






论文地址:https://arxiv.org/pdf/2006.10503.pdf
SE3-Transformers
等变性
等变性(equivariance)指当输入进行某种变化的时候,输出进行相应的变化。完美的物体六维位姿估计具有对输入物体刚性变换(旋转和平移)的等变性,亦即如果对输入物体进行一个刚性变换,输出的位姿应也乘以这个刚性变换矩阵。在有标注的情况下,深度神经网络将依靠标注的引导进行位姿的学习,在训练良好的情况下,该网络近似满足等变性。当没有标注的时候,我们仍然需要获得等变的预测结果,而我们拥有的只有输入数据集,这样我们就考虑使用一个具有等变性的深度神经网络。
摘要
我们引入了SE(3)-Transformer,它是三维点云的自注意模块的一种变体,它在连续的三维旋转平动下是等变的。等变性对于确保在数据输入存在有害转换时的稳定和可预测的性能非常重要。 等变性 的一个积极的推论是增加了模型内的权重绑定,从而减少了可训练参数的数目,以此降低了样本的复杂性(即我们需要更少的训练数据)。SE(3)-Transformer利用自注意的好处,在具有不同数量点的大点云上操作,同时保证SE(3)-等变性的鲁棒性。我们在一个小N体粒子模拟数据集上评估我们的模型,展示了在输入旋转情况下预测的稳健性。
背景以及相关工作
一、自注意力机制(The Attention Mechanism)
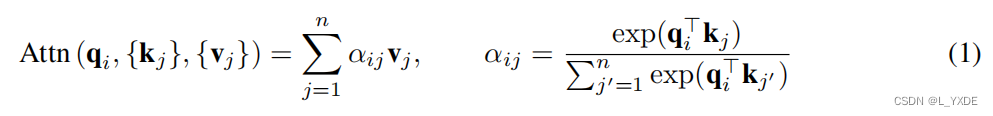 假设有
n
n
n个向量
{
x
i
}
i
=
1
n
\{x_i\}^n_{i=1}
{xi}i=1n,
α
i
j
\alpha_{ij}
αij相当于
x
i
x_i
xi和
x
j
x_j
xj的相关性。
A
t
t
n
(
Q
,
K
,
V
)
Attn(Q,K,V)
Attn(Q,K,V),把注意力放在相关性更高的向量上。与CNN不同的是,CNN只考虑了一个卷积核内的相关性,而self-attention则考虑了全局的相关性。
假设有
n
n
n个向量
{
x
i
}
i
=
1
n
\{x_i\}^n_{i=1}
{xi}i=1n,
α
i
j
\alpha_{ij}
αij相当于
x
i
x_i
xi和
x
j
x_j
xj的相关性。
A
t
t
n
(
Q
,
K
,
V
)
Attn(Q,K,V)
Attn(Q,K,V),把注意力放在相关性更高的向量上。与CNN不同的是,CNN只考虑了一个卷积核内的相关性,而self-attention则考虑了全局的相关性。
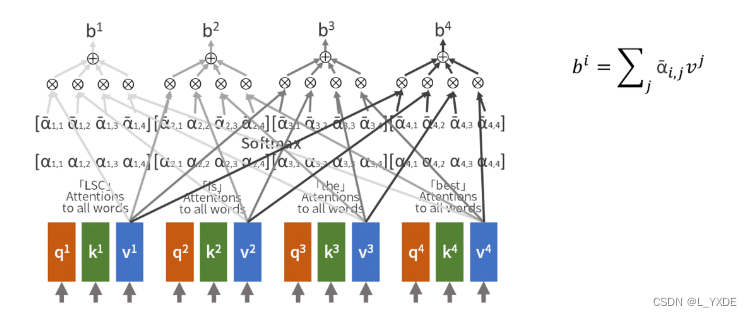
排列等变性(Permutation equivariance)
self-attenton的一个关键性质是排列等变性。点标签 1 、 . . . , n 1、...,n 1、...,n的排列导致了self-attenton输出的排列。这就保证了self-attenton的输出不会任意依赖于输入点的排序。瓦格斯塔夫等人,[30]最近表明,这种机制在理论上可以近似于所有的排列等变函数。SE(3)-Transformer是这种注意机制的一种特殊情况,继承了排列等变。然而,它限制了可学习函数的空间为旋转和平移等变函数
二、图神经网络(Graph Neural Networks)
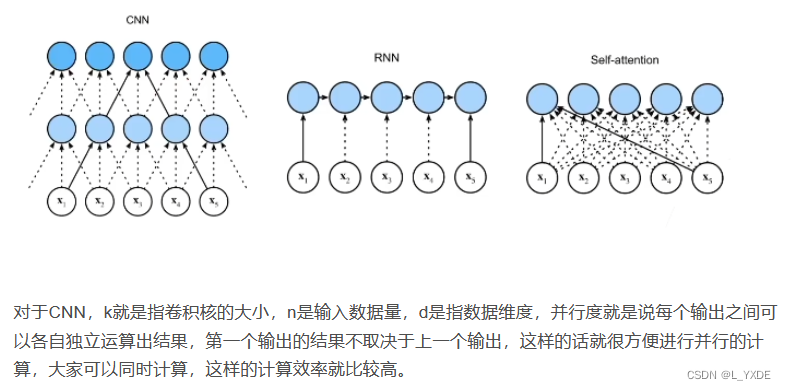
Attention scales与点云大小呈二次关系,因此引入neighbourhoods是有用的:instead of each point attending to all other points, it only attends to its nearest neighbours(不需要关注每一个点,只需要关注它的邻居点)。
具有领域的几何被表示为图(graphs),并且 Attention很早就被引入到Graph。它具有简单的形式:
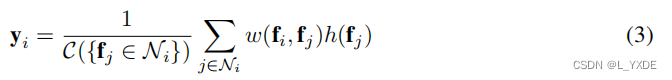


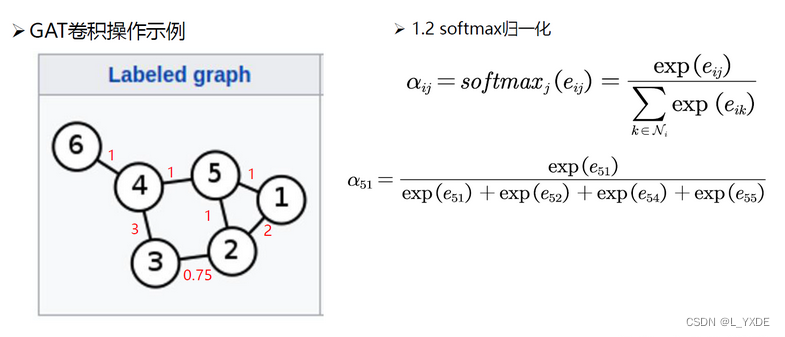
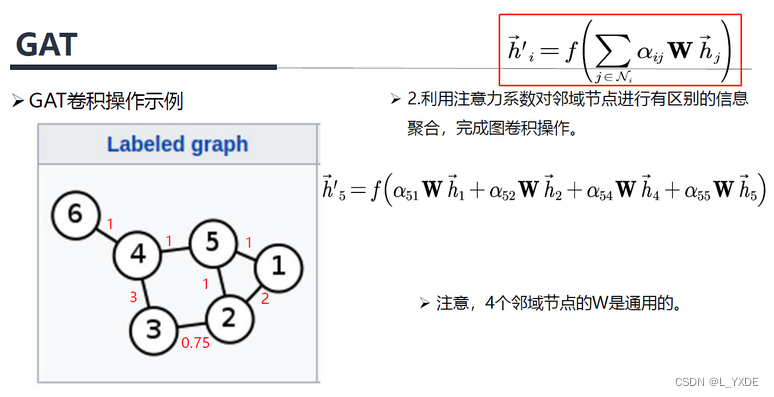
三、等变性( Equivariance)

给定一对
(
T
g
,
S
g
)
(T_g,S_g)
(Tg,Sg),我们可以求解满足方程(4)的等变函数
ϕ
\phi
ϕ族。
在等变性文献中,深度网络是由交错线性映射
ϕ
\phi
ϕ和等变非线性建立的。在三维旋转平移的情况下,已经证明了一个适合
ϕ
\phi
ϕ的结构是一个张量场网络[25],解释如下。请注意,Romero等人[21]最近引入了一个用于基于像素的图像数据的二维旋转平移等变注意模块。
Group Representations
一般来说,
(
T
g
,
S
g
)
(T_g,S_g)
(Tg,Sg)称为group representations。
group representations
ρ
:
G
→
G
L
(
N
)
\rho:G\to GL(N)
ρ:G→GL(N)是
G
G
G到
N
×
N
N\times N
N×N可逆矩阵
G
L
GL
GL的映射。更准确地说,
ρ
\rho
ρ是group homomorphism,因此,它满足以下性质:
ρ
(
g
1
g
2
)
=
ρ
(
g
1
)
(
g
2
)
\rho(g_1g_2)=\rho(g_1)(g_2)
ρ(g1g2)=ρ(g1)(g2),
g
1
,
g
2
∈
G
g_1,g_2\in G
g1,g2∈G
对于三维旋转
G
=
S
O
(
3
)
G=SO(3)
G=SO(3),有以下几个性质:
1)它的表示使正交矩阵;
2)它的表示可以分解为

其中
Q
Q
Q是正交矩阵,
N
×
N
N\times N
N×N的change-of-basis matrix(基的变换矩阵)。
D
l
D_l
Dl是
(
2
l
+
1
)
×
(
2
l
+
1
)
(2l+1)\times (2l+1)
(2l+1)×(2l+1)的Wigner-D矩阵。
⊕
\oplus
⊕表示直和(direct sum)或沿着对角线矩阵连接。
Wigner-D矩阵是
S
O
(
3
)
SO(3)
SO(3)的不可约表示(irreducible representations)——认为他们是可能的最小表示。
根据 D l D_l Dl(设置 Q = I , i = l Q=I,i=l Q=I,i=l)变换的向量称为 type-l 向量。type-0 向量在旋转条件下保持不变,type-1向量根据三维旋转矩阵进行旋转。注意,type-l 向量的长度为 2 l + 1 2l+1 2l+1。它们可以被堆叠起来,形成一个根据等式(5)变换的特征向量 f f f
Tensor Field Networks
张量场网络(TFN)[28]是一种神经网络,它在SE(3)-equivariance约束下将点云映射到点云,即一组三维旋转和平移。对于点云,输入是形式如(6)的向量场
f
:
R
3
→
R
6
f:R^3\to R^6
f:R3→R6

δ
\delta
δ是 Dirac delta function,
{
x
j
}
\{x_j\}
{xj}是3D点坐标,
{
f
j
}
\{f_j\}
{fj}是点特征,表示原子序数或点身份。为了满足等变性,TFN变换的特征基于Eq(5),其中
Q
=
I
Q=I
Q=I。每个
f
i
f_i
fi是不同types向量的串联,type-l的子向量被写成
f
j
l
f^l_j
fjl。
TFN层从type-k特征到type-l特征计算空间中连续的、可学习的权值核
W
l
k
:
R
(
2
l
+
1
)
×
(
2
k
+
1
)
W^{lk}:R^{(2l+1)\times(2k+1)}
Wlk:R(2l+1)×(2k+1)。位置
x
i
x_i
xi的TFN层的type-l输出为:
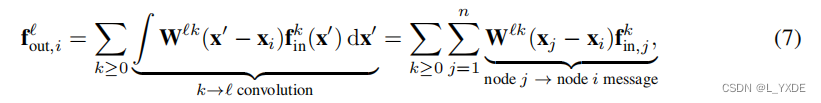
W
l
k
W^{lk}
Wlk位于等变基
{
W
J
l
k
}
J
=
∣
k
−
l
∣
k
+
l
\{W^{lk}_J\}^{k+l}_{J=|k-l|}
{WJlk}J=∣k−l∣k+l的范围内。核是基础核的线性组合,其中半径
∣
∣
x
∣
∣
||x||
∣∣x∣∣的第
J
J
J个系数是一个可学习的函数
φ
J
l
k
:
R
≥
0
→
R
\varphi^{lk}_J:R_{\geq0}\to R
φJlk:R≥0→R。数学形式为
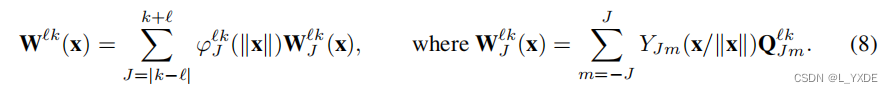 每一个基础核
W
J
l
k
:
R
3
→
R
(
2
l
+
1
)
×
(
2
k
+
1
)
W^{lk}_J:R^3\to R^{(2l+1)\times (2k+1)}
WJlk:R3→R(2l+1)×(2k+1)是由大小为
(
2
l
+
1
)
×
(
2
k
+
1
)
(2l+1)\times (2k+1)
(2l+1)×(2k+1)的ClebschGordan matrices
W
J
m
l
k
W^{lk}_{Jm}
WJmlk的线性组合形成的,其中第
J
m
Jm
Jm个线性组合的系数是第
J
J
J个球谐函数(spherical harmonic)
Y
J
:
R
3
→
R
2
J
+
1
Y_J:R^3\to R^{2J+1}
YJ:R3→R2J+1的第
m
m
m维。
每一个基础核
W
J
l
k
:
R
3
→
R
(
2
l
+
1
)
×
(
2
k
+
1
)
W^{lk}_J:R^3\to R^{(2l+1)\times (2k+1)}
WJlk:R3→R(2l+1)×(2k+1)是由大小为
(
2
l
+
1
)
×
(
2
k
+
1
)
(2l+1)\times (2k+1)
(2l+1)×(2k+1)的ClebschGordan matrices
W
J
m
l
k
W^{lk}_{Jm}
WJmlk的线性组合形成的,其中第
J
m
Jm
Jm个线性组合的系数是第
J
J
J个球谐函数(spherical harmonic)
Y
J
:
R
3
→
R
2
J
+
1
Y_J:R^3\to R^{2J+1}
YJ:R3→R2J+1的第
m
m
m维。
每一个基础核
W
J
l
k
W^{lk}_J
WJlk约束在 angular direction上学习核的形式,在 radial direction上留下唯一可学习的自由度。注意,只有当
k
≠
l
k\neq l
k=l且
J
=
0
J=0
J=0时,
W
J
l
k
(
0
)
≠
0
W^{lk}_J(0)\neq 0
WJlk(0)=0,这将核简化为一个标量
w
w
w乘以恒等式,
W
l
l
=
w
l
l
I
W^{ll}=w^{ll}I
Wll=wllI,称为
s
e
l
f
−
i
n
t
e
r
a
c
t
i
o
n
self-interaction
self−interaction,这样就可以将TFN改写为:
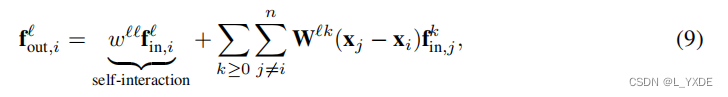
等式(7)和等式(9)以消息传递的形式表示卷积,其中消息从所有节点和特征类型聚合。它们也是等式(3)中非局部图运算的一种形式,其中权值是边上的函数,特征
{
f
i
}
\{f_i\}
{fi}是节点特征。
方法
在这里,我们提出了SE(3)-Transformer。该层可以分解为如图2所示的步骤过程,我们将在下一节中描述。这些就是从点云构造图,构造图上的等变边函数,如何传播 图上的SE(3)-equivariance消息,以及如何聚合它们。我们还引入了自我交互层的另一种选择,我们称之为注意力自我交互(attentive self-interaction)。
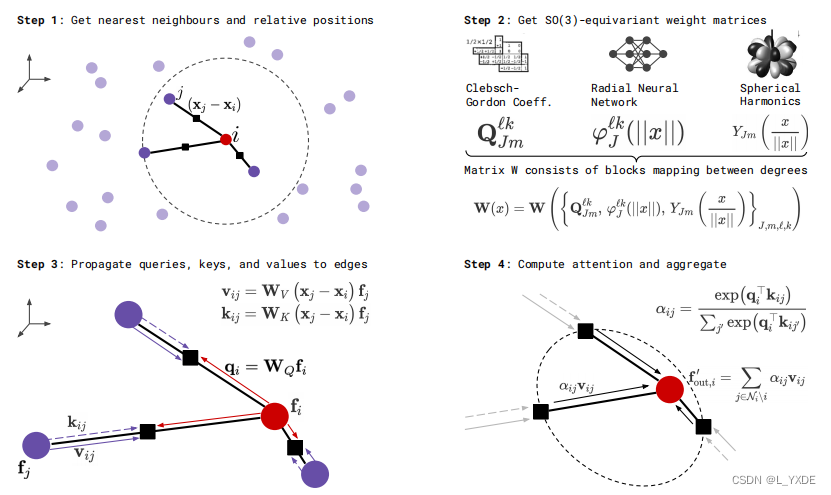
Figure2: 用我们的等变注意机制更新节点特征分四个步骤。附录中提供了更详细的描述,特别是对步骤2的描述。步骤3和步骤4将图形网络视角可视化:特征从节点传递到边,以旋转等变的方式计算键、查询和值,这些都依赖于特征和相对位置。
3.1 Neighbourhoods
给定点云 { ( x i , f i ) } \{(x_i,f_i)\} {(xi,fi)},我们首先引入一个邻居 N i ⊆ { 1 , . . . , N } \mathcal{N}_i\subseteq\{1,...,N\} Ni⊆{1,...,N}的集合,以每个点 i i i为中心。这些邻域要么通过最近的邻域方法计算,要么已经定义了。例如,分子结构的邻域是由它们的键合结构确定的。邻域将注意力机制的计算复杂度从点数的二次型降低到线性型。邻域的引入将点云转化为图。该步骤如图2中的步骤1所示。
3.2 The SE(3)-Transformer
SE(3)-Transformer本身由三个组件组成:
- edge-wise attention weights α i j \alpha_{ij} αij , constructed to be SE(3)-invariant on each edge i j ij ij,
- edge-wise SE(3)-equivariant value messages,propagating information between nodes, as found in the TFN convolution of Eq. (7)
- a linear/attentive self-interaction layer.

3.3 Node and Edge Features
4 A Group Theory and Tensor Field Networks
4.1 Groups
群是一个抽象的数学概念。形式上,一个群 ( G , ∘ ) (G,\circ) (G,∘)由一个集合 G ) G) G)和一个二进制组合运算符 ∘ : G × G → G \circ:G \times G→G ∘:G×G→G组成(通常我们只使用符号 G G G来表示群)。所有的群都必须遵守以下4个公理:
封闭性:任意 g , h ∈ G g,h\in G g,h∈G,满足 g ∘ h ∈ G g\circ h\in G g∘h∈G
结合律:任意 g , h , f ∈ G g,h,f\in G g,h,f∈G,满足 g ∘ ( h ∘ f ) = ( g ∘ h ) ∘ f g\circ (h\circ f)=(g\circ h)\circ f g∘(h∘f)=(g∘h)∘f
幺元:任意 g ∈ G g\in G g∈G,存在 e ∈ G e\in G e∈G,使得 g ∘ e = e ∘ g g\circ e=e\circ g g∘e=e∘g
逆元:任意 g ∈ G g\in G g∈G,存在 g − 1 ∈ G g^{-1}\in G g−1∈G,使得 g ∘ g − 1 = g − 1 ∘ g g\circ g^{-1}=g^{-1}\circ g g∘g−1=g−1∘g
4.2 Actions/Transformations
用群描述变换, T g : X → X T_g:X\to X Tg:X→X是一个自身到自身的变换。
举例: x ∈ X , T g ( x ) = g x + g , g ∈ G = 1 , 2 , 3 x\in X,T_g(x)=gx+g,g\in G={1, 2,3} x∈X,Tg(x)=gx+g,g∈G=1,2,3,则 T 1 ( x ) = x + 1 , T 2 ( x ) = 2 x + 2 , T 3 ( x ) = 3 x + 3 T_1(x)=x+1,T_2(x)=2x+2,T_3(x)=3x+3 T1(x)=x+1,T2(x)=2x+2,T3(x)=3x+3
4.3 Equivariance and Intertwiners
给定两组变换:
T
g
:
X
→
X
,
g
∈
G
T_g:X\to X,g\in G
Tg:X→X,g∈G
S
g
:
Y
→
X
,
g
∈
G
S_g:Y\to X,g\in G
Sg:Y→X,g∈G
函数
f
:
X
→
Y
f:X\to Y
f:X→Y
如果
S
g
[
f
(
x
)
]
=
f
(
T
g
[
x
]
)
S_g[f(x)]=f(T_g[x])
Sg[f(x)]=f(Tg[x]),则称
f
f
f对
g
g
g是等变的。
T g T_g Tg和 S g S_g Sg是不同的变换,但他们的参数都由 g g g决定。比如: T g ( x ) = g x + g T_g(x)=gx+g Tg(x)=gx+g和 S g = g y S_g=gy Sg=gy。
放在本文中,可以将 x x x看做输入点云的特征, T g Tg Tg看成对 x x x施加一个参数为 g g g的变换; f f f表示对 x x x提取特征, S g Sg Sg看成施对 y y y施加一个参数为 g g g的变换
如果映射 f f f是线性的和等变的,则称之为Intertwiners
现提出两个问题:
1)如何选择
S
g
S_g
Sg
2)已知
(
T
g
,
S
g
)
(T_g,S_g)
(Tg,Sg)如何求解
f
f
f?
回答这些问题,需要了解群表示
4.4 Representations
G
L
(
V
)
GL(V)
GL(V)是一个可逆线性变换群,
v
∈
G
L
(
V
)
v\in GL(V)
v∈GL(V),说明
v
v
v是一个可逆矩阵。
A group representation
ρ
:
G
→
G
L
(
V
)
\rho:G\to GL(V)
ρ:G→GL(V),如果
ρ
(
g
1
,
g
2
)
=
ρ
(
g
1
)
ρ
(
g
2
)
\rho (g_1,g_2)=\rho(g_1) \rho(g_2)
ρ(g1,g2)=ρ(g1)ρ(g2),则称群表示
ρ
\rho
ρ是群
G
G
G到群
G
L
(
V
)
GL(V)
GL(V)的同态映射(简称同态),也称
ρ
\rho
ρ是
G
G
G的一个线性表示,
V
V
V为表示空间。
如果 ρ ′ ( g ) = Q − 1 ρ ( g ) Q , g ∈ G \rho^{\prime}(g)=Q^{-1}\rho(g)Q,g\in G ρ′(g)=Q−1ρ(g)Q,g∈G,则 ρ \rho ρ与 ρ ′ \rho^{\prime} ρ′等价(equivalent)
等价的表示:
在表示中,如果相同维数的两个表示 ρ \rho ρ和 ρ ′ \rho^{\prime} ρ′可以通过相似变换连接,则称为等价的。可以想象线性空间中的不同的两组基, Q Q Q相当于两个基的过渡矩阵。说明 A A A和 B B B是同一个变换在不同基的表示
除了三维旋转矩阵,
S
O
(
3
)
S O(3)
SO(3) 群具有多种表示
我们也说一个群表示是可约的,如果它可以写成
ρ
(
g
)
=
Q
−
1
(
ρ
1
(
g
)
⊕
ρ
2
(
g
)
)
Q
=
Q
−
1
[
ρ
1
(
g
)
ρ
2
(
g
)
]
Q
,
for all
g
∈
G
\rho(g)=\mathbf{Q}^{-1}\left(\rho_1(g) \oplus \rho_2(g)\right) \mathbf{Q}=\mathbf{Q}^{-1}\left[\begin{array}{cc} \rho_1(g) & \\ & \rho_2(g) \end{array}\right] \mathbf{Q}, \quad \text { for all } g \in G
ρ(g)=Q−1(ρ1(g)⊕ρ2(g))Q=Q−1[ρ1(g)ρ2(g)]Q, for all g∈G
如果群表示 ρ 1 \rho_1 ρ1和 ρ 2 \rho_2 ρ2是不可约的,那么它们被称为 G G G的不可约群表示。从某种意义上说,它们是表征之间的原子,所有其他表征都可以由它们构成。注意,每个不可约群表示作用于一个单独的子空间,将该空间的向量映射回子空间。我们说子空间 X ℓ ∈ X \mathcal{X}_{\ell} \in \mathcal{X} Xℓ∈X在不可约群表示 ρ ℓ \rho_{\ell} ρℓ下是不变的,如果 { ρ ℓ ( g ) x ∣ x ∈ X ℓ , g ∈ G } ⊆ X ℓ \left\{\rho_{\ell}(g) \mathbf{x} \mid \mathbf{x} \in \mathcal{X}_{\ell}, g \in G\right\} \subseteq \mathcal{X}_{\ell} {ρℓ(g)x∣x∈Xℓ,g∈G}⊆Xℓ
4.5 Representation theory of SO(3)
群 S O ( 3 ) SO(3) SO(3)的群表示理论表明,所有紧致群线性群表示都可以分解为不可约群表示的直和,如
ρ ( g ) = Q ⊤ [ ⨁ J D J ( g ) ] Q , \rho(g)=\mathbf{Q}^{\top}\left[\bigoplus_J \mathbf{D}_J(g)\right] \mathbf{Q} , ρ(g)=Q⊤[J⨁DJ(g)]Q,
其中 Q \mathbf{Q} Q是一个正交矩阵, N × N N \times N N×N,基的变换矩阵
Q Q Q相当于两个基的过渡矩阵
每个 D J \mathbf{D}_J DJ for J = 0 , 1 , 2 , … J=0,1,2,\ldots J=0,1,2,…是一个 ( 2 J + 1 ) × ( 2 J + 1 ) (2 J+1) \times(2 J+1) (2J+1)×(2J+1)矩阵,称为Wigner-D矩阵。
Wigner D-矩阵就是卷积过程中SO(3)群的基底,相当于基础的傅里叶变换中的sin 和cos
Wigner-D矩阵是 S O ( 3 ) S O(3) SO(3)的不可约表示。根据 D J \mathbf{D}_J DJ(即我们设置 Q = I \mathbf{Q}=\mathbf{I} Q=I)变换的向量称为type- J J J向量。
如:
4阶方阵 ρ ( g ) \rho(g) ρ(g) 对4维向量的作用,分解成1阶方阵 D 0 ( g ) D_0(g) D0(g) 对1维向量和3阶方阵 D 1 ( g ) D_1(g) D1(g) 对 3 维向量的作用。
ρ ( g ) ( v 1 v 2 v 3 v 4 ) → ( v 1 ′ v 2 ′ v 3 ′ v 4 ′ ) ( D 0 ( g ) 0 0 D 1 ( g ) ) ( v 1 v 2 v 3 v 4 ) = ( D 0 ( g ) ( v 1 ) D 1 ( g ) ( v 2 v 3 v 4 ) ) = ( l 0 l 1 ) \begin{gathered} \rho(g)\left(\begin{array}{l} v_1 \\ v_2 \\ v_3 \\ v_4 \\ \end{array}\right) \rightarrow\left(\begin{array}{c} v_1^{\prime} \\ v_2^{\prime} \\ v_3^{\prime} \\ v_4^{\prime} \\ \end{array}\right) \\ \left(\begin{array}{cc} D_0(g) & 0 \\ 0 & D_1(g) \end{array}\right)\left(\begin{array}{l} v_1 \\ v_2 \\ v_3 \\ v_4 \\ \end{array}\right)=\left(\begin{array}{c} D_0(g)\left(\begin{array}{c} v_1 \\ \end{array}\right) \\ D_1(g)\left(\begin{array}{c} v_2 \\ v_3 \\ v_4 \end{array}\right) \end{array}\right)=\left(\begin{array}{c} l_0 \\ l_1 \end{array}\right) \end{gathered} ρ(g) v1v2v3v4 → v1′v2′v3′v4′ (D0(g)00D1(g)) v1v2v3v4 = D0(g)(v1)D1(g) v2v3v4 =(l0l1)
从而把高维的表示分解成低维的表示。
其中 l 0 l_0 l0称为type-0向量, l 1 l_1 l1称为type-1向量。
type-0向量在旋转下是不变的,type-1向量根据
3
D
3 \mathrm{D}
3D旋转矩阵旋转。注意,type-
J
J
J的向量长度为
2
J
+
1
2 J+1
2J+1。
在上一段中,我们提到了不可约群表示作用于正交子空间
X
0
,
X
1
,
…
\mathcal{X}_0, \mathcal{X}_1, \ldots
X0,X1,…。与Wigner-D矩阵对应的正交子空间是球谐空间。
4.6 The Spherical Harmonics
球谐函数
Y
J
:
S
2
→
C
2
J
+
1
Y_J:S^2\to C^{2J+1}
YJ:S2→C2J+1是球面
S
2
S^2
S2上的平方可积复值函数
Y
J
(
R
g
−
1
x
)
=
D
J
∗
(
g
)
Y
J
(
x
)
,
x
∈
S
2
,
g
∈
G
Y_J(R_g^{-1}x)=D_J^*(g)Y_J(x),x\in S^2,g\in G
YJ(Rg−1x)=DJ∗(g)YJ(x),x∈S2,g∈G
D
J
D_J
DJ是第
J
J
J个Wigner-D matrix,
D
J
∗
D_J^*
DJ∗是它的共轭
使用说明
球面坐标系的一点 P = ( θ , ϕ ) P=(\theta,\phi) P=(θ,ϕ),它的球谐函数值为 Y J ( P ) Y_J(P) YJ(P)。现在对 P P P施加一个旋转变换,假设旋转之后的坐标为 P ′ = ( θ ′ , ϕ ′ ) P^{\prime}=(\theta^{\prime},\phi{\prime}) P′=(θ′,ϕ′),那么它的球谐函数值为 Y J ( P ′ ) Y_J(P^{\prime}) YJ(P′),并且此时满足 Y J ( P ′ ) = D J ∗ ( g ) Y J ( P ) Y_J(P^{\prime})=D_J^*(g)Y_J(P) YJ(P′)=DJ∗(g)YJ(P)。说明在对原数据施加旋转变换后,它的球谐函数值相当于是原来的球谐函数值乘以一个 D J ∗ ( g ) D_J^*(g) DJ∗(g),这与我们构造一个等变权重 W W W的目标使一致的。
我们可以将
L
2
(
S
2
)
L^2(S^2)
L2(S2)中的任何函数表示为球面谐波的线性组合:
f
(
x
)
=
∑
J
⩾
0
f
J
T
Y
J
(
x
)
,
x
∈
S
2
f(x)=\sum_{J\geqslant0}f_J^TY_J(x),x\in S^2
f(x)=J⩾0∑fJTYJ(x),x∈S2
其中
f
J
f_J
fJ是长度为
2
J
+
1
2J+1
2J+1的系数,
f
J
=
∫
S
2
f
(
x
)
Y
J
∗
(
x
)
d
x
f_J=\int_{S^2}f(x)Y_J^*(x)dx
fJ=∫S2f(x)YJ∗(x)dx
与傅里叶变换相似, Y J Y_J YJ相当于 sin , cos \sin,\cos sin,cos, f J f_J fJ是系数
最重要的是,我们可以将旋转后的函数表示为:
f
(
ρ
(
g
)
−
1
x
)
=
∑
J
⩾
0
f
J
T
D
J
∗
(
g
)
Y
J
(
x
)
,
x
∈
S
2
,
g
∈
G
f(\rho(g)^{-1}x)=\sum_{J\geqslant0}f_J^TD^*_J(g)Y_J(x),x\in S^2,g\in G
f(ρ(g)−1x)=J⩾0∑fJTDJ∗(g)YJ(x),x∈S2,g∈G
4.7 The Clebsch-Gordan Decomposition
Clebsch-Gordan coefficients被用于构造等变核。
它研究的是两个不可约表示的张量积如何分解成不可约表示的直和
分解形式如下:
D
k
⨂
D
g
(
g
)
=
Q
l
k
T
[
⨁
J
=
∣
k
−
l
∣
k
+
l
D
J
(
g
)
]
Q
l
k
D_k \bigotimes D_g(g)={Q^{lk}}^{T}\left [\bigoplus_{J=|k-l|}^{k+l}D_J(g)\right]Q^{lk}
Dk⨂Dg(g)=QlkT
J=∣k−l∣⨁k+lDJ(g)
Qlk
在这个特定的情况下,基矩阵
Q
l
k
Q^{lk}
Qlk的变化被赋予Clebsch-Gordan系数的特殊名称
4.8 Tensor Field Layers
张量场网络(TFN)是一种神经网络,它在SE(3)等变性条件下将点云映射到点云。
对于点云,输入是矢量场
f
:
R
3
→
R
d
f:\mathbb{R}^3\to \mathbb{R}^d
f:R3→Rd,其形式为:
f
(
x
)
=
∑
j
=
1
N
f
j
δ
(
x
−
x
j
)
f(x)=\sum_{j=1}^Nf_j\delta(x-x_j)
f(x)=j=1∑Nfjδ(x−xj)
相当于 f ( x i ) = f i f(x_i)=f_i f(xi)=fi
式中
δ
\delta
δ 为Dirac函数,
{
x
j
}
\left\{\mathbf{x}_j\right\}
{xj} 为
3
D
3 \mathrm{D}
3D 点坐标,
{
f
j
}
\left\{f_j\right\}
{fj} 为点特征,且
f
j
f_j
fj由不同的tpye串联组成,
f
j
f_j
fj 的type-
ℓ
\ell
ℓ特征记为
f
j
ℓ
f_j^{\ell}
fjℓ
f
j
ℓ
f_j^{\ell}
fjℓ的长度为
2
l
+
1
2l+1
2l+1
假设 d = 4 d=4 d=4,则
f j = ( v 0 v 1 v 2 v 3 ) = ( f j 0 f j 1 ) f_j=\left(\begin{array}{c} v_0 \\ v_1 \\ v_2 \\ v_3 \\ \end{array}\right)=\left(\begin{array}{c} f_j^0 \\ f_j^1 \\ \end{array}\right) fj= v0v1v2v3 =(fj0fj1)
其中 f j 0 = ( v 0 ) , f j 1 = ( v 1 v 2 v 3 ) f_j^0=\left(v_0\right),f_j^1=\left(\begin{array}{c} v_1 \\ v_2 \\ v_3 \\ \end{array}\right) fj0=(v0),fj1= v1v2v3
从 k k k型特征到 ℓ \ell ℓ型特征的可学习的系数核为: W ℓ k : R 3 → R ( 2 ℓ + 1 ) × ( 2 k + 1 ) \mathbf{W}^{\ell k}: \mathbb{R}^3 \rightarrow \mathbb{R}^{(2 \ell+1) \times(2 k+1)} Wℓk:R3→R(2ℓ+1)×(2k+1)
记 f i n k ( x ) = ∑ j = 1 N f i n , j k δ ( x − x j ) f_{in}^k(x)=\sum_{j=1}^Nf_{in,j}^k\delta(x-x_j) fink(x)=∑j=1Nfin,jkδ(x−xj),现在对 f i n k ( x ) f_{in}^k(x) fink(x)和 W ℓ k ( x ) W^{\ell k}(x) Wℓk(x)求卷积:
f o u t , i ℓ = W ℓ k ( x i ) ⊗ f i n k ( x i ) = [ W ℓ k ∗ f i n k ] ( x i ) = ∫ R 3 W ℓ k ( x ′ − x i ) f i n k ( x ′ ) d x ′ = ∫ R 3 W ℓ k ( x ′ − x i ) ∑ j = 1 N f i n , j k δ ( x ′ − x j ) d x ′ = ∑ j = 1 N ∫ R 3 W ℓ k ( x ′ − x i ) f i n , j k δ ( x ′ − x j ) d x ′ = ∑ j = 1 N W ℓ k ( x j − x i ) f i n , j k \begin{aligned}f_{out,i}^{\ell} &=W^{\ell k}(x_i)\otimes f_{in}^k(x_i) \\ &=[W^{\ell k}* f_{in}^k ](x_i) \\ &=\int_{\mathbb{R}^3}W^{\ell k}(x^{\prime}-x_i)f_{in}^k(x^{\prime})dx^{\prime} \\ &=\int_{\mathbb{R}^3}W^{\ell k}(x^{\prime}-x_i)\sum_{j=1}^Nf_{in,j}^k\delta(x^{\prime}-x_j)dx^{\prime} \\ &=\sum_{j=1}^N\int_{\mathbb{R}^3}W^{\ell k}(x^{\prime}-x_i)f_{in,j}^k\delta(x^{\prime}-x_j)dx^{\prime} \\ &=\sum_{j=1}^NW^{\ell k}(x_j-x_i)f_{in,j}^k \end{aligned} fout,iℓ=Wℓk(xi)⊗fink(xi)=[Wℓk∗fink](xi)=∫R3Wℓk(x′−xi)fink(x′)dx′=∫R3Wℓk(x′−xi)j=1∑Nfin,jkδ(x′−xj)dx′=j=1∑N∫R3Wℓk(x′−xi)fin,jkδ(x′−xj)dx′=j=1∑NWℓk(xj−xi)fin,jk
其中 W ℓ k ( x ) ∈ R ( 2 ℓ + 1 ) × ( 2 k + 1 ) \mathbf{W}^{\ell k}(x)\in \mathbb{R}^{(2\ell +1)\times(2k+1)} Wℓk(x)∈R(2ℓ+1)×(2k+1), f i n , j k ∈ R ( 2 k + 1 ) f_{in,j}^k\in \mathbb{R}^{(2k+1)} fin,jk∈R(2k+1), f o u t , i ℓ ∈ R ( 2 ℓ + 1 ) f_{out,i}^{\ell}\in \mathbb{R}^{(2\ell+1)} fout,iℓ∈R(2ℓ+1)上述推导是在一层tpye- k k k上,实际上, f j f_j fj由不同的tpye串联组成
因此,张量场网络在 x i x_i xi处的type- ℓ \ell ℓ特征为:
f o u t , i ℓ = ∑ k ≥ 0 ∫ W ℓ k ( x ′ − x i ) f i n k ( x ′ ) d x ′ ⏟ k → ℓ convolution = ∑ k ≥ 0 ∑ j = 1 n W ℓ k ( x j − x i ) f i n , j k ⏟ node j → node i message , \mathbf{f}_{\mathrm{out}, i}^{\ell}=\sum_{k \geq 0} \underbrace{\int \mathbf{W}^{\ell k}\left(\mathbf{x}^{\prime}-\mathbf{x}_i\right) \mathbf{f}_{\mathrm{in}}^k\left(\mathbf{x}^{\prime}\right) \mathrm{d} \mathbf{x}^{\prime}}_{k \rightarrow \ell \text { convolution }}=\sum_{k \geq 0} \sum_{j=1}^n \underbrace{\mathbf{W}^{\ell k}\left(\mathbf{x}_j-\mathbf{x}_i\right) \mathbf{f}_{\mathrm{in}, j}^k}_{\text {node } j \rightarrow \text { node } i \text { message }}, fout,iℓ=k≥0∑k→ℓ convolution ∫Wℓk(x′−xi)fink(x′)dx′=k≥0∑j=1∑nnode j→ node i message Wℓk(xj−xi)fin,jk,
接下来,继续在一层tpye-
k
k
k基础上继续推导,求出
W
ℓ
k
(
x
)
W^{\ell k}(x)
Wℓk(x)的表示。
现在,对
f
o
u
t
,
i
ℓ
=
∑
j
=
1
N
W
ℓ
k
(
x
j
−
x
i
)
f
i
n
,
j
k
f_{out,i}^{\ell} =\sum_{j=1}^NW^{\ell k}(x_j-x_i)f_{in,j}^k
fout,iℓ=∑j=1NWℓk(xj−xi)fin,jk施加等变约束:
D
ℓ
(
g
)
f
o
u
t
,
i
ℓ
=
∑
j
=
1
N
W
ℓ
k
(
R
g
−
1
(
x
j
−
x
i
)
)
D
k
(
g
)
f
i
n
,
j
k
D_{\ell}(g)f_{out,i}^{\ell}=\sum_{j=1}^NW^{\ell k}(R_g^{-1}(x_j-x_i))D_k(g)f_{in,j}^k
Dℓ(g)fout,iℓ=j=1∑NWℓk(Rg−1(xj−xi))Dk(g)fin,jk
解释:如果原点云发生了旋转,tpye- ℓ \ell ℓ只需要乘以一个Wigner-D矩阵:
f ℓ ↦ D ℓ ( g ) f ℓ f_{\ell} \mapsto D_{\ell}(g)f_{\ell} fℓ↦Dℓ(g)fℓ
⇒ f o u t , i ℓ = ∑ j = 1 N D ℓ ( g ) − 1 W ℓ k ( R g − 1 ( x j − x i ) ) D k ( g ) f i n , j k \Rightarrow f_{out,i}^{\ell}=\sum_{j=1}^ND_{\ell}(g)^{-1}W^{\ell k}(R_g^{-1}(x_j-x_i))D_k(g)f_{in,j}^k ⇒fout,iℓ=j=1∑NDℓ(g)−1Wℓk(Rg−1(xj−xi))Dk(g)fin,jk
⇒ W ℓ k ( R g − 1 x ) = D ℓ ( g ) W ℓ k ( x ) D k ( g ) − 1 \Rightarrow W^{\ell k}(R_g^{-1}x)=D_{\ell}(g)W^{\ell k}(x)D_k(g)^{-1} ⇒Wℓk(Rg−1x)=Dℓ(g)Wℓk(x)Dk(g)−1
使用公式 v e c ( A X B ) = ( B T ⊗ A ) v e c ( X ) vec(AXB)=(B^T\otimes A)vec(X) vec(AXB)=(BT⊗A)vec(X)
⇒ v e c ( W ℓ k ( R g − 1 x ) ) = ( D k ( g ) ⊗ D ℓ ( g ) ) v e c ( W ℓ k ( x ) ) \Rightarrow vec(W^{\ell k}(R_g^{-1}x))=(D_k(g)\otimes D_{\ell}(g))vec(W^{\ell k}(x)) ⇒vec(Wℓk(Rg−1x))=(Dk(g)⊗Dℓ(g))vec(Wℓk(x))
由于 D k ⨂ D g ( g ) = Q l k T [ ⨁ J = ∣ k − l ∣ k + l D J ( g ) ] Q l k D_k \bigotimes D_g(g)={Q^{lk}}^{T}\left [\bigoplus_{J=|k-l|}^{k+l}D_J(g)\right]Q^{lk} Dk⨂Dg(g)=QlkT J=∣k−l∣⨁k+lDJ(g) Qlk
⇒ v e c ( W ℓ k ( R g − 1 x ) ) = Q l k T [ ⨁ J = ∣ k − l ∣ k + l D J ( g ) ] Q l k v e c ( W ℓ k ( x ) ) \Rightarrow vec(W^{\ell k}(R_g^{-1}x))={Q^{lk}}^{T}\left [\bigoplus_{J=|k-l|}^{k+l}D_J(g)\right]Q^{lk}vec(W^{\ell k}(x)) ⇒vec(Wℓk(Rg−1x))=QlkT J=∣k−l∣⨁k+lDJ(g) Qlkvec(Wℓk(x))
令 η l k ( x ) ≜ Q l k v e c ( W l k ( x ) ) \eta^{lk}(x)\triangleq Q^{lk}vec(W^{lk}(x)) ηlk(x)≜Qlkvec(Wlk(x))
⇒ η l k ( R g − 1 x ) = [ ⨁ J = ∣ k − l ∣ k + l D J ( g ) ] η l k ( x ) \Rightarrow \eta^{lk}(R_g^{-1}x)=\left [\bigoplus_{J=|k-l|}^{k+l}D_J(g)\right]\eta^{lk}(x) ⇒ηlk(Rg−1x)= J=∣k−l∣⨁k+lDJ(g) ηlk(x)
因此 η l k ( R g − 1 x ) \eta^{lk}(R_g^{-1}x) ηlk(Rg−1x)的第 J J J个向量 η J l k ( R g − 1 x ) \eta^{lk}_J(R_g^{-1}x) ηJlk(Rg−1x)受到约束:
η J l k ( R g − 1 x ) = D J ( g ) η J l k ( x ) \eta^{lk}_J(R_g^{-1}x)=D_J(g)\eta^{lk}_J(x) ηJlk(Rg−1x)=DJ(g)ηJlk(x)
这正是的球谐波的变换定律:
Y J ( R g − 1 x ) = D J ∗ ( g ) Y J ( x ) , x ∈ S 2 , g ∈ G Y_J(R_g^{-1}x)=D_J^*(g)Y_J(x),x\in S^2,g\in G YJ(Rg−1x)=DJ∗(g)YJ(x),x∈S2,g∈G
D J D_J DJ是第 J J J个Wigner-D matrix, D J ∗ D_J^* DJ∗是它的共轭
因此,
W
l
k
(
x
)
W^{lk}(x)
Wlk(x)可以被构造为:
v
e
c
⟮
W
l
k
(
x
)
⟯
=
Q
l
k
T
⨁
J
=
∣
k
−
l
∣
k
+
l
Y
J
(
x
)
vec\lgroup W^{lk}(x)\rgroup={Q^{lk}}^{T}\bigoplus_{J=|k-l|}^{k+l}Y_J(x)
vec⟮Wlk(x)⟯=QlkTJ=∣k−l∣⨁k+lYJ(x)
4.9 再次理解Tensor Field Layers
f
o
u
t
,
i
ℓ
=
∑
k
≥
0
∑
j
=
1
n
W
ℓ
k
(
x
j
−
x
i
)
f
i
n
,
j
k
⏟
node
j
→
node
i
message
\mathbf{f}_{\mathrm{out}, i}^{\ell}=\sum_{k \geq 0} \sum_{j=1}^n \underbrace{\mathbf{W}^{\ell k}\left(\mathbf{x}_j-\mathbf{x}_i\right) \mathbf{f}_{\mathrm{in}, j}^k}_{\text {node } j \rightarrow \text { node } i \text { message }}
fout,iℓ=k≥0∑j=1∑nnode j→ node i message
Wℓk(xj−xi)fin,jk
假设
f
i
n
=
f
i
n
0
f_{in}=f_{in}^0
fin=fin0,并且有:
f
i
n
0
↦
f
o
u
t
0
f_{in}^0 \mapsto f_{out}^0
fin0↦fout0
f
i
n
0
↦
f
o
u
t
1
f_{in}^0 \mapsto f_{out}^1
fin0↦fout1
现在加上self-interaction
f
o
u
t
,
i
ℓ
=
w
ℓ
ℓ
f
i
n
,
i
ℓ
⏟
self-interaction
+
∑
k
≥
0
∑
j
=
1
n
W
ℓ
k
(
x
j
−
x
i
)
f
i
n
,
j
k
⏟
node
j
→
node
i
message
\mathbf{f}_{\mathrm{out}, i}^{\ell}=\underbrace{\mathcal{w}^{\ell \ell}f_{in,i}^{\ell}}_{\text{self-interaction}}+\sum_{k \geq 0} \sum_{j=1}^n \underbrace{\mathbf{W}^{\ell k}\left(\mathbf{x}_j-\mathbf{x}_i\right) \mathbf{f}_{\mathrm{in}, j}^k}_{\text {node } j \rightarrow \text { node } i \text { message }}
fout,iℓ=self-interaction
wℓℓfin,iℓ+k≥0∑j=1∑nnode j→ node i message
Wℓk(xj−xi)fin,jk
只有 k = l 时才有 s e l f − i n t e r a c t i o n k=l时才有self-interaction k=l时才有self−interaction

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









