






万字总结随机森林原理、核心参数以及调优思路
在机器学习的世界里,随机森林(Random Forest, RF)以其强大的预测能力和对数据集的鲁棒性而备受青睐。作为一种集成学习方法,随机森林通过构建多个决策树并将它们的预测结果进行汇总,以提高模型的准确性和泛化能力。然而,要充分发挥随机森林的潜力,合理地调整其核心参数至关重要。本文将深入探讨随机森林的关键参数,包括树的数量、分裂标准、最大深度等,并提供实用的调优思路。
文章目录
一、随机森林实现原理
随机森林(Bagging最为代表性的算法)是机器学习领域最常用的算法之一,其算法构筑过程非常简单:从提供的数据中随机抽样出不同的子集,用于建立多棵不同的决策树,并按照Bagging的规则对单棵决策树的结果进行集成(回归则平均,分类则少数服从多数)。
虽然原理上很简单,但随机森林的学习能力异常强大、算法复杂度高、又具备一定的抗过拟合能力,是从根本上来说比单棵决策树更优越的算法。即便在深入了解机器学习的各种技巧之后,它依然是现阶段能够使用的最强大的算法之一。原理如此简单、还如此强大的算法在机器学习的世界中是不常见的。在机器学习竞赛当中,随机森林往往是在中小型数据上会尝试的第一个算法,同时也是提交的备选之一。
在sklearn中,随机森林可以实现回归也可以实现分类。随机森林回归器由类sklearn.ensemble.RandomForestRegressor实现,随机森林分类器则有类sklearn.ensemble.RandomForestClassifier实现。可以像调用逻辑回归、决策树等其他sklearn中的算法一样,使用“实例化、fit、predict/score”三部曲来使用随机森林,同时也可以使用sklearn中的交叉验证方法来实现随机森林。其中回归森林的默认评估指标为R2,分类森林的默认评估指标为准确率。
二、RandomForestRegressor的实现以及注意事项
注意事项:
-
对于回归模型,要先看一下标签的范围、分布以及均值等情况,以此预估MSE的大致取值范围,一般认为MSE远小于均值(3倍及以上),模型训练效果较为不错。
-
另一种较为常用的评估方法是将RMSE相对于标签列均值的比率进行评估,这种比率有时候被称为标准化RMSE(NRMSE)
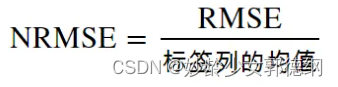
这个比率可以帮助我们理解模型的误差相对于数据的平均水平的大小。对于一个好的回归模型,通常我们希望这个比率尽可能低。在不同的领域和应用中,"好"的NRMSE标准可能不同,但这里有一些一般性的指导原则:-
NRMSE < 10%:通常被认为是很好的模型,意味着误差较小。
-
NRMSE 在 10% 到 20% 之间:可以视为一个合理的模型,尤其是在数据变异性较大的情况下。
-
NRMSE > 20%:可能表示模型有改进的空间,误差相对较大。
-
-
最后一种比较常用的评估方案是设置Baseline(基线模型),计算基线模型的RMSE值,如果模型的损失值小于基线模型的损失值,则认为效果比较不错,否认,认为效果一般。
三、随机森林核心参数
3.1 弱评估器结构
在集成算法当中,控制单个弱评估器的结构是一个重要的课题,因为单个弱评估器的复杂度/结果都会影响全局,其中单棵决策树的结构越复杂,集成算法的整体复杂度会更高,计算会更加缓慢、模型也会更加容易过拟合,因此集成算法中的弱评估器也需要被剪枝。随机森林回归器的弱评估器是回归树,因此集成评估器中有大量的参数都与弱评估器回归树中的参数重合。

分枝标准与特征重要性(criterion与feature_importances_)
与分类树中的信息熵/基尼系数不同,回归树中的criterion可以选择"squared_error"(平方误差),“absolute_error”(绝对误差)以及"poisson"(泊松偏差)。

其中平方误差与绝对误差是大家非常熟悉的概念,作为分枝标准,平方误差比绝对误差更敏感(类似于信息熵比基尼系数更敏感),并且在计算上平方误差比绝对误差快很多。泊松偏差则是适用于一个特殊场景的(泊松分布是正整数的分布):当需要预测的标签全部为正整数时,标签的分布可以被认为是类似于泊松分布的。 正整数预测在实际应用中非常常见,比如预测点击量、预测客户/离职人数、预测销售量等。
另外,当选择不同的criterion之后,决策树的feature_importances_(特征重要性)也会随之变化,因为在sklearn当中,feature_importances_是特征对criterion下降量的总贡献量,因此不同的criterion可能得到不同的特征重要性(选择泊松偏差特征重要性相比平方误差和绝对误差可能会有比较大的偏差)。
对绝大多数情况来说,选择criterion的唯一指标就是最终的交叉验证结果(交叉验证的优先级要优于验证集的结果)——无论理论是如何说明的,只取令随机森林的预测结果最好的criterion。

3.2 弱评估器数量(n_estimators)
n_estimators是森林中树木的数量,即弱评估器的数量,在sklearn中默认100,它是唯一一个对随机森林而言必填的参数。n_estimators对随机森林模型的精确程度、复杂度、学习能力、过拟合情况、需要的计算量和计算时间都有很大的影响,因此n_estimators往往是我们在调整随机森林时第一个需要确认的参数(网格搜索时也是第一个需要确认参数空间的参数)。对单一决策树而言,模型复杂度由树结构(树深、树宽、树上的叶子数量等)与数据量(样本量、特征量)决定,而对随机森林而言,模型复杂度由森林中树的数量、树结构与数据量决定,其中树的数量越多,模型越复杂。
n_estimators越大,模型的学习能力越强,但却并不是n_estimators越大越好,当n_estimators越大时(模型效果先提高而后急剧下降,趋于平缓/上升,存在非常明显的转折点):模型的复杂程度上升,泛化能先增强再减弱(或不变),模型的学习能力越来越强,在训练集上的分数可能越来越高,过拟合风险越来越高,模型需要的算力和内存越来越多,模型训练的时间会越来越长。
3.3 弱评估器训练的数据
随机森林会从提供的数据中随机抽样出不同的子集,用于建立多棵不同的决策树,最终再按照Bagging的规则对众多决策树的结果进行集成。因此在随机森林回归器的参数当中,有数个关于数据随机抽样的参数。
样本的随机抽样(bootstrap,oob_score,max_samples)

四、随机森林参数空间的确定
完整内容见随机森林参数空间的确定
五、随机森林调优思路
完整内容见随机森林调优思路
六、随机森林面试热点问题
完整内容见随机森林面试热点问题

















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









