







1. 卷积
卷积(Convolutional):卷积在图像处理领域被广泛的应用,像滤波、边缘检测、图片锐化等,都是通过不同的卷积核来实现的。在卷积神经网络中通过卷积操作可以提取图片中的特征,低层的卷积层可以提取到图片的一些边缘、线条、角等特征,高层的卷积能够从低层的卷积层中学到更复杂的特征,从而实现到图片的分类和识别。

2. 反卷积
反卷积:反卷积也被称为转置卷积,反卷积其实就是卷积的逆过程。大家可能对于反卷积的认识有一个误区,以为通过反卷积就可以获取到经过卷积之前的图片,实际上通过反卷积操作并不能还原出卷积之前的图片,只能还原出卷积之前图片的尺寸。通常卷积神经网络无非是卷积+池化的堆叠,池化过程必定存在部分信息被丢弃的问题,且容易造成小物体信息无法重建等问题。比如连续4个2 * 2大小的pooling之后,任何小于
2
4
2^4
24大小的图片都无法被重建。
反卷积的作用主要体现在三个方面:
- unsupervised learning :重构图像
- CNN可视化:将conv得到的feature map还原到像素空间,观察特定的feature map对应原始图片的哪些区域
- upsampling:上采样
卷积的意义在于从输入图像中提取特征,并且卷积之后因为pooling的存在使得特征图尺寸越来越小。卷积过程中,一般特征图的尺寸会越来越小(特征图个数会增加),而反卷积过程中,一般输入尺寸较小,而输出尺寸相对要大。

举个例子:
对于4*4大小的输入,kernel_size=3 * 3,padding=0,stride =0,则输出大小为尺寸2 * 2的特征图。 将输入展开为16 * 1的向量,记做 X X X;输出的特征图展开得到4 * 1的向量,记做 Y Y Y,如何刻画由A到B的转化C呢??
这样刻画:
C
1
X
=
Y
C_1X=Y
C1X=Y这个
C
1
C_1
C1就代表卷积操作,根据矩阵乘法可得:
C
1
C_1
C1的尺寸为4 * 16。也就是
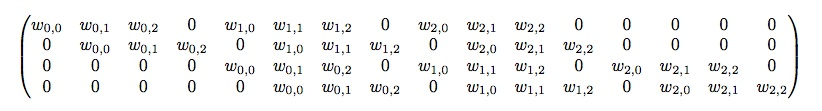
而反卷积是什么了?
同样举上面的例子,假设输入 X X X为2 * 2(4 * 1的向量),经过反卷积之后得到大小为4 * 4(向量大小为16 * 1)的输出 Y Y Y,那么反卷积过程可以描述为:
Y = C 2 T X Y=C_2^TX Y=C2TX
其中 C 2 C_2 C2的尺寸为4 * 16。对比两个公式,以及最后中间变换过程可得知,C1与C2是同一矩阵,卷积与反卷积的差异在于整个过程中是否转置。
3. casual conv
什么叫因果卷积呢?就是$ t$时刻的输出仅仅依赖于{ 1 , 2 , 3 , . . . , t − 1 , t 1,2,3,...,t-1,t 1,2,3,...,t−1,t}时刻的输入,如下图:

但是可以看到的是,输出的感受野仅仅是5=(#layers+kernel_length-1),这一点使得如果需要考虑很久之前的信息,那么就要求整个网络的深度增加,随之而来的是计算开销、梯度消失、训练复杂等问题。所以有下面的Dilated CONV。
4. dilated conv
膨胀卷积、带洞卷积的作用在于,不增加参数和模型复杂度的前提下,指数倍的扩大感受野大小。通过更大的dilation膨胀因子可以使得最高层能够利用输入层中更大范围的信息。
要如何理解dilated conv呢??

图a代表3x3大小的1-dilated conv,卷积过程与普通卷积一致
图b代表3x3大小的2-dilated conv,实际上可以理解为7x7大小的patch,但是仅仅有其中标识红点的9个点与3x3大小的卷积核进行内积操作。也可以理解为kernel_size=7x7
图c代表3x3大小的4-dilated conv,可理解为15x15大小的patch,但是仅仅有其中标识红点的9个点与3x3大小的卷积核进行内积操作。
空洞卷积的目的在于:模型层数不增加的前提下,最后一层能够获得更大的感受野!
打个比方:
一般的卷积经过三层大小为3x3的kernel后,顶层获得的感受野大小为7x7。(这里不考虑卷积后的pooling,因为pooling会按pooling大小扩大感受野)
而在空洞卷积中,顶层获得的感受野是以指数递增的。怎么理解呢???
假设三层dilated-conv,kernel_size大小均为3x3,膨胀系数分别为1,2,4,每一层可获得的感受野大小可以用如下公式计算:
计算实际的kernel_size:(n-1)*(k+1)+k,n是膨胀系数。
计算可获得的感受野大小:
F
i
+
1
=
(
2
i
+
2
−
1
)
∗
(
2
i
+
2
−
1
)
F_{i+1}=(2^{i+2}-1) *( 2^{i+2}-1)
Fi+1=(2i+2−1)∗(2i+2−1),这个公式来源于论文multi-scale context aggregation by dilated convolutions
按上述的公式计算:
第一层:n=1,k=3,实际的kernel大小为:(1-1)x(3+1)+3=3,证实膨胀系数为1的膨胀卷积等价于一般的卷积操作。
第二层:n=2,k=3,实际的kernel大小为:(2-1)x(3+1)+3=7,实际卷积核大小为7x7
第三层:n=4,k=3,实际的kernel大小为:(4-1)x(3+1)+3=15,实际卷积核大小为15x15
注意到上面:
第一层的感受野为:
F
1
=
F
1
+
0
=
(
2
0
+
2
−
1
)
∗
(
2
0
+
2
−
1
)
=
3
∗
3
F_1=F_{1+0}=(2^{0+2}-1)*(2^{0+2}-1)=3 * 3
F1=F1+0=(20+2−1)∗(20+2−1)=3∗3
第二层的感受野为:
F
2
=
F
1
+
1
=
(
2
1
+
2
−
1
)
∗
(
2
1
+
2
−
1
)
=
7
∗
7
F_2=F_{1+1}=(2^{1+2}-1)*(2^{1+2}-1)=7 * 7
F2=F1+1=(21+2−1)∗(21+2−1)=7∗7
第三层的感受野为:
F
3
=
F
1
+
2
=
(
2
2
+
2
−
1
)
∗
(
2
2
+
2
−
1
)
=
15
∗
15
F_3=F_{1+2}=(2^{2+2}-1)*(2^{2+2}-1)=15 * 15
F3=F1+2=(22+2−1)∗(22+2−1)=15∗15
观察到貌似该层的实际的卷积核大小等于其感受野大小!但是不能把这个当做结论,因为通常来说,卷积之后会有池化,根据池化层的size扩大感受野!!

5.dilated conv改进
空洞卷积存在它自身的问题:
- The Gridding effect: dilated rate =2 多次叠加的话,kernel并不连续,也即并不是所有的像素点都用来计算了。这对于pixel-level dense prediction任务而言,是致命的。
- Long-ranged information might be not relevant. 仅采用大的dilation rate或许仅仅对一些大物体分割有效,对小物体分割可能效果并不好。
改进方式请参见简书中关于dilated conv的改进
参考文献:















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









