






Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Abstract
首先在图像数据集上训练LDM,同时将时间维度引入latent space,并对编码的图像序列进行微调,从而健图像生成器转变为视频生成器。
project web:https://nv-tlabs.github.io/VideoLDM/
motivation: 高分辨率真实单词驾驶数据视频合成;创意内容生成的文本引导视频合成
在LDMs基础上提出,将LDM扩展到高分辨率视频生成。
通过将时间维度引入潜在空间,在编码的图像序列上训练这些时间层,同时固定预先训练的空间层。
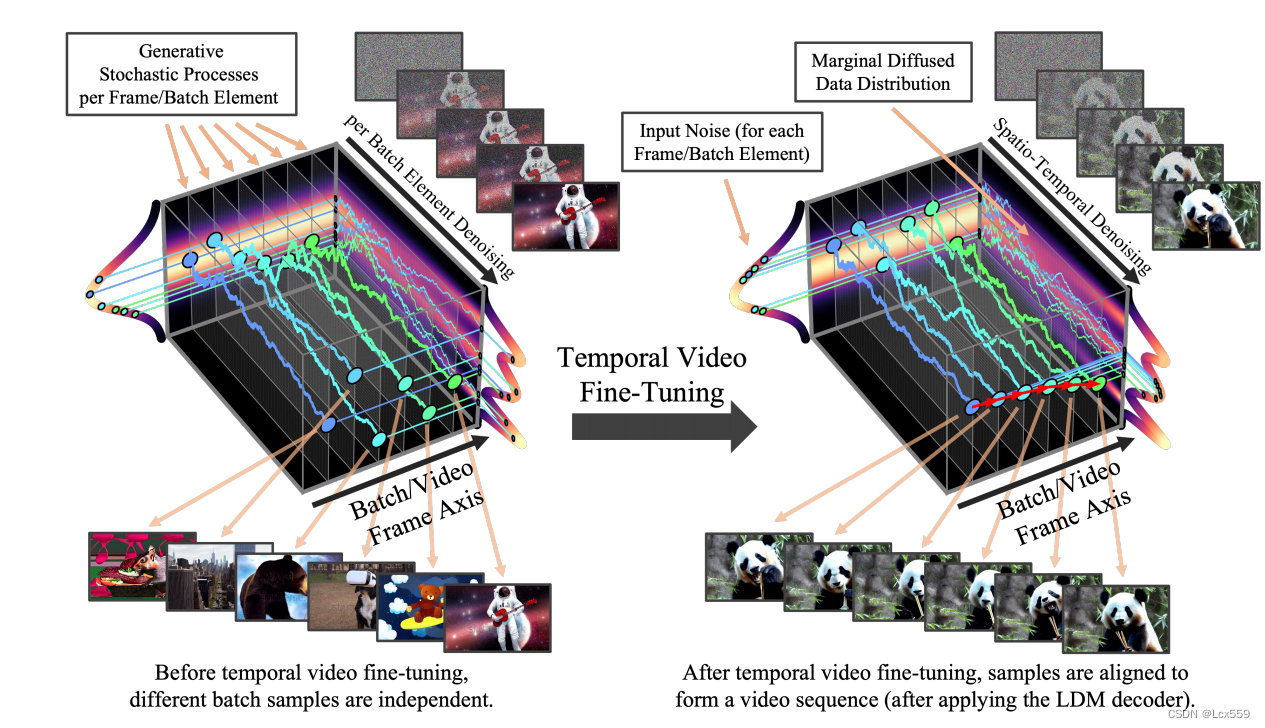
引入时间微调前,生成视频中的图片是独立的,引入微调之后生成的图片便是视频序列。
通过微调解码器实现空间中时间的一致性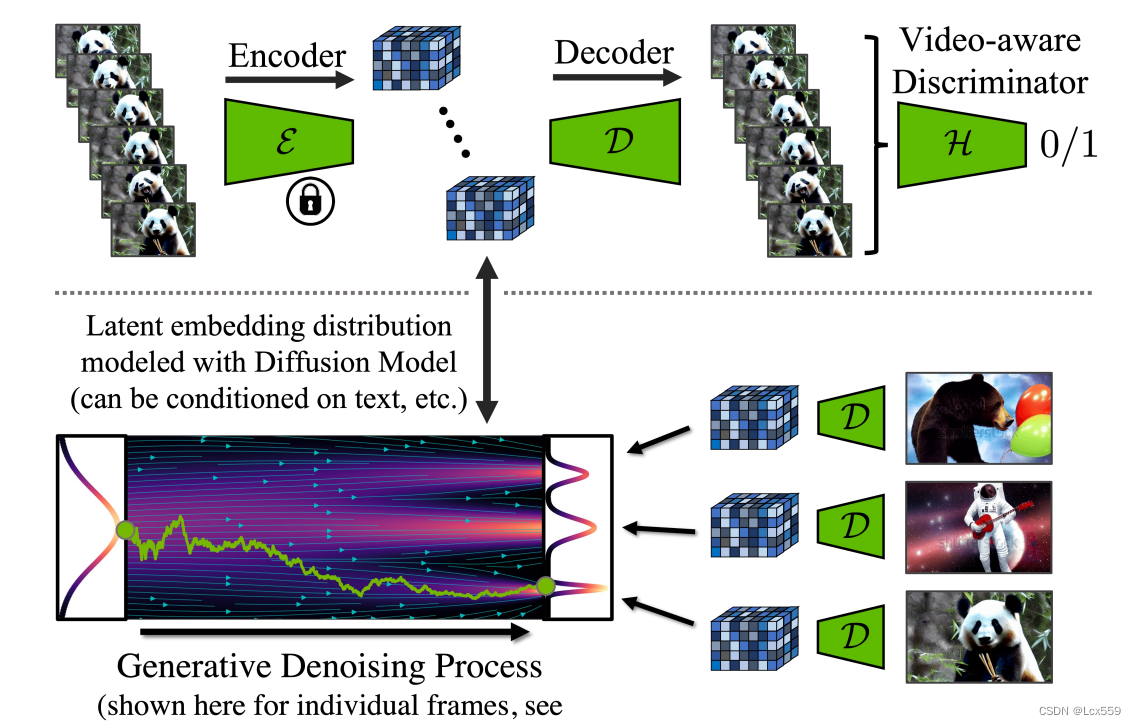
contribution:
- 提出一种有效的方法基于LDM实现高分辨率、长期一直的视频生成模型,在预训练的diffusion model中插入时间层将其转化为视频生成器。
- 对超分辨率diffusion和时间进行微调
- 在真实驾驶场景视频上实现了最先进的高分辨率视频合成性能
Method
Turning Latent Image into Video Generators
通过引入额外的时间神经网络层,与现有的空间层交错,学习时间一致额方式对齐各个帧。
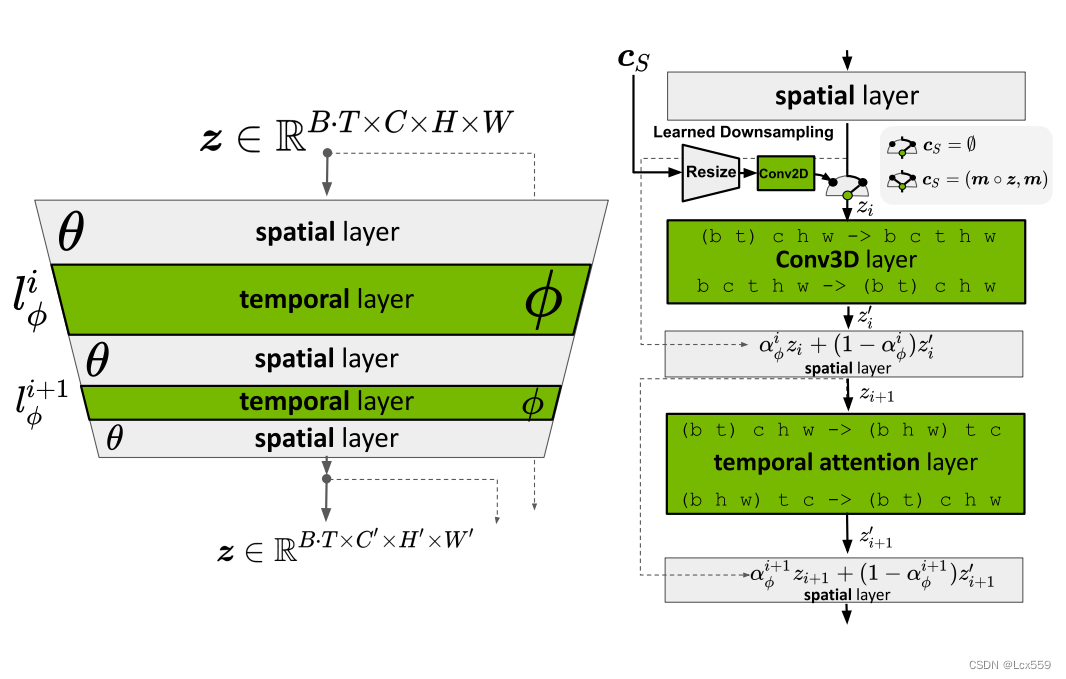
左图中,将帧对齐到时间一致序列的时间层,将与训练的LDM变为视频生成器。右图中,模型θ将输入的序列解释为一批图像,利用时间层将图像整形为视频格式。(类残差设计)
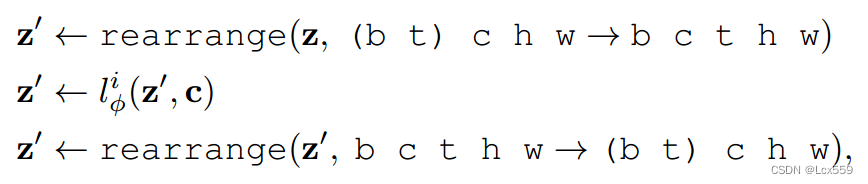
简而言之,空间层是对每个视频帧独立处理,而时间层是在整个时间维度T中处理整个视频。
长视频生成
上述方法对于短视频的生成时有效的,但是对于超长视频生成却无能为力。
Framework: 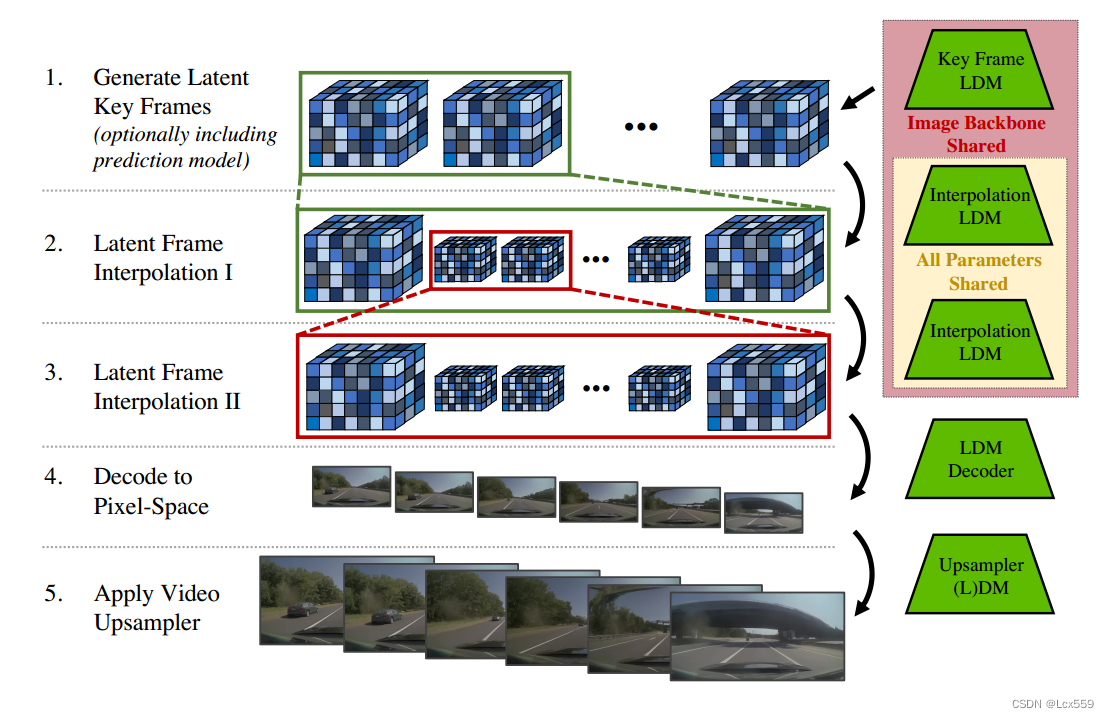















 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









