。android-23,目标平台为安卓23 |
| CMAKE_C_FLAGS | 设置了 C 编译器的标志, | 其中 -march=armv8.4a+dotprod 指定了生成的代码将针对 ARMv8.4-A 架构以及 dot product 指令集进行优化。 |
CMake编译器标志设置的常用参数。
| 参数 | 作用 | 备注 |
| -O3 -Wall -Wextra |
| cmake -DCMAKE_C_FLAGS="-O3 -Wall -Wextra" |
| -fPIC | -fPIC 是一个编译选项,通常在编译共享库(shared library)时使用。它表示生成位置无关代码(Position Independent Code),这对于共享库在内存中的加载和重定位非常重要 | 一般交叉编译使用 |
| -march=armv8.4a+dotprod | 指定了生成的代码将针对 ARMv8.4-A 架构以及 dot product 指令集进行优化。 | 一些手机不支持这个优化选项 |
3.1.2 安装命令行
通过上面的编译,得到了编译后的生成物,但是比较分散。是否存在一个安装命令,将执行文件,依赖库、头文件等安装到一个指定目录,方便使用呢?
我们查看项目 build_android/cmake_install.cmake
看到脚本中CMAKE_INSTALL_PREFIX,可以通过指定安装目录进行安装。
# Set the install prefix
if(NOT DEFINED CMAKE_INSTALL_PREFIX)
set(CMAKE_INSTALL_PREFIX "/Users/zhouronghua/WORK/DEV/projects/llama.cpp-master/build-android/out")
endif()
string(REGEX REPLACE "/$" "" CMAKE_INSTALL_PREFIX "${CMAKE_INSTALL_PREFIX}")因此,执行cmake的时候,可以设置安装目录
$ cmake -DCMAKE_INSTALL_PREFIX=./out -DCMAKE_TOOLCHAIN_FILE=$NDK/build/cmake/android.toolchain.cmake -DANDROID_ABI=arm64-v8a -DANDROID_PLATFORM=android-23 -DCMAKE_C_FLAGS="-fPIC" ..
$ make编译完成,执行安装命令即可。
$ make install会安装到项目的指定路径:项目/build-android/out目录中。

安装后的目录中包含可执行文件 bin文件,头文件 include,库文件: lib
生成的命令行执行文件中,llama-cli 是安卓命令行测试工具。
3.1.3 安卓命令行安装
命令行安装测试的步骤:
1)安装模型;
2)安卓可执行文件;
3)修改可执行文件权限;
4)执行推理命令
我们可以根据实际情况,安装命令行。我们可以编写安装脚本build_llama_runner.sh。
set -x
# Build
#ndk-build -j 8 APP_BUILD_SCRIPT=jni/Android_llava.mk
# Setup phone environment
PHONE_PATH=/data/local/tmp/llamacpp
# Setup phone environment
BIN_PATH=/data/local/tmp/llamacpp/bin
# Model path
MODEL_PATH=/data/local/tmp/llamacpp/models
adb shell mkdir -p $PHONE_PATH
adb shell mkdir -p $BIN_PATH
adb shell mkdir -p $MODEL_PATH
# Push built binaries
adb push bin $PHONE_PATH
# install model
adb push models/MiniCPM-0-2-Q4_K.gguf $MODEL_PATH
# install library
adb push arm64-v8a/* $PHONE_PATH
# Set execute permission
adb shell "chmod +x $BIN_PATH/*"注:我们将需要安装的文件进行整理,可执行文件放在bin目录下,库文件放在arm64-v8a目录下,
模型文件放下models目录下。安装的时候,比较方便。
 bin目录下的文件:对应 项目/build-android/out/bin 下的可执行文件
bin目录下的文件:对应 项目/build-android/out/bin 下的可执行文件
arm64-v8a:对应 项目/build-android/out/lib 下的库文件。libomp.so这个库文件怎么来的,后面会进行说明。
models: 推理使用的模型文件。

3.1.4 命令行测试
安装完成以后,可以进行测试。
编写脚本 run_mincpm_1b.sh ,方便执行。
set -x
# model file
MODEL_FILE=MiniCPM-0-2-Q4_K.gguf
#MODEL_FILE=minCPM-2-Q4_1.gguf
# Setup phone environment
PHONE_PATH=/data/local/tmp/llamacpp
# Model path(模型文件安装目录)
MODEL_PATH=/data/local/tmp/llamacpp/models
# prompt
PROMPT="<user>北京有什么好玩的地方<AI>"
# Set execute permission
adb shell "chmod +x $PHONE_PATH/bin/llama-cli"
# Run using the below commands
adb shell "LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PHONE_PATH $PHONE_PATH/bin/llama-cli -m $MODEL_PATH/$MODEL_FILE --prompt \"$PROMPT\"" -t 4
adb shell "LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PHONE_PATH $PHONE_PATH/bin/llama-cli -m $MODEL_PATH/$MODEL_FILE --prompt \"$PROMPT\"" -t 6
可以看到命令行输出结果则成功。
3.1.5 命令行执行常见错误
1. 命令行执行提示缺少 libomp.so 库
library "libomp.so" not found: needed by /data/local/tmp/llamacpp/libggml.so这个错误提示表明在加载 libggml.so 库时,系统无法找到所需的 libomp.so 库。这通常是由于缺少 OpenMP 库导致的问题。OpenMP 是一种支持多线程编程的标准,而 libomp.so 是 OpenMP 库的动态链接库文件。
怎么找到libomp.so 库呢?
需要从NDK的库中查找,一般的NDK都自带了这个库。
在NDK根目录,搜索“libomp.so”,就能找到,。

3.2 JNI编译
JNI编译提供有两种方式,一种是源码依赖,将需要的C++代码都编译到目标so库中。
第二种方式是库以来,直接使用编译生成的库进行链接。
3.2.1 源码依赖
项目中提供了源码依赖的demo工程。
项目/examples/llama.android 这个是demo工程。

项目包含两个module:
-llama: JNI封装库
-app: Demo项目
3.2.1.1 JNI编译
我们看 项目/llama/src/main/cpp/CMakeLists.txt 编译脚本,
# For more information about using CMake with Android Studio, read the
# documentation: https://d.android.com/studio/projects/add-native-code.html.
# For more examples on how to use CMake, see https://github.com/android/ndk-samples.
# Sets the minimum CMake version required for this project.
cmake_minimum_required(VERSION 3.22.1)
# Declares the project name. The project name can be accessed via ${ PROJECT_NAME},
# Since this is the top level CMakeLists.txt, the project name is also accessible
# with ${CMAKE_PROJECT_NAME} (both CMake variables are in-sync within the top level
# build script scope).
project("llama-android")
#include(FetchContent)
#FetchContent_Declare(
# llama
# GIT_REPOSITORY https://github.com/ggerganov/llama.cpp
# GIT_TAG master
#)
# Also provides "common"
#FetchContent_MakeAvailable(llama)
# Creates and names a library, sets it as either STATIC
# or SHARED, and provides the relative paths to its source code.
# You can define multiple libraries, and CMake builds them for you.
# Gradle automatically packages shared libraries with your APK.
#
# In this top level CMakeLists.txt, ${CMAKE_PROJECT_NAME} is used to define
# the target library name; in the sub-module's CMakeLists.txt, ${PROJECT_NAME}
# is preferred for the same purpose.
#
#load local llama.cpp
add_subdirectory(../../../../../../ build-llama)
# In order to load a library into your app from Java/Kotlin, you must call
# System.loadLibrary() and pass the name of the library defined here;
# for GameActivity/NativeActivity derived applications, the same library name must be
# used in the AndroidManifest.xml file.
add_library(${CMAKE_PROJECT_NAME} SHARED
# List C/C++ source files with relative paths to this CMakeLists.txt.
llama-android.cpp)
# Specifies libraries CMake should link to your target library. You
# can link libraries from various origins, such as libraries defined in this
# build script, prebuilt third-party libraries, or Android system libraries.
target_link_libraries(${CMAKE_PROJECT_NAME}
# List libraries link to the target library
llama
common
android
log)add_subdirectory添加的是项目的源码目录,采用源码编译。
1)当前编译的so库是:libllama-android.so
2)需要依赖的编译目录:项目
3)链接需要的依赖库:libllama.so、libcommon.a、安卓项目依赖库:libandroid.so、liblog.so
3.2.1.2 libllama.so编译规则
项目/src/CMakeLists.txt 编译脚本
# TODO: should not use this
if (WIN32)
if (BUILD_SHARED_LIBS)
set(CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS ON)
endif()
endif()
#
# libraries
#
# llama(目标包含的源文件)
add_library(llama
../include/llama.h
llama.cpp
llama-vocab.cpp
llama-grammar.cpp
llama-sampling.cpp
unicode.h
unicode.cpp
unicode-data.cpp
)
# libllama.so的头文件目录
target_include_directories(llama PUBLIC . ../include)
target_compile_features (llama PUBLIC cxx_std_11) # don't bump
# libllama.so的链接依赖库
target_link_libraries(llama PUBLIC ggml)
# 编译选项设置
if (BUILD_SHARED_LIBS)
set_target_properties(llama PROPERTIES POSITION_INDEPENDENT_CODE ON)
target_compile_definitions(llama PRIVATE LLAMA_SHARED LLAMA_BUILD)
endif()
3.2.2 库依赖
通过3.1.3 我们了解了引用 llama.cpp需要的库和头文件,因此可以通过采用 依赖库+头文件的方式,直接进行依赖呢?
这种方法也是可以的。
1)引用头文件;
2)引用依赖库;
3)编写jni调用接口;
4)配置cmake
新建模块llamatextlib
3.2.2.1 引入头文件
llamatextlib/src/main/cpp/include
将头文件导入到此目录下。

3.2.2.2 引入依赖库
llamatextlib/src/main/jniLibs/arm64-v8a 下,添加需要依赖的库文件。因为安卓主要支持arm64-v8a。我们统一采用 arm64-v8a版本。

3.2.2.3 编写JNI调用接口
JNI接口可以参考 exsamples的Demo程序。
JNI调用接口,主要有3个:
1)加载模型:参数为模型路径
2)发送prompt,轮询获取推理结果;
3)卸载模型。
/**
* 加载模型
*
* @param pathToModel 模型文件路径
* @author zhouronghua
* @time 2024/9/24 19:30
*/
override suspend fun load(pathToModel: String, extraInfo: Map<String, String>?) {
withContext(runLoop) {
when (threadLocalState.get()) {
is State.Idle -> {
// 开始加载模型时间
val t1 = System.currentTimeMillis()
// 以下是模型加载处理
val model = load_model(pathToModel)
if (model == 0L) throw IllegalStateException("load_model() failed")
val context = new_context(model)
if (context == 0L) throw IllegalStateException("new_context() failed")
val batch = new_batch(512, 0, 1)
if (batch == 0L) throw IllegalStateException("new_batch() failed")
val sampler = new_sampler()
if (sampler == 0L) throw IllegalStateException("new_sampler() failed")
Log.i(tag, "Loaded model $pathToModel")
threadLocalState.set(State.Loaded(model, context, batch, sampler))
// 模型加载完成
val t2 = System.currentTimeMillis()
llmMessagePublisher?.publish(
LlmMetricMessage(
LlmMetricType.ModelLoaded,
(t2 - t1).toDouble()
)
)
}
else -> throw IllegalStateException("Model already loaded")
}
}
}发送prompt: completion_init
轮询推理结果:completion_loop
/**
* 发送提问
*
* @param message 提问内容
* @author zhouronghua
* @time 2024/9/24 20:03
*/
override fun send(message: String, endCallback: ((Boolean) -> Unit)?): Flow<String> = flow {
// 重置当次推测暂停状态
isPause.set(false)
when (val state = threadLocalState.get()) {
is State.Loaded -> {
// 开始时间
val t1 = System.currentTimeMillis()
// 当前token数
val ncur =
IntVar(completion_init(state.context, state.batch, "<user>$message<AI>", nlen))
// 计算初始的token数
val oldTokenCount = ncur.value
// 是否是首响token
var isFirst = true
while (ncur.value <= nlen) {
// 依次获取推测内容分段
if (isPause.get()) {
// 如果设置暂停则结束当次推测
break
}
// 轮询遍历获取流式内容
val str = completion_loop(state.context, state.batch, state.sampler, nlen, ncur)
if (str == null) {
break
}
if (isFirst) {
// 首响通知
val t2 = System.currentTimeMillis()
llmMessagePublisher?.publish(
LlmMetricMessage(
LlmMetricType.FirstTokenGenerated,
(t2 - t1).toDouble()
)
)
isFirst = false
}
if (str == null || str == "\n\n\n\n") {
Log.e(tag, "out str == null or eos , break")
break
}
// 发射当前的增量内容
if (!isPause.get()) {
emit(str)
}
}
// 清理缓存空间
kv_cache_clear(state.context)
// 统计消息发送结束
val t3 = System.currentTimeMillis()
llmMessagePublisher?.publish(
LlmMetricMessage(
LlmMetricType.GenerationFinished,
(t3 - t1).toDouble()
)
)
// token生成速度
llmMessagePublisher?.publish(
LlmMetricMessage(
LlmMetricType.GenerationSpeed,
(ncur.value - oldTokenCount).toDouble() / (t3 - t1) * 1000
)
)
// 通知用户智能体回复已经结束
endCallback?.invoke(true)
}
else -> {
// 通知用户智能体回复已经结束
endCallback?.invoke(false)
}
}
}.flowOn(runLoop)卸载模型:
/**
* Unloads the model and frees resources.
*
* This is a no-op if there's no model loaded.
*/
override suspend fun unload() {
withContext(runLoop) {
when (val state = threadLocalState.get()) {
is State.Loaded -> {
free_context(state.context)
free_model(state.model)
free_batch(state.batch)
free_sampler(state.sampler)
threadLocalState.set(State.Idle)
}
else -> {}
}
}
}其余的是一些JNI 接口函数
private external fun log_to_android()
private external fun load_model(filename: String): Long
private external fun free_model(model: Long)
private external fun new_context(model: Long): Long
private external fun free_context(context: Long)
private external fun backend_init(numa: Boolean)
private external fun backend_free()
private external fun new_batch(nTokens: Int, embd: Int, nSeqMax: Int): Long
private external fun free_batch(batch: Long)
private external fun new_sampler(): Long
private external fun free_sampler(sampler: Long)
private external fun bench_model(
context: Long,
model: Long,
batch: Long,
pp: Int,
tg: Int,
pl: Int,
nr: Int
): String
private external fun system_info(): String
private external fun completion_init(
context: Long,
batch: Long,
text: String,
nLen: Int
): Int
private external fun completion_loop(
context: Long,
batch: Long,
sampler: Long,
nLen: Int,
ncur: IntVar
): String?
private external fun kv_cache_clear(context: Long)3.2.2.4 编写CMakeList.txt
cmake文件与源码编译类似,不过依赖的头文件和库文件有些不同。
# For more information about using CMake with Android Studio, read the
# documentation: https://d.android.com/studio/projects/add-native-code.html.
# For more examples on how to use CMake, see https://github.com/android/ndk-samples.
# Sets the minimum CMake version required for this project.
cmake_minimum_required(VERSION 3.22.1)
# Declares the project name. The project name can be accessed via ${ PROJECT_NAME},
# Since this is the top level CMakeLists.txt, the project name is also accessible
# with ${CMAKE_PROJECT_NAME} (both CMake variables are in-sync within the top level
# build script scope).
# llama文本推理库
project("llamatext")
# cmake 自带变量 设置编译类型为release
set(CMAKE_BUILD_TYPE Release)
# 设置 C++ 编译器标志
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fPIC")
# 编译目标库
add_library(${CMAKE_PROJECT_NAME} SHARED
# List C/C++ source files with relative paths to this CMakeLists.txt.
llama-android.cpp)
# 设置 目标库依赖的头文件
target_include_directories(${CMAKE_PROJECT_NAME} PUBLIC
${USER_LOCAL_C_INCLUDES}
./include
)
# Specifies libraries CMake should link to your target library. You
# can link libraries from various origins, such as libraries defined in this
# build script, prebuilt third-party libraries, or Android system libraries.
target_link_libraries(${CMAKE_PROJECT_NAME}
# List libraries link to the target library
llama
common
ggml
android
log)
# 添加依赖库目标
add_library(common STATIC IMPORTED)
add_library(llama SHARED IMPORTED)
add_library(ggml SHARED IMPORTED)
# 依赖库标目属性
set_target_properties(
common
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libcommon.a
)
set_target_properties(
llama
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libllama.so
)
set_target_properties(
ggml
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libggml.so
)头文件:指向导入的include目录
库文件:依赖库的都是通过 IMPORT进行依赖。
common库,指向jniLibs下的静态依赖库。
# 依赖库标目属性
set_target_properties(
common
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libcommon.alibllama.so指向jniLibs下的对应库
set_target_properties(
llama
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libllama.so
)libggml.so指向jniLibs下的依赖库。
set_target_properties(
ggml
PROPERTIES IMPORTED_LOCATION
${CMAKE_SOURCE_DIR}/../jniLibs/arm64-v8a/libggml.so
)这样,就通过库以来集成了llama.cpp。如果有版本更新,编译生成新的so库,替换更新就行。
参考文献:
1.《大模型推理--KV Cache》

















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









