






Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Abstract
Challenge: 最近的文本到视频生成方法依赖于计算量大的训练,并且需要大规模的视频数据集。
Motivation: 介绍了一种新的零镜头文本到视频生成任务,并通过利用现有文本到图像合成方法(例如稳定扩散)的力量,提出了一种低成本的方法(无需任何训练或优化),使其适用于视频领域。
- 能够生成即便有运动动力学的帧,保持全局场景和背景时间的一致。
- 使用第一帧上的每个帧的新跨注意力重新编程帧级自注意力,保持前景对象的上下文、外观和身份。
code:https://github.com/PicsartAI-Research/Text2Video-Zero.
contribution: - 利用运动信息丰富生成帧的潜在代码,保证全局场景于背景时间的一致性,在每一帧上使用注意力机制。
- 实现零样本的视频生成和编辑,只使用了与训练的文本到图像的扩散模型(stable diffusion),没有进行如何的微调和优化
Method
Stable diffusion
利用SD生成latent code图像在latent space上的特征
Zero-shot
首先使用SD获得latent code,利用运动动力学则增强确定背景以及全局背景时间上的一致性,在利用ddpm的前向传播获得latent code,最后根据跨帧注意力机制保留下图像中前景对象的外观特征,可以选择使用背景平滑,过滤出前景对象特征
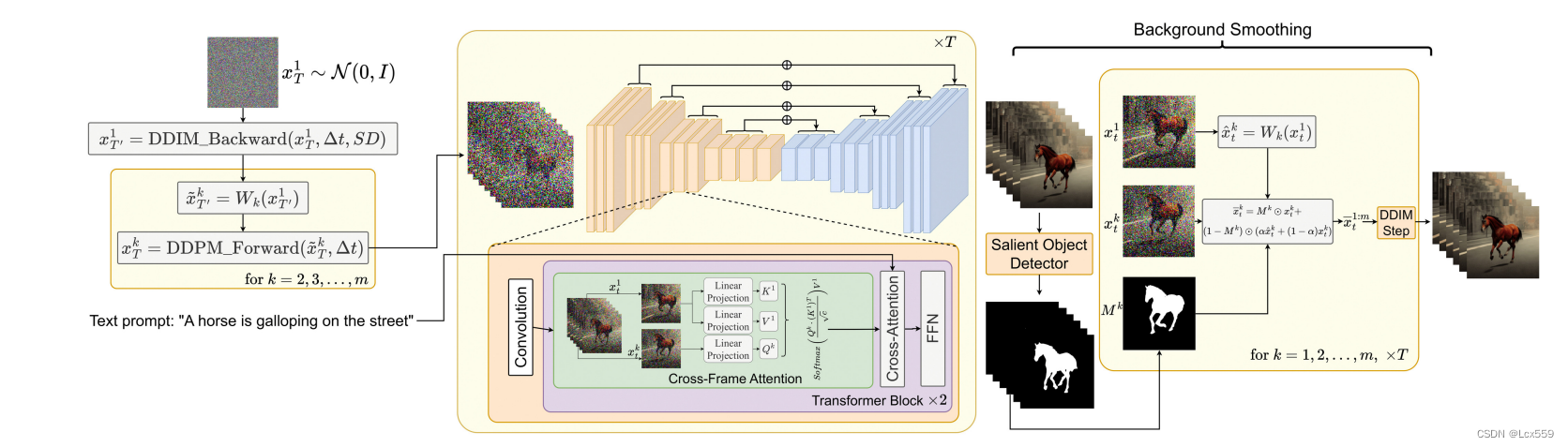
attention
使用跨帧注意力机制来在整个生成的视频中保留关于(特别是)前景对象的外观、形状和身份的信息。将注意力都放在第一帧上。















 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









