







提升
随机森林的决策树分别采样建立,相对独立。
- 是否能够利用之前的决策树来有益影响下一棵决策树的建立呢?
- 投票过程是否可以在建立决策树时就确定呢?
提升:
可以用于回归和分类问题。每一步产生一个弱分类器(如决策树)并加权累加到总模型中,得到强分类器。
梯度提升(Gradient boosting):
每一步弱预测模型都是根据损失函数的梯度方向。
弱分类器到强分类器
- 样本加权
上一次错分的样本,下一次得到更高的权值 - 分类器加权
提升算法
给定输入向量x,和输出变量y,找到近似函数F(x),使得损失函数L(y,F(x))的损失值最小。
L(y,F(x)) 一般定义为:
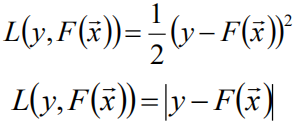
假设最优函数:
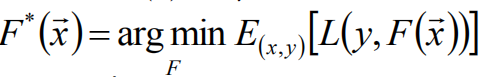
如果这里采取的L是绝对值|y-F(x)|:
最优解μ* = arg minΣ|x-μ|
如果把样本递增排序,则J(μ)=Σ|x-μ|=Σ(x-μ)+Σ(μ-x)
对J求偏导为Σ(1)+Σ(-1) = 0,意味着前k个样本数目与后n-k个样本数目相同,则μ为中位数。
如果这里是L是MSE,则μ为均值。
对目标函数F(x)分解成若干基函数f(x)的加权和
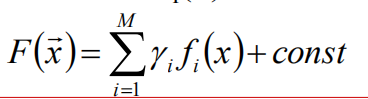
提升算法推导
目标:梯度提升方法寻找最优解F(x)使损失函数在训练集上期望最小。
我们可以先得到常函数F0(x),以贪心的思路扩展得到Fm(x)。(后一个可以根据前一个得出)
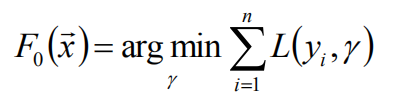
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









