







更新 2024-04-07
最近写大论文,对实验参数又有了理解,特来更正一下
下图是我常用的表头,可供参考(因为是中文硕士论文,所以就写成了模型,英文论文的话可以写成Model):

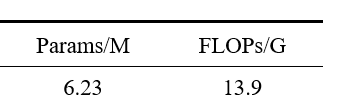
对于我来说,一直拿不准的单位就是参数量(Params)和计算量(FLOPs)。根据看的文献、博客、个人理解,最终确认应该使用图上的M和G单位,分别表示量级单位
1
0
6
10^6
106和
1
0
9
10^9
109。可详见这篇博文:深度学习-参数量&模型大小&理论计算量

我的理解是:实际数据=表格数字×单位
例如下图,Params和FLOPs只是参数量和计算量的代称并不是单位,单位是/后面的内容。那如图所示我的参数量就是6.23M,带上单位的意思就是有 6.23 × 1 0 6 6.23×10^6 6.23×106个参数;计算量就是13.9G,带上单位的意思就是 13.9 × 1 0 9 13.9×10^9 13.9×109个计算
1. 使用thop库打印参数量、计算量
重点参考这个部分:
但是,我认为他的换算方式有误,换算方式应该是:
- 对于参数量
Parameters,统计个数之后,换算成M的含义是million百万,因此换算应该是 1 M = 1 0 6 1M=10^6 1M=106(在代码中 1 0 6 10^6 106通常写成1e6)👉参考链接:数量单位B和M代表多少? - 对于每秒浮点运算次数
FLOPs,换算成GFLIPs的方式是 G F L O P s = 1 0 9 F L O P s GFLOPs=10^9 FLOPs GFLOPs=109FLOPs(在代码中 1 0 9 10^9 109通常写成1e9)👉参考链接:FLOPS每秒浮点运算次数计算公式
import torch
import torchvision
from thop import profile
print('==> Building model..')
model = torchvision.models.alexnet(pretrained=False).cuda() # 如果就把cuda()去掉试试
input = torch.randn(1, 3, 224, 224).cuda() # 如果就把cuda()去掉试试
flops, params = profile(model, (input,))
print('GFLOPs: %.2f B, params: %.2f M' % (flops / 1e9, params / 1e6))
2. 标准图例
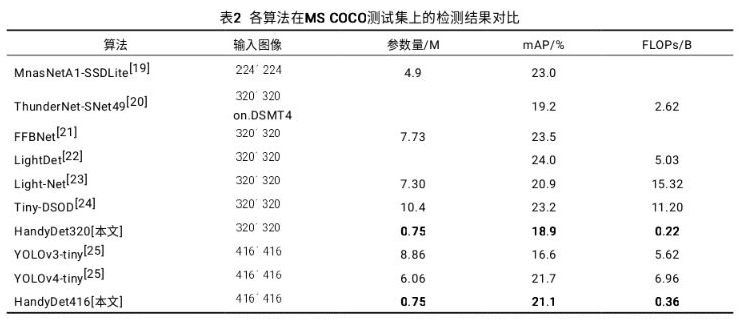
3. 可能有用的YOLO系列模型汇总
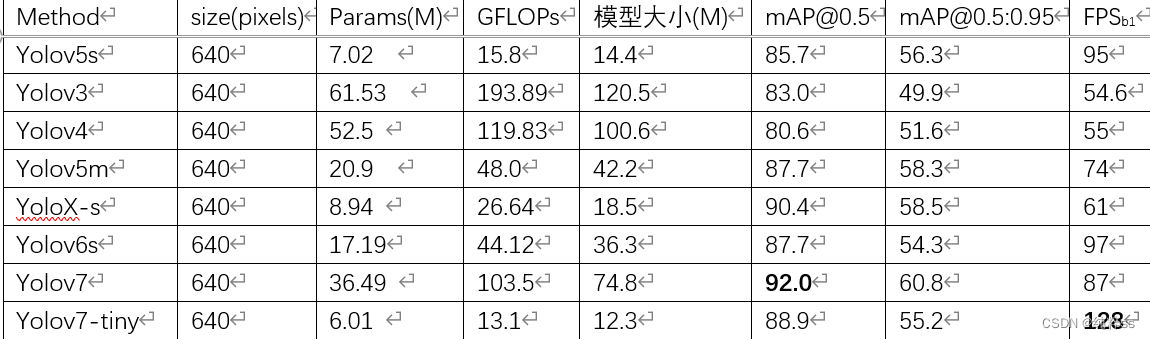
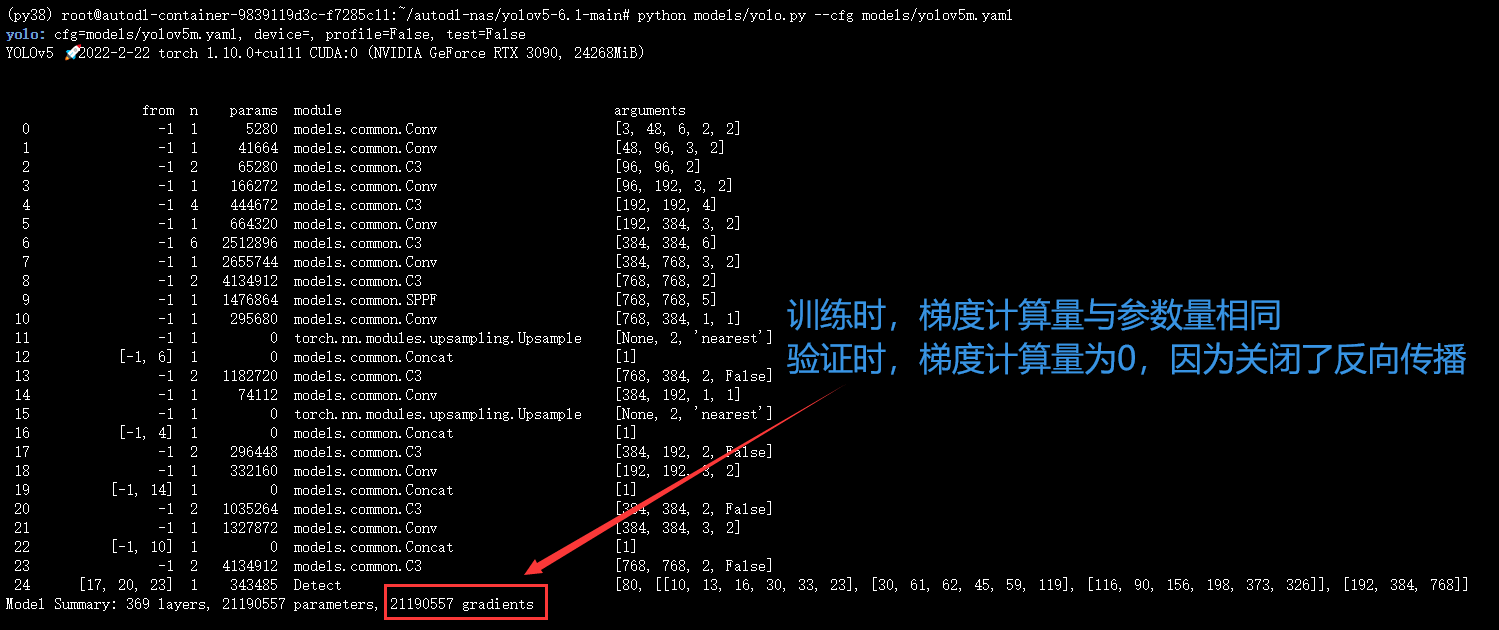
4. 暂存梯度计算量gradients与参数量的关系
图中的话忘记是在哪里看到的了,感觉很有道理的样子hhh~


















 6504
6504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











